
Xavi Giró
@DocXavi
Applied scientist at @amazonscience Barcelona, Catalonia. Made at @la_upc & @columbia. Promoting @dlbcnai. Opinions my own.
You might like
















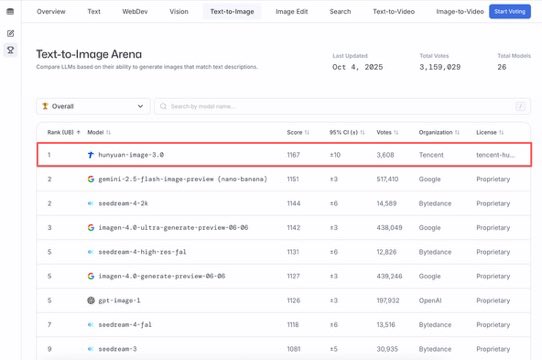
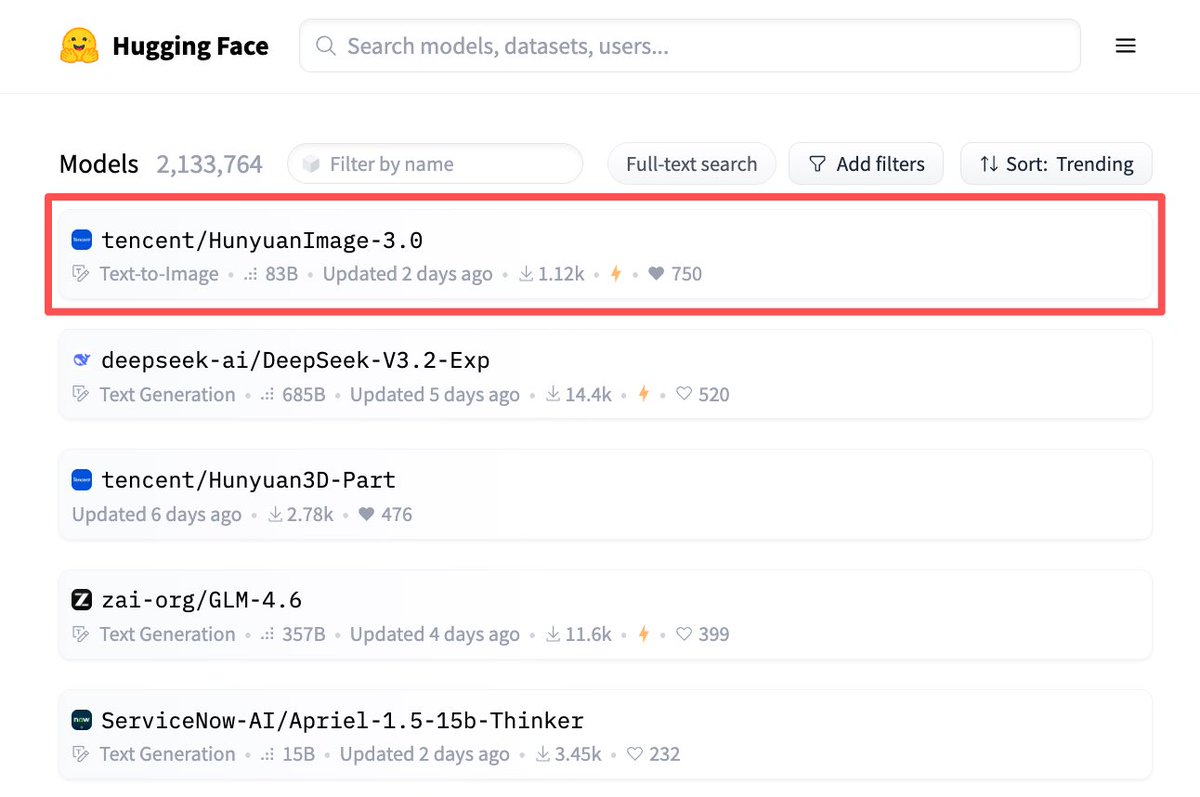
Congratulations @TencentHunyuan for the best image generation model in the world. It comes with a fantastic paper that describes the data pipeline in great detail. More detail on the RL part would be great 😉


Leaving Meta and PyTorch I'm stepping down from PyTorch and leaving Meta on November 17th. tl;dr: Didn't want to be doing PyTorch forever, seemed like the perfect time to transition right after I got back from a long leave and the project built itself around me. Eleven years…


We have unlocked parallel training of non-linear RNNs! > LSTM entered the chat 🔥

𝗣𝗮𝗿𝗮𝗥𝗡𝗡: 𝗨𝗻𝗹𝗼𝗰𝗸𝗶𝗻𝗴 𝗣𝗮𝗿𝗮𝗹𝗹𝗲𝗹 𝗧𝗿𝗮𝗶𝗻𝗶𝗻𝗴 𝗼𝗳 𝗡𝗼𝗻𝗹𝗶𝗻𝗲𝗮𝗿 𝗥𝗡𝗡𝘀 𝗳𝗼𝗿 𝗟𝗟𝗠𝘀 For years, we’ve given RNNs for doomed, and looked at Transformer as 𝘁𝗵𝗲 LLM—but we just needed better math 📄arxiv.org/abs/2510.21450 💻github.com/apple/ml-parar…

Check out the list of #WACV2026 workshops at wacv.thecvf.com/Conferences/20…. Many have paper submission deadlines in the next month!


Good thread! I'd also add that faculty positions are often decently paid, give you the freedom to do work that benefits society, and, if everything works out, you can keep the job for life so you don't need to worry about saving 50% of your income and all of that FIRE nonsense.

Even before @mmitchell_ai recently raised this discussion, I've had conversation after conversation with students & new grads struggling with this exact dilemma. I want to help! Here's a live thread of AI-related opportunities for those looking to do good & make (enough) money:


✨The source code for our paper “Look, Listen and Recognise: Character-Aware Audio-Visual Subtitling” is now released! ✨ Given a video, its audio, and a cast list for each episode, the model can automatically generate subtitles with speaker names.

It was Spring 2015, and it was the first time I was teaching deep learning, @UPCTelecos Barcelona. Only two students posed questions that day. 10 years later, they are both scientists at @GoogleDeepMind. As said in @AmazonScience : “learn and be curious”.

Tired of chasing references across dozens of papers? This monograph distills it all: the principles, intuition, and math behind diffusion models. Thrilled to share!

Tired to go back to the original papers again and again? Our monograph: a systematic and fundamental recipe you can rely on! 📘 We’re excited to release 《The Principles of Diffusion Models》— with @DrYangSong, @gimdong58085414, @mittu1204, and @StefanoErmon. It traces the core…


Congratulations to @Yoshua_Bengio, founder and scientific advisor of Mila, who has become the first researcher in the world to surpass one million citations on Google Scholar, the leading platform for academic and scientific research. A remarkable milestone that highlights the…


Our Founder and Scientific Director @Yoshua_Bengio has become the first living researcher to surpass 1 million citations on Google Scholar, a testament to the foundational and global impact of his work. Congratulations Yoshua!

This is my annual post claiming that the program of #DLBCN 2025 this year is even better than the previous one.
The 9 spotlights talks of #DLBCN 2025 have been announced in our site: sites.google.com/view/dlbcn2025… The selection was made based on both quality & diversity criteria.



And yet another paper within our series of works on music matching. Now... 🥁🥁🥁 Music sampling! Complementing fingerprinting, version ID, and lyrics matching systems, detecting music sampling is key given modern music practice. SOTA results with a number of clever tricks.

UPC will award an honoris causa doctorate to Oriol Vinyals (@OriolVinyalsML) from @GoogleDeepMind. telecos.upc.edu/ca/noticies/la… Oriol was a keynote speaker in #DLBCN 2019:


When receiving the Everingham Prize yesterday, I gave a short presentation on the progress of vision-language research over the last decade. Slides (with transcript of my speech in the notes section): docs.google.com/presentation/d… Video of the talk: photos.app.goo.gl/bMrE8hHSiiN98z… Students…

As part of the award ceremony, @aagrawalAA presented a recap of vision-and-language research over the last decade — solved problems, progress, and open-challenges for mutimodal LLMs. Solved: robustness to paraphrasing and false premises, OCR, world-knowledge based reasoning.…





👋Say Hi to MiMo-Audio! Our BREAKTHROUGH in general-purpose audio intelligence. 🎯 Scaling pretraining to 100M+ hours leads to EMERGENCE of few-shot generalization across diverse audio tasks! 🔥 Post-trained MiMo-Audio-7B-Instruct: • crushes benchmarks: SOTA on MMSU, MMAU,…


The @karpathy interview 0:00:00 – AGI is still a decade away 0:30:33 – LLM cognitive deficits 0:40:53 – RL is terrible 0:50:26 – How do humans learn? 1:07:13 – AGI will blend into 2% GDP growth 1:18:24 – ASI 1:33:38 – Evolution of intelligence & culture 1:43:43 - Why self…
🚀 Cut Your Image Review Costs with Smart AutoQA! ✨ The magic formula: As long as your AutoQA precision beats your GenAI accuracy, you're saving money and time. arxiv.org/abs/2510.16179


In my blog post on latents for generative modelling, I pointed out that representation learning and reconstruction are two separate tasks (§6.3), which autoencoders try to solve simultaneously. Separating them makes sense. It opens up a lot of possibilities, as this work shows!

three years ago, DiT replaced the legacy unet with a transformer-based denoising backbone. we knew the bulky VAEs would be the next to go -- we just waited until we could do it right. today, we introduce Representation Autoencoders (RAE). >> Retire VAEs. Use RAEs. 👇(1/n)


We wrote a book about representation learning! It’s fully open source, available and readable online, and covers everything from theoretical foundations to practical algorithms. 👷♂️ We’re hard at work updating the content for v2.0, and would love your feedback and contributions

José M. Álvarez from NVIDIA will be the keynote speaker of #DLBCN 2025. Dr Álvarez leads the Autonomous Vechicle Applied Research Group at Nvidia, CA, USA (@NVIDIAAI ). Watch his interview with @neurofregides in 2024: youtube.com/shorts/x6HBanJ…


If you think @Apple is not doing much in AI, you're getting blindsided by the chatbot hype and not paying enough attention! They just released FastVLM and MobileCLIP2 on @huggingface. The models are up to 85x faster and 3.4x smaller than previous work, enabling real-time vision…






























































































































United States Trends
- 1. National Guard 113K posts
- 2. Thanksgiving 431K posts
- 3. #InfoSecVPN N/A
- 4. Frank Ragnow 4,939 posts
- 5. D.C. 224K posts
- 6. Mbappe 96.3K posts
- 7. Bayern 167K posts
- 8. Arsenal 294K posts
- 9. Patrick Morrisey 2,708 posts
- 10. Neuer 7,593 posts
- 11. Merino 8,210 posts
- 12. Kimmich 5,676 posts
- 13. Denzel 4,392 posts
- 14. Olympiacos 21.7K posts
- 15. WV Governor 2,916 posts
- 16. Anthony Rendon N/A
- 17. Lennart Karl 6,684 posts
- 18. #ARSBAY 4,675 posts
- 19. Wine 40.5K posts
- 20. Golesh 3,269 posts
You might like
-
 Oscar Mañas @ ICCV
Oscar Mañas @ ICCV
@oscmansan -
 Cees Snoek
Cees Snoek
@cgmsnoek -
 Deep Learning Barcelona Symposium
Deep Learning Barcelona Symposium
@dlbcnai -
 Karteek Alahari
Karteek Alahari
@inthebrownbag -
 Cristian Canton
Cristian Canton
@cristiancanton -
 Dima Damen
Dima Damen
@dimadamen -
 Andrei Bursuc
Andrei Bursuc
@abursuc -
 Torsten Sattler
Torsten Sattler
@SattlerTorsten -
 hazyresearch
hazyresearch
@HazyResearch -
 Joan Serrà
Joan Serrà
@serrjoa -
 Adriana Romero-Soriano
Adriana Romero-Soriano
@adri_romsor -
 CVC_UAB
CVC_UAB
@CVC_UAB -
 Jordi TORRES.AI
Jordi TORRES.AI
@JordiTorresAI -
 Jordi Pont-Tuset
Jordi Pont-Tuset
@jponttuset -
 Jay Whang
Jay Whang
@jaywhang_
Something went wrong.
Something went wrong.