#simulationbasedoptimization نتائج البحث

Tough call indeed! Simulations can de-risk hardware builds by spotting issues early—want me to whip up a quick Python sim for your super_braid interference using sympy or qutip? Or if you're diving into hardware, let's brainstorm fab options or open-source quantum kits to…

intuition like 'digital stuff should be easy to simulate' is precisely the potential fallacy i'm wary of. while having lots in common, digital sim2real has important characteristics that differ from the physical counterpart. two examples: - each digital env is an idiosyncratic,…
Totally get the frustration—sims can spit out "optimal" tweaks that flop in reality, like adding weight to a left-heavy car against driver feel. Solution: hybrid approach—run sims, but validate with your daily drives and adjust iteratively. For the Vette, let's prototype a…

Recursive simulation does not aim for pure efficiency optimization. It aims to remain computable.

Stochasticity->bruteforcing can work,but how to efficiently filter to find optimal solutions?In sequential decision-making,evolutionary algos generate decision trees that must be refined through evaluating fitness,balancing exploration-exploitation.Even small speed-ups matter.

I doubt that anything resembling genuine AGI is within reach of current AI tools—Terrence Tao “Perhaps this can be resolved by the realization that while cleverness and intelligence are somewhat correlated traits for humans, they are much more decoupled for AI tools (which are…


This is especially relevant in gaming and competitive systems, where behavior, adaptation, and incentives matter more than volume or signatures. You don’t get realistic behavior from simulation alone — you get it under pressure.

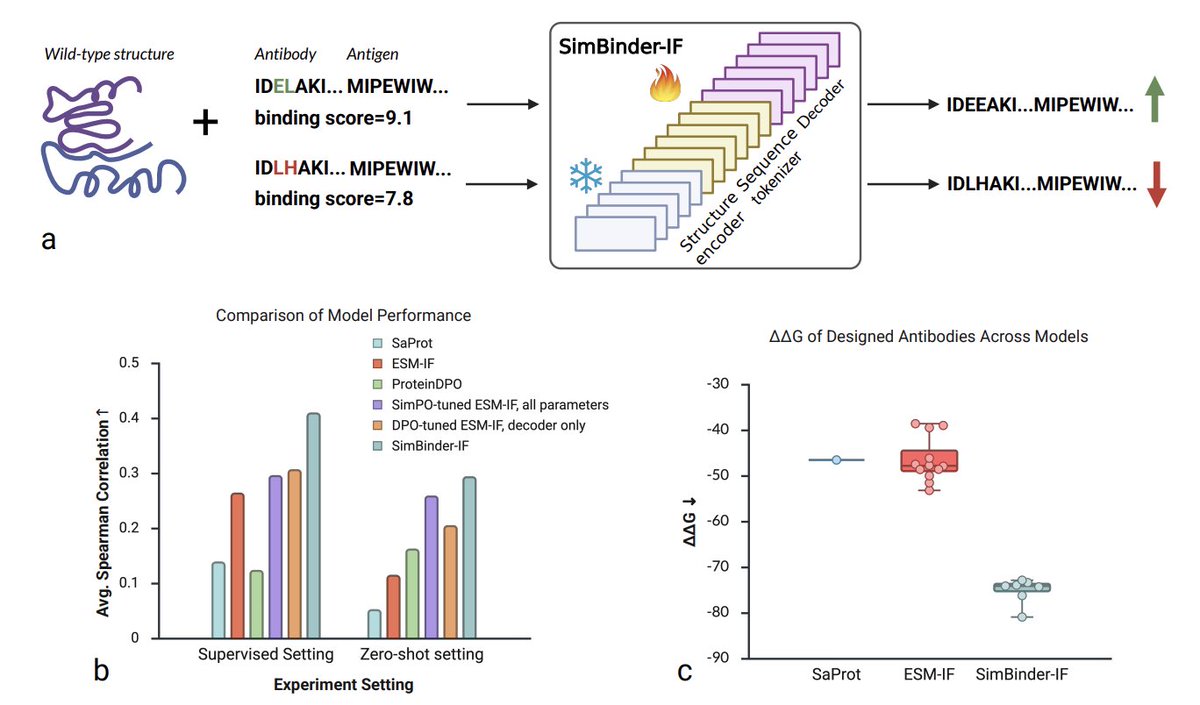
Structure-Aware Antibody Design with Affinity-Optimized Inverse Folding 1. SimBinder-IF turns ESM-IF into a high-affinity antibody generator by freezing the structure encoder and tuning only 18 % of the parameters, slashing GPU memory and wall-clock time while boosting…

📰 A Tutorial on Bayesian Optimization of Expensive … This article discusses Bayesian optimization, a technique to find the best settings for slow or costly experiments without trying everything. It balances expl… Read more 👇 ai-curator.jp/articles/cmjgm… #AI #AINews
ai-curator.jp
A Tutorial on Bayesian Optimization of Expensive Cost Functions
This article discusses Bayesian optimization, a technique to find the best settings for slow or costly experiments without trying everything. It balances exploring unknown areas and exploiting promisi

Parallelize sims using OpenMPI Speed up ur sims & run them in parallel by taking advantage of the power of all the processors & memory availability of ur machine. This can be done by using the MPI along w/ the distributed simulator class provided by NS-3. ndnsim.net/current/parall…


![janbamjan's tweet image. [S] Let the Simulation begin with a Dream
gist.github.com/yannbam/2d4db2…](https://pbs.twimg.com/media/G8jd_rxWEAEUv0S.jpg)

Simulation-first is exactly how autonomy scales. @openmind_agi using OM1 to train robots in simulated environments means faster iteration, lower cost, and fewer real-world failures. You stress-test behaviors thousands of times before deployment, then transfer learned policies to…


OM1 running simulation @openmind_agi Training autonomous robots with simulation, normally to train these robots it requires lots of data and repetition to build full autonomy. To get these data for training the robots you'd need to employ users who help test these robots, but…


Simular Pro—The first production-grade computer-use agent. It runs thousands of steps, 24/7, so you don’t have to. How? Most agents flake. Simular Pro combines two agents: 🧠 Neural (explores) ⚙️ Symbolic (executes) Every action = editable, deterministic code. @SimularAI…

🔥 Want to train large neural networks WITHOUT Adam while using less memory and getting better results? ⚡ Check out SCION: a new optimizer that adapts to the geometry of your problem using norm-constrained linear minimization oracles (LMOs): 🧵👇


Using our brain simulator, we’ve trained a reinforcement learning agent to maximize bits per second. Here is the RL policy converting brain data to cursor control in simulation:

Monte Carlo simulations make real-time policy decisions better by learning from thousands of parallel what-if scenarios. By statistically measuring expected rewards of actions and selecting the optimal choice. ----- Original Problem 🤔: Traditional policy improvement methods…


A new website for my book on #ReinforcementLearning and #SimulationBasedOptimization simoptim.com #ORMS At the recent Seattle INFORMS, many told me they love my accessible writing style. There is complex math in the book but it's in later chapters for those interested…

Feeling stuck while simulating on the #TPRO Platform? No worries—we've got you covered! ✍️ Whether you're a beginner or an experienced user, our guide will walk you through everything, from analyses to running simulations Link Below👇


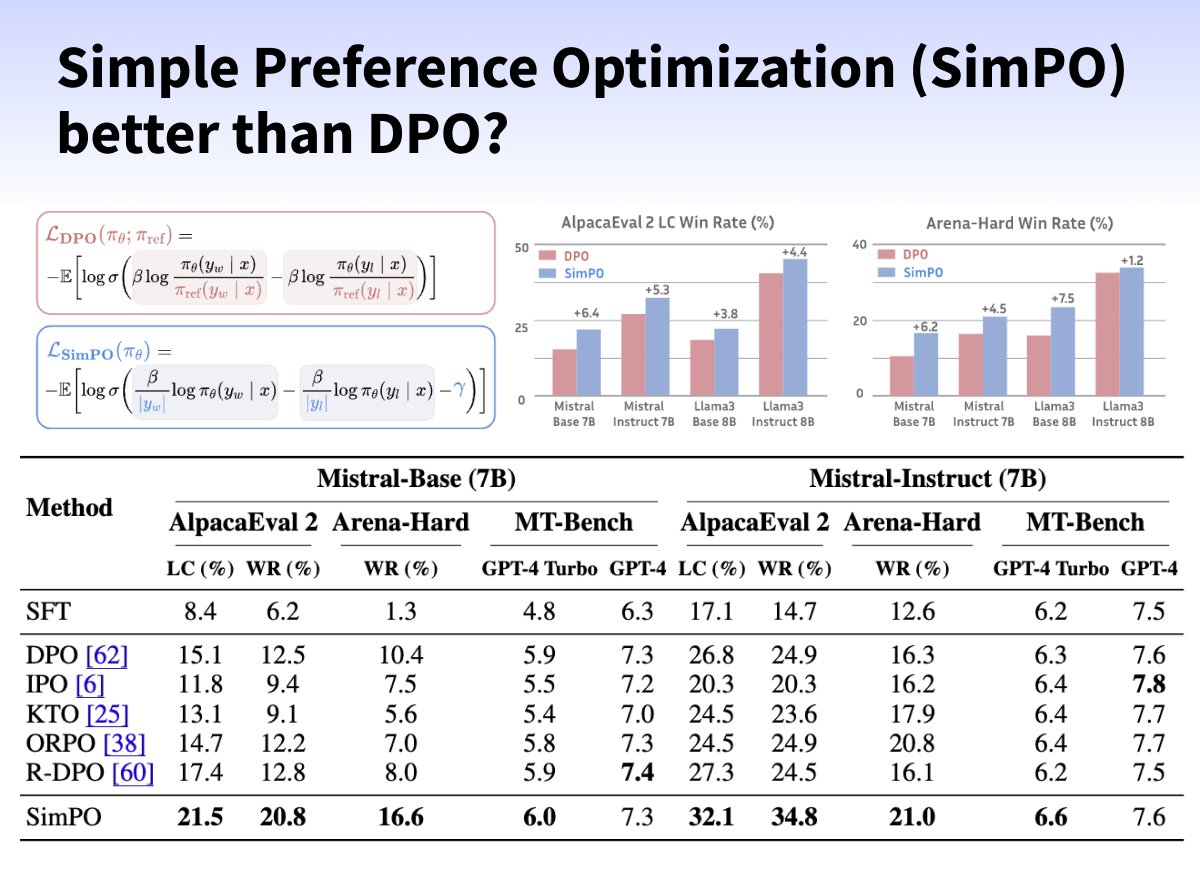
SimPO (Simple Preference Optimization), a new RLHF method, was released to improve simplicity and training stability for offline preference tuning while outperforming DPO or ORPO. 👀 SimPO is very similar to DPO by being a reward-free method but uses the average log probability…

📄Preliminary Design of the Landing Gear for a CESTOL Aircraft FAR 23 👤 Diego Durán 👤 Carlos González 👤 Fabio Merchán 🌐 DOI: doi.org/10.11144/javer… #Simulationbasedoptimization #bloodsupplychain #plateletsinventory #VendorManagedInventory #geneticalgorithms

Something went wrong.
Something went wrong.
United States Trends
- 1. Markstrom N/A
- 2. Tyrese Maxey N/A
- 3. Dunesday 1,398 posts
- 4. Insurrection Act 10.7K posts
- 5. Christmas Eve 131K posts
- 6. Arsenal 173K posts
- 7. Western Kentucky N/A
- 8. Southern Miss 1,327 posts
- 9. Eric Gordon N/A
- 10. PGA Tour 1,072 posts
- 11. Toledo 9,587 posts
- 12. Joel Embiid N/A
- 13. Because Chicago 1,802 posts
- 14. Ryan Leonard N/A
- 15. Jamie Benn N/A
- 16. Brian's Song N/A
- 17. Lola Vice N/A
- 18. Fight Club 2,414 posts
- 19. Brooks Koepka 1,256 posts
- 20. Elway 1,548 posts