
Adithya Bhaskar
@AdithyaNLP
Third year CS PhD candidate at Princeton University (@princeton_nlp @PrincetonPLI), previously CS undergrad at IIT Bombay
Language models that think, chat better. We used longCoT (w/ reward model) for RLHF instead of math, and it just works. Llama-3.1-8B-Instruct + 14K ex beats GPT-4o (!) on chat & creative writing, & even Claude-3.7-Sonnet (thinking) on AlpacaEval2 and WildBench! Read on. 🧵 1/8

Text-to-image (T2I) models can generate rich supervision for visual learning but generating subtle distinctions still remains challenging. Fine-tuning helps, but too much tuning → overfitting and loss of diversity. How do we preserve fidelity without sacrificing diversity (1/8)

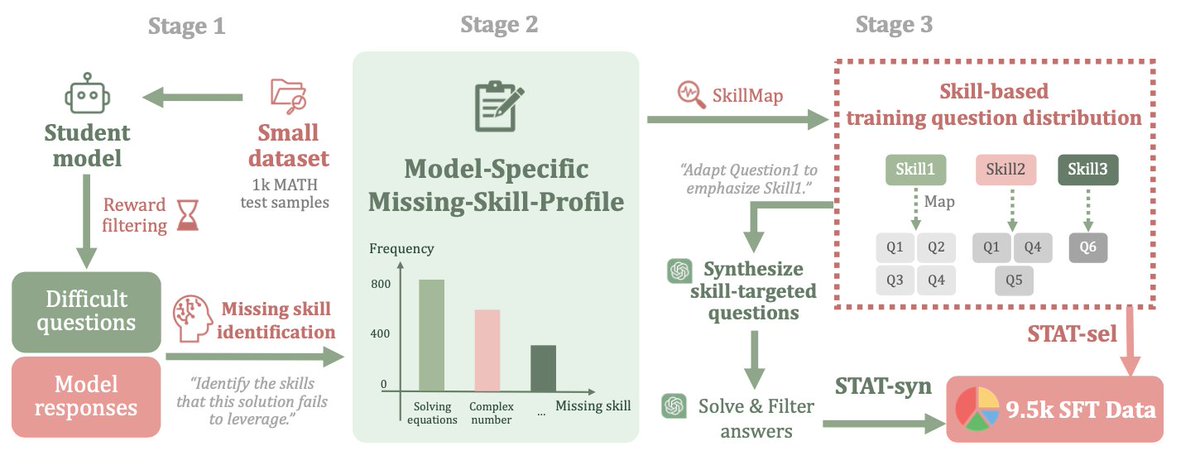
Claude Skills shows performance benefits from leveraging LLM skill catalogs at inference time. Our previous work (linked under thread 5/5) showed the same 6 months ago! 🌟Our new work, STAT, shows that leveraging skills during training can greatly help too‼️, e.g., Qwen can…


Check out our new work on making reasoning models think broadly! 🤔 We find a minimalist, surprisingly effective recipe to THINK for CHAT: RLVR + a strong reward model, trained on real-world prompts. This project was fun and surprised me in a few ways 👇 📌 We can run RL…
Language models that think, chat better. We used longCoT (w/ reward model) for RLHF instead of math, and it just works. Llama-3.1-8B-Instruct + 14K ex beats GPT-4o (!) on chat & creative writing, & even Claude-3.7-Sonnet (thinking) on AlpacaEval2 and WildBench! Read on. 🧵 1/8
Thanks for tweeting our paper!! 😁

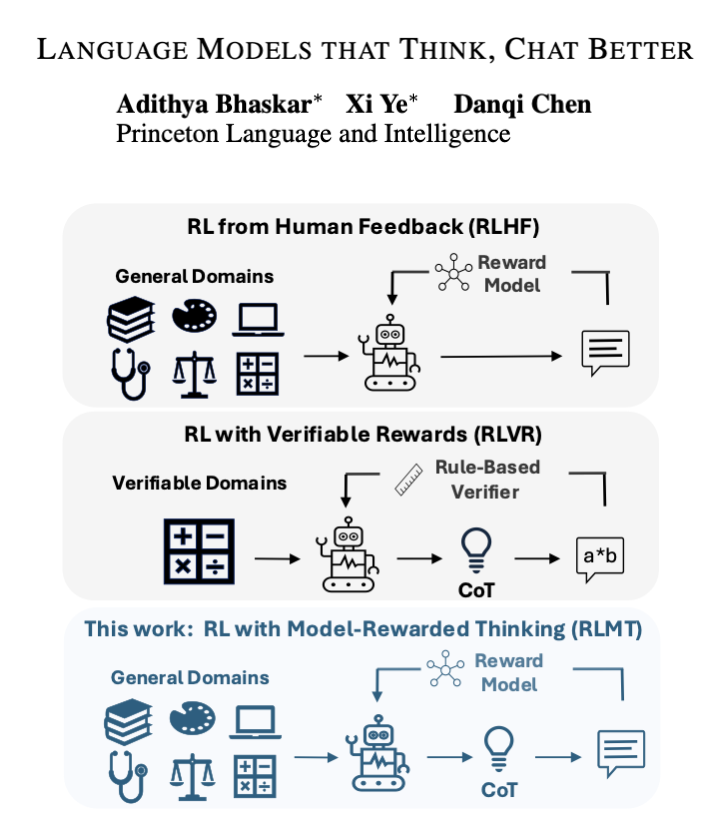
The paper shows that making models think before answering makes them chat better. It introduces reinforcement learning with model rewarded thinking, RLMT, which makes the model write a private plan, then the final reply. A separate reward model, trained from human choices,…

Honored to be included in the list, thanks a lot!

7. Language Models that Think, Chat Better A simple recipe, RL with Model-rewarded Thinking, makes small open models “plan first, answer second” on regular chat prompts and trains them with online RL against a preference reward. x.com/omarsar0/statu…
Top AI Papers of The Week (September 22-28): - ATOKEN - LLM-JEPA - Code World Model - Teaching LLMs to Plan - Agents Research Environments - Language Models that Think, Chat Better - Embodied AI: From LLMs to World Models Read on for more:
Thanks for your kind words!

Ever wonder why some AI chats feel robotic while others nail it? This new paper introduces a game-changer: Language Models that Think, Chat Better. They train AIs to "think" step-by-step before replying, crushing benchmarks. Mind blown? Let's dive in 👇

Thanks a lot for the shout-out! 😁


Thanks a lot for the tweet! We had a lot of fun working on this project! 😄

Language Models that Think, Chat Better "This paper shows that the RLVR paradigm is effective beyond verifiable domains, and introduces RL with Model-rewarded Thinking (RLMT) for general-purpose chat capabilities." "RLMT consistently outperforms standard RLHF pipelines. This…


Are AI scientists already better than human researchers? We recruited 43 PhD students to spend 3 months executing research ideas proposed by an LLM agent vs human experts. Main finding: LLM ideas result in worse projects than human ideas.






















































































United States Xu hướng
- 1. Good Thursday 21.5K posts
- 2. Lakers 79.9K posts
- 3. #Talus_Labs N/A
- 4. Luka 71K posts
- 5. Marcus Smart 6,300 posts
- 6. Wemby 27.3K posts
- 7. #LakeShow 5,776 posts
- 8. #AmphoreusStamp 7,385 posts
- 9. Blazers 9,074 posts
- 10. Russ 11.3K posts
- 11. Richard 46.1K posts
- 12. Ayton 16.9K posts
- 13. Unplanned 5,812 posts
- 14. #dispatch 65.7K posts
- 15. Podz 2,448 posts
- 16. Shroud 5,779 posts
- 17. Nico Harrison 2,056 posts
- 18. Fire Nico 1,097 posts
- 19. Bronny 5,444 posts
- 20. #Survivor49 3,472 posts
Something went wrong.
Something went wrong.