
你可能會喜歡















Lecture slides for my "Introduction to #ComputerVision" and "#DeepLearning in Computer Vision" courses. 🆕 Gaussian Splatting 🆕 Flow Matching The included videos do not contain voiceovers yet, planned for a future revision.



I would like you to tell me based on the coffee pattern whether my research proposal will be successful. ChatGPT5: General Impression The residue forms a thick central column leading upward, almost like a tree trunk or a road. This is traditionally read as a path of effort…



Ranked worst times to open a "decision email": 1. Your birthday 2. Vacation 3. Dinner with loved ones
It’ll never work …

We've trained an unsupervised language model that can generate coherent paragraphs and perform rudimentary reading comprehension, machine translation, question answering, and summarization — all without task-specific training: blog.openai.com/better-languag…

Google and ETH have joined the large scale localization effort with a banger I really did not expect this And now I'm really hoping to make it to NeurIPS where the paper will be presented I'll read it and report a summary here in the next few days


This week’s #CVPR2026 abstract deadline is FIRM. NO extensions. NO exceptions! Important dates and deadlines: cvpr.thecvf.com/Conferences/20…

Adaptable Intelligence. Multiple possible paths to an objective.

Imagine losing first authorship because you got hit by a blue shell on the last lap 💀


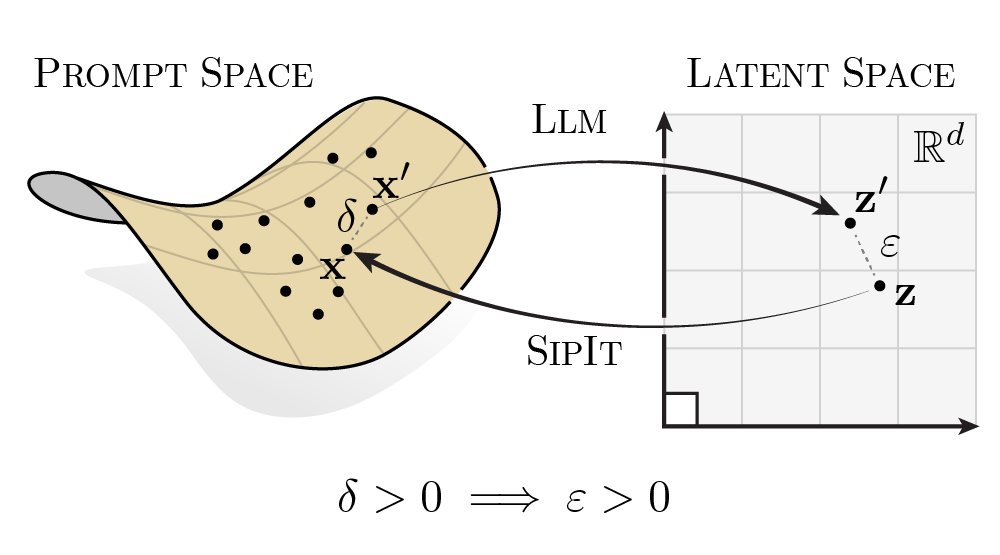
LLMs are injective and invertible. In our new paper, we show that different prompts always map to different embeddings, and this property can be used to recover input tokens from individual embeddings in latent space. (1/6)

What really matters in matrix-whitening optimizers (Shampoo/SOAP/PSGD/Muon)? We ran a careful comparison, dissecting each algorithm. Interestingly, we find that proper matrix-whitening can be seen as *two* transformations, and not all optimizers implement both. Blog:…

The Computer Science section of @arxiv is now requiring prior peer review for Literature Surveys and Position Papers. Details in a new blog post

Tesfaldet et al., "Generative Point Tracking with Flow Matching" Tracking, waaaaaay back in the days, used to be solved using sampling methods. They are now back. Also reminds me of my first major conference work, where I looked into how much impact the initial target point has.

I contemplated whether I should post this, because it seems kind of obvious. But it's often taken for granted, so we might underestimate the impact: e.g. these days, diffusion papers don't usually show samples without guidance anymore (figures from GLIDE arxiv.org/abs/2112.10741)




Generative modelling used to be about capturing the training data distribution. Interestingly, this stopped being the case when we started actually using them🤔 We tweak temps, use classifier-free guidance and post-train to get a distribution better than the training data.
Our new method for diffusion stitching allows us to generate ultra-long video sequences that follow a long, pre-defined camera trajectory! All segments are generated in parallel (not auto-regressive) and so the model never generates walls that it has to later step through!

Introducing Generative View Stitching (GVS), a non-autoregressive sampling method for length extrapolation of video diffusion models. GVS enables collision-free camera-guided video generation for predefined trajectories, including Oscar Reutersvärd's Impossible Staircase (1/9).

📢 New Paper PointSt3R: Point Tracking through 3D Grounded Correspondence Can point tracking be re-formulated as pairwise frame correspondence solely? We fine-tuning MASt3R with dynamic correspondences and a visibility loss and achieve competitive point tracking results 1/3
This Halloween's HOTTEST costume 🔥🔥🔥





























































































United States 趨勢
- 1. #IDontWantToOverreactBUT N/A
- 2. Howie 7,432 posts
- 3. #MondayMotivation 35K posts
- 4. Hobi 47.1K posts
- 5. Phillips 498K posts
- 6. Winthrop 1,471 posts
- 7. Victory Monday 2,626 posts
- 8. Good Monday 49.5K posts
- 9. #MondayVibes 3,008 posts
- 10. $IREN 15.3K posts
- 11. 60 Minutes 115K posts
- 12. Maddie Kowalski 1,770 posts
- 13. #Talus_Labs N/A
- 14. Kimberly-Clark 1,733 posts
- 15. Kenvue 2,457 posts
- 16. Happy Birthday Kim N/A
- 17. $QURE 1,953 posts
- 18. Tomorrow is Election Day N/A
- 19. #MondayMood 1,505 posts
- 20. Queens 38.3K posts
你可能會喜歡
-
 Michael Black
Michael Black
@Michael_J_Black -
 Matthias Niessner
Matthias Niessner
@MattNiessner -
 Jürgen Schmidhuber
Jürgen Schmidhuber
@SchmidhuberAI -
 Peyman Milanfar
Peyman Milanfar
@docmilanfar -
 Soumith Chintala
Soumith Chintala
@soumithchintala -
 Yi Ma
Yi Ma
@YiMaTweets -
 Aran Komatsuzaki
Aran Komatsuzaki
@arankomatsuzaki -
 Jia-Bin Huang
Jia-Bin Huang
@jbhuang0604 -
 AK
AK
@_akhaliq -
 Lucas Beyer (bl16)
Lucas Beyer (bl16)
@giffmana -
 #CVPR2026
#CVPR2026
@CVPR -
 Vincent Sitzmann
Vincent Sitzmann
@vincesitzmann -
 Percy Liang
Percy Liang
@percyliang -
 Alfredo Canziani
Alfredo Canziani
@alfcnz -
 Vittorio Ferrari
Vittorio Ferrari
@VittoFerrariCV
Something went wrong.
Something went wrong.