#sparkstructuredstreaming search results

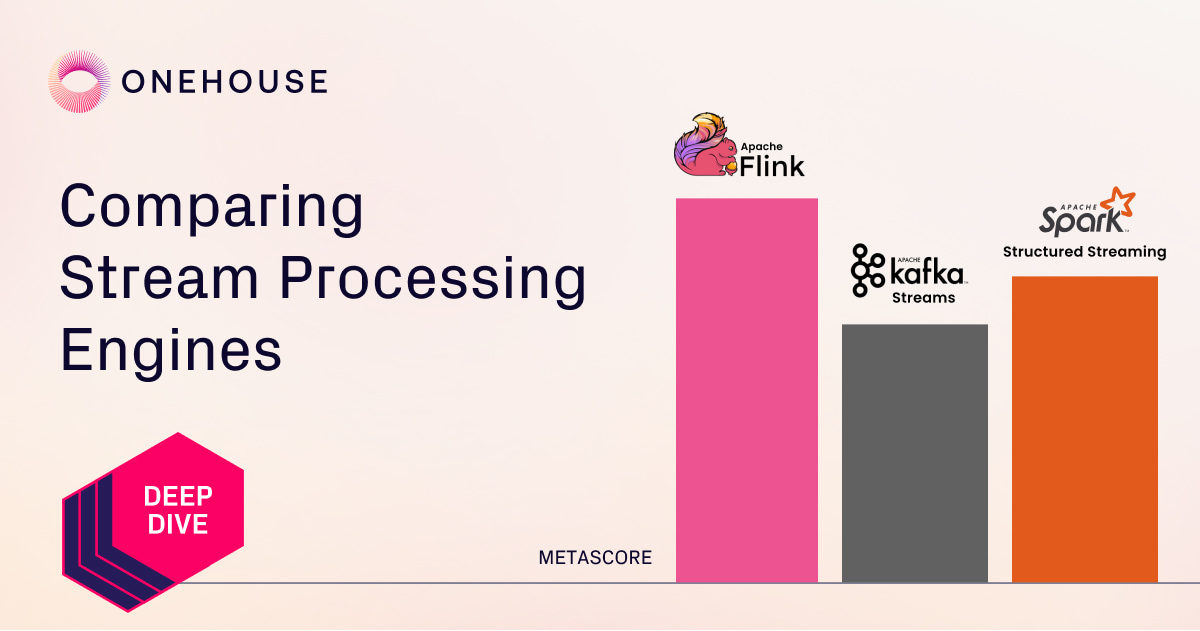
Trying to pick the right streaming engine? Check out our no-fluff breakdown of @ApacheFlink , #KafkaStreams, and #SparkStructuredStreaming Spoiler: they all rock… but in very different ways. 👉 onehouse.ai/blog/apache-sp… #dataengineering #streaming #opensource #realtimedata…

Join Sharon Xie and Eric Xiao as they share their journey at @Decodableco, including choosing #ApacheFlink over #SparkStructuredStreaming for #streamdataprocessing. Save your spot for #FlinkForward Berlin: hubs.li/Q02H_N850


Join Sharon Xie and Eric Xiao as they share their journey at @Decodableco, including choosing #ApacheFlink over #SparkStructuredStreaming for #streamdataprocessing. Save your spot for #FlinkForward Berlin: hubs.li/Q02H_Ngw0


Zapowiada się kolejny świetny meetup od @jaceklaskowski meetup.com/warsaw-data-en… #spark #sparkstructuredstreaming #bigdata #apachespark

Pyspark Structured Streaming - Unable to perform mutiple aggregations - Need an alternative to aggregation functions stackoverflow.com/questions/7217… #pyspark #sparkstructuredstreaming

Prevent repartitioning in spark when using mapgroupswithstate in spark structured streaming stackoverflow.com/questions/7208… #apachekafka #apachespark #sparkstructuredstreaming

Half of messages lost when Spark Streaming (4 concurrent drivers) reads from Kafka and writes to MongoDB stackoverflow.com/questions/7176… #apachekafka #apachespark #sparkstructuredstreaming #sparkstreaming

Are distinct operations on Structured Streaming Datasets not supported? stackoverflow.com/questions/7188… #apachespark #sparkstructuredstreaming

Limit kafka batch size when using Spark Structured Streaming stackoverflow.com/questions/5297… #sparkstructuredstreaming #scala #apachekafka #apachespark #sparkstreaming

Records processed each batch with structured streaming stackoverflow.com/questions/6850… #sparkstructuredstreaming #apachespark

How to save kafka data into different location based on a column value in spark structured streaming? stackoverflow.com/questions/5675… #sparkstructuredstreaming #apachespark #apachekafka

Can I "branch" stream into many and write them in parallel in pyspark? stackoverflow.com/questions/6716… #sparkstructuredstreaming #pyspark #apachekafka

Calculating a moving average column using pyspark structured streaming stackoverflow.com/questions/6705… #sparkstructuredstreaming #pyspark #movingaverage

Track of consumed messages in Spark structured streaming stackoverflow.com/questions/6616… #sparkstructuredstreaming #apachespark #java #apachekafka

Writing Spark DataFrame to Kafka is ignoring the partition column and kafka.partitioner.class stackoverflow.com/questions/6592… #sparkstructuredstreaming #apachespark #apachesparksql #apachekafka

Spark Structured Streaming - multiple aggregations without re-reading data stackoverflow.com/questions/6579… #sparkstructuredstreaming #apachespark

ClassNotFoundException: org.apache.spark.sql.internal.connector.SimpleTableProvider stackoverflow.com/questions/6549… #sparkstructuredstreaming #apachespark #apachesparksql #apachekafka


Na deskach @BydgoszczJUG występuje @jaceklaskowski i opowiada o #kafkastreams i #sparkstructuredstreaming



Records processed each batch with structured streaming stackoverflow.com/questions/6850… #sparkstructuredstreaming #apachespark
Track of consumed messages in Spark structured streaming stackoverflow.com/questions/6616… #sparkstructuredstreaming #apachespark #java #apachekafka
Spark Structured Streaming - multiple aggregations without re-reading data stackoverflow.com/questions/6579… #sparkstructuredstreaming #apachespark
Can I "branch" stream into many and write them in parallel in pyspark? stackoverflow.com/questions/6716… #sparkstructuredstreaming #pyspark #apachekafka
ClassNotFoundException: org.apache.spark.sql.internal.connector.SimpleTableProvider stackoverflow.com/questions/6549… #sparkstructuredstreaming #apachespark #apachesparksql #apachekafka
Are distinct operations on Structured Streaming Datasets not supported? stackoverflow.com/questions/7188… #apachespark #sparkstructuredstreaming
Limit kafka batch size when using Spark Structured Streaming stackoverflow.com/questions/5297… #sparkstructuredstreaming #scala #apachekafka #apachespark #sparkstreaming
Calculating a moving average column using pyspark structured streaming stackoverflow.com/questions/6705… #sparkstructuredstreaming #pyspark #movingaverage
Writing Spark DataFrame to Kafka is ignoring the partition column and kafka.partitioner.class stackoverflow.com/questions/6592… #sparkstructuredstreaming #apachespark #apachesparksql #apachekafka
Pyspark Structured Streaming - Unable to perform mutiple aggregations - Need an alternative to aggregation functions stackoverflow.com/questions/7217… #pyspark #sparkstructuredstreaming
How to save kafka data into different location based on a column value in spark structured streaming? stackoverflow.com/questions/5675… #sparkstructuredstreaming #apachespark #apachekafka
Half of messages lost when Spark Streaming (4 concurrent drivers) reads from Kafka and writes to MongoDB stackoverflow.com/questions/7176… #apachekafka #apachespark #sparkstructuredstreaming #sparkstreaming
Prevent repartitioning in spark when using mapgroupswithstate in spark structured streaming stackoverflow.com/questions/7208… #apachekafka #apachespark #sparkstructuredstreaming

Find out the difference between spark streaming and spark structures streaming with a basic point and how to work both functionality real-time also @ bit.ly/31Gsu5G #ApacheSpark #ApacheSparkServices #SparkStructuredStreaming #SparkStreaming

Join Sharon Xie and Eric Xiao as they share their journey at @Decodableco, including choosing #ApacheFlink over #SparkStructuredStreaming for #streamdataprocessing. Save your spot for #FlinkForward Berlin: hubs.li/Q02H_N850
Join Sharon Xie and Eric Xiao as they share their journey at @Decodableco, including choosing #ApacheFlink over #SparkStructuredStreaming for #streamdataprocessing. Save your spot for #FlinkForward Berlin: hubs.li/Q02H_Ngw0

Good to be back to #ApacheSpark and mastering its own way of doing stream processing with #SparkStructuredStreaming Today's into state management. Any Qs? » StateStoreCoordinatorRef — RPC Endpoint Reference to StateStoreCoordinator jaceklaskowski.gitbooks.io/spark-structur…





Get familiar with #Kafka ecosystem, process data using #SparkStructuredStreaming and display results through #StreamingAnalytics in a captivating hack session with @dvgadiraju at #DHS2019 buff.ly/32gB24B

Something went wrong.
Something went wrong.
United States Trends
- 1. #GMMTV2026 3.98M posts
- 2. Good Tuesday 35.9K posts
- 3. MILKLOVE BORN TO SHINE 591K posts
- 4. #NuestraBanderaEsBolívar 2,430 posts
- 5. #OurCosmicClue_Wooyoung 11.8K posts
- 6. #tuesdayvibe 2,803 posts
- 7. Mark Kelly 232K posts
- 8. Alan Dershowitz 4,220 posts
- 9. Taco Tuesday 12.6K posts
- 10. WILLIAMEST MAGIC VIBES 118K posts
- 11. Happy Thanksgiving 17.2K posts
- 12. Hegseth 109K posts
- 13. Mainz Biomed N.V. N/A
- 14. University of Minnesota N/A
- 15. Praying for Pedro N/A
- 16. Enron 1,900 posts
- 17. #25Nov 2,776 posts
- 18. Witten N/A
- 19. Frank Gore N/A
- 20. JOSSGAWIN MAGIC VIBES 44.7K posts