
Guilhermo
@GuilhermoAI
Insighter | AI Designer and Builder | AI Evangelist | AI Accelerationist | Tech Optimist | Doing my best for a better world.
😅



🚨 Chinese AI company SenseTime just revealed SenseNova 5.5, an AI model that claims to beat GPT-4o across key metrics Plus, big developments from Apple, YouTube, KLING, Neuralink, and Google DeepMind. Here's everything going on in AI right now:

MobileLLM: nice paper from @AIatMeta about running sub-billion LLMs on smartphones and other edge devices. TL;DR: more depth, not width; shared matrices for token->embedding and embedding->token; shared weights between multiple transformer blocks; Paper: arxiv.org/abs/2402.14905


💥 If SDXL was trained with LLM as a text encoder, what would happen? 🧪 Kolors is the answer 🎨 - Kwai trained (from scratch!) an SDXL-arch model with the GLM-4 LLM as the text encoder, and it's fantastic! ▶️ Demo huggingface.co/spaces/gokaygo… 📁 Model huggingface.co/Kwai-Kolors/Ko…



New guide to using CUDA on @modal_labs just dropped. It began its life as a document called "I am fucking done not understanding the CUDA stack", and after readelf-ing CUDA binaries, RTFMing the driver docs, & writing homebrew kernels, I'm excited to share it with the world!
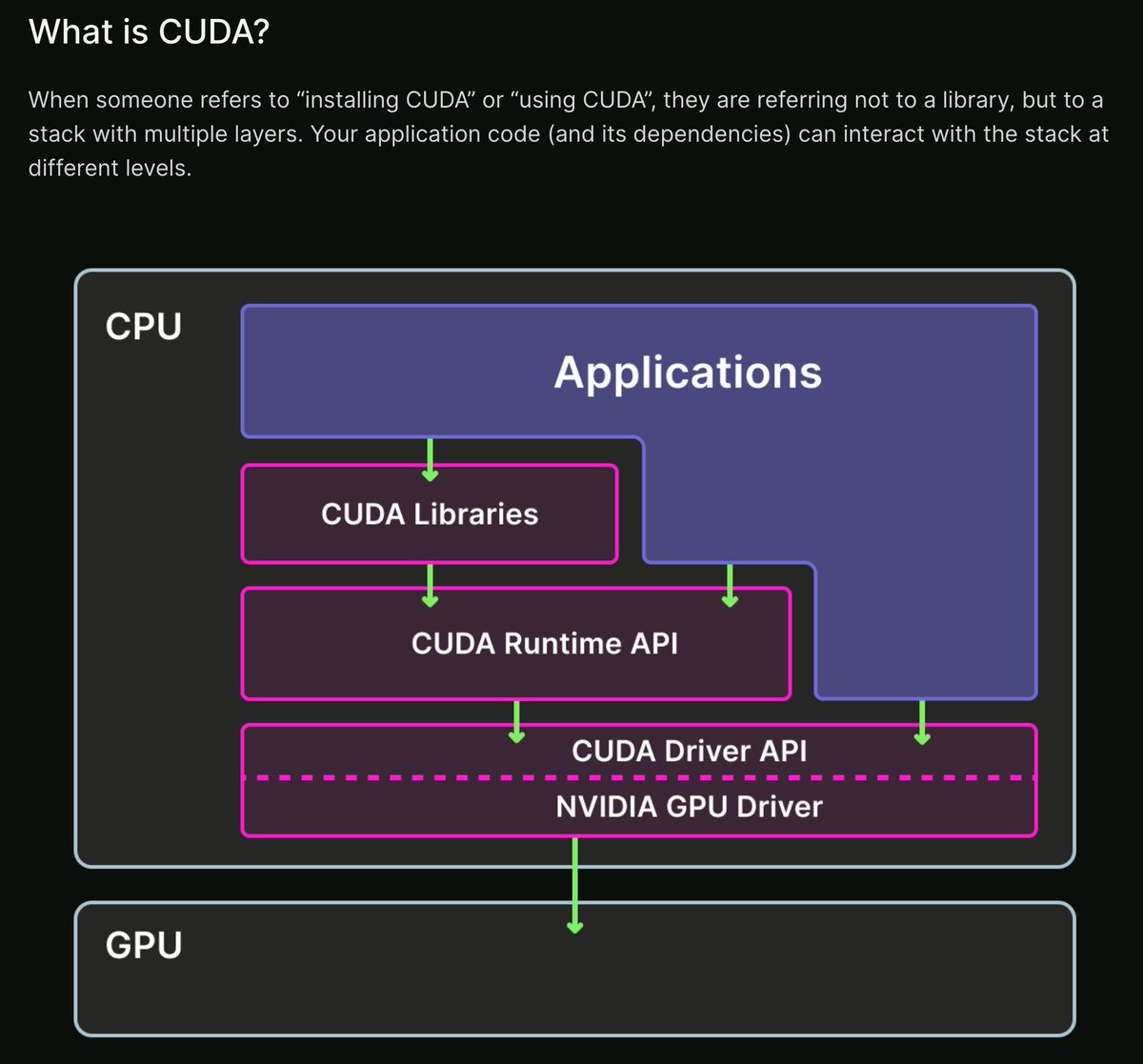

Holy smokes. @modal_labs is now my preferred method to run GPU workloads using the NVIDIA CUDA toolkit. I was tinkering with a GPU implementation of Conway's game of life using convolutions, and had it running in no time after following @charles_irl's guide.

New guide to using CUDA on @modal_labs just dropped. It began its life as a document called "I am fucking done not understanding the CUDA stack", and after readelf-ing CUDA binaries, RTFMing the driver docs, & writing homebrew kernels, I'm excited to share it with the world!

Here’s a proof of concept showing how data calculated in Python can be used in Blender. #Blender can process the received data with custom geometry nodes, custom shaders and full 3D interactivity. This minimal example uses @networkX in @ProjectJupyter. Learn more in this thread🧵

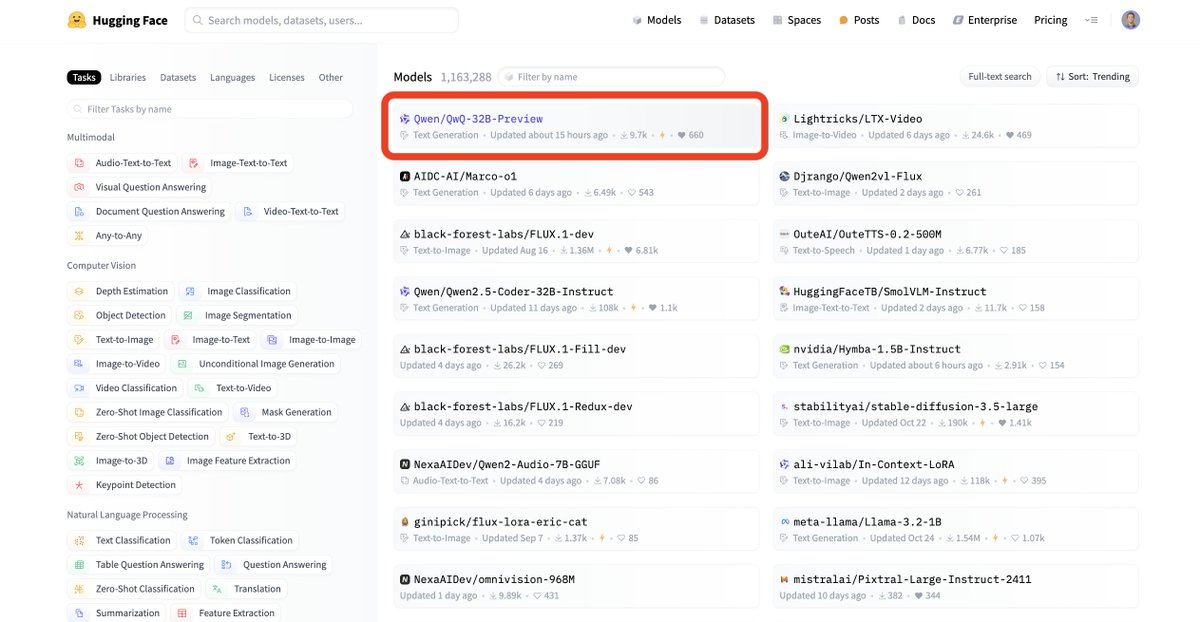
Shoutout to the team that built artificialanalysis.ai . Really neat site that benchmarks the speed of different LLM API providers to help developers pick which models to use. This nicely complements the LMSYS Chatbot Arena, Hugging Face open LLM leaderboards and Stanford's HELM…

Another big change with AI Agents, Multi Agent system and AI Apps in general is how we are shifting from strongly typed apps to "fuzzy" apps. Ofc there are now ways to get structured data out of LLMs that are great, but it's funny how it allowa for different kind of apps


8-bit and 4-bit ADAM implementations are now available in torchao thanks to @gaunernst github.com/pytorch/ao/tre…. Reducing your optimizer state by 4x and 8x respectively relative to fp32. These were written in pure PyTorch and then torch.compiled to achieve performance competitive…
🤖🔍🧑💻 AI Agents find me candidates! Agents using RLHF find candidates, score and put together templates I can use! Showcasing the new crewai train feature Longer than my usual, hope you like it 🤞 Retweets are super appreciated 🙏 lmk if I this is one worth sharing the code

📚 @jerryjliu0 on "The Future of Knowledge Assistants": 🧠 Exploring the development of knowledge assistants, covering document processing, tagging & extraction, knowledge search & QA (RAG), knowledge base sourcing, workflow automation, and more. 🔑 Key points: - 🧩 RAG…


Wrote quite a lengthy blog - "Reinforcement Learning from Human Feedback (RLHF) in Practice: A Deep Dive" 👨🔧 ( 🔗link in 1st comment) Covering the following topics 📌 The fundamental building blocks and flow of RLHF with its 3-phase process: a) Supervised fine-tuning (SFT) >…


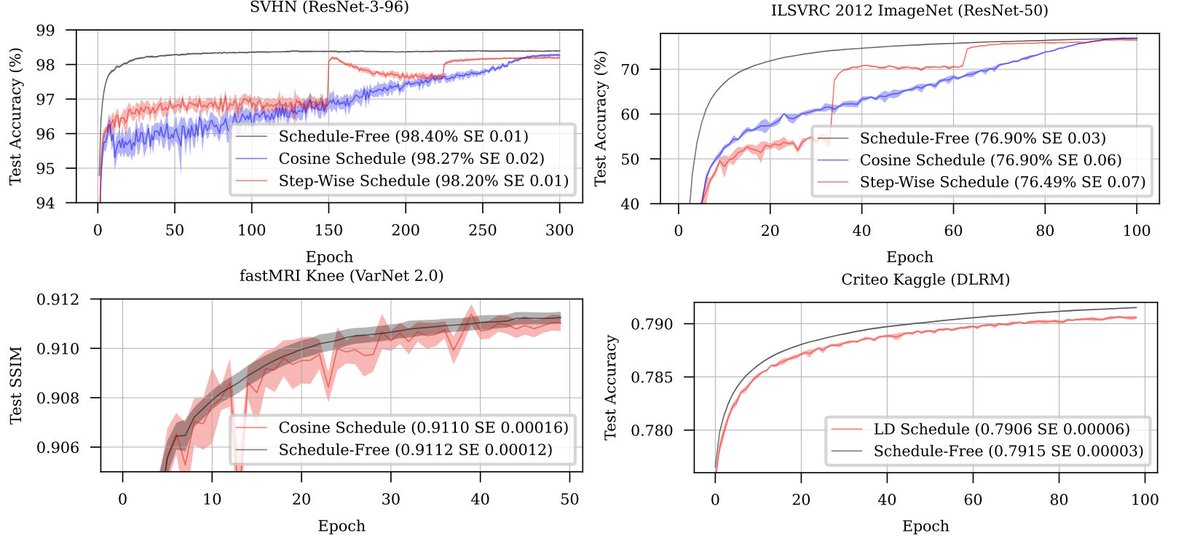
I trained GPT-2 (124M) with @aaron_defazio's Schedule-Free optimizer on @karpathy's nanoGPT: - Settings: AdamW with learning rate=0.0018 (same as x.com/Yuchenj_UW/sta…), warmup_steps=700; Schedule-Free AdamW with default learning rate=0.0025, warmup_steps=700 - Observations:…


Schedule-free optimizers (x.com/aaron_defazio/…) are surreal. I've read the paper, looked into the math, and tried to understand what's happening. It all seems like an incremental improvement at best (like LaProp (arxiv.org/abs/2002.04839) or Adam-Atan2…



DeepSeek-v2-Coder is really so impressive. This blog did a great work on checkin 180+ LLMs on code writing quality. There are only 3 models (Anthropic Claude 3 Opus, DeepSeek-v2-Coder, GPT-4o) that had 100% compilable Java code, while no model had 100% for Go. "following plot…


A new version of Claude Engineer is out! 🔥 📝 Whole new diff file editing with an improved search and edit function 🌈 Color-coded diffs. 👨🏫 The system prompt has been updated with more detailed instructions. 💬 Conversation history management has been improved.


GraphRAG Ollama: 100% Local Setup, Keeping your Data Private 🔍 Integrate @ollama & @LMStudioAI 📚 Convert data to knowledge graph 🖥️ Run locally for privacy ⚙️ Configure models easily 📈 Enhance AI capabilities Subscribe: youtube.com/@MervinPraison

The Top ML Papers of the Week (July 1 - July 7): - APIGen - CriticGPT - Agentless - LLM See, LLM Do - Scaling Synthetic Data Creation - Searching for Best Practices in RAG ...
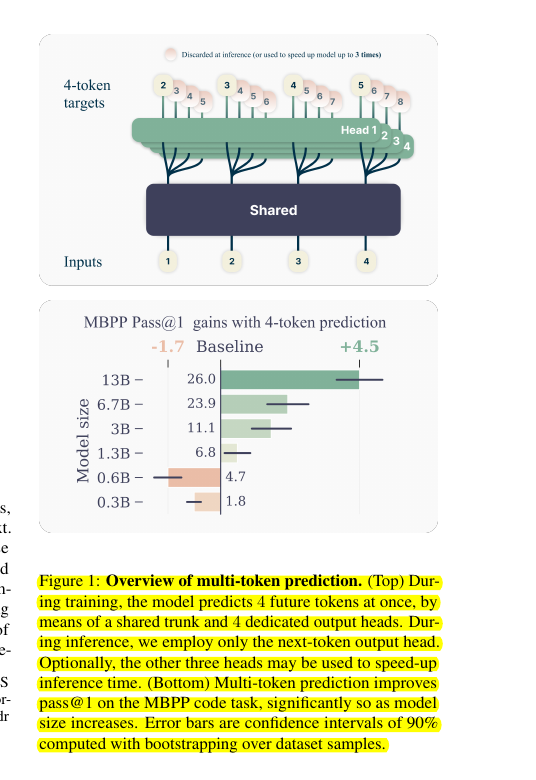
The "Multi-token Prediction" paper (April-2024) from @AIatMeta and behind the Chameleon family of models is such an innovative idea. 👨🔧 Original Problem it solves Most LLMs have a simple training objective: predicting the next word. While this approach is simple and scalable,…


























































































United States Trends
- 1. #BaddiesUSA 61.6K posts
- 2. Rams 29.6K posts
- 3. TOP CALL 3,411 posts
- 4. #LAShortnSweet 22.2K posts
- 5. Scotty 9,957 posts
- 6. Cowboys 101K posts
- 7. Eagles 141K posts
- 8. Chip Kelly 8,790 posts
- 9. #centralwOrldXmasXFreenBecky 288K posts
- 10. SAROCHA REBECCA DISNEY AT CTW 303K posts
- 11. sabrina 62.8K posts
- 12. #ITWelcomeToDerry 15.8K posts
- 13. AI Alert 1,017 posts
- 14. Raiders 68.1K posts
- 15. Market Focus 2,263 posts
- 16. Vin Diesel 1,324 posts
- 17. #RHOP 12.4K posts
- 18. Ahna 7,368 posts
- 19. Stacey 24.6K posts
- 20. Stafford 15.3K posts
Something went wrong.
Something went wrong.