
Jerry Lin
@JLinAffect
AI Software Engineer. Formally LinkedIn MLE & USC AI. Music/portrait photographer for fun.
You might like



This is interesting as a first large diffusion-based LLM. Most of the LLMs you've been seeing are ~clones as far as the core modeling approach goes. They're all trained "autoregressively", i.e. predicting tokens from left to right. Diffusion is different - it doesn't go left to…

We are excited to introduce Mercury, the first commercial-grade diffusion large language model (dLLM)! dLLMs push the frontier of intelligence and speed with parallel, coarse-to-fine text generation.
DeepSeek (Chinese AI co) making it look easy today with an open weights release of a frontier-grade LLM trained on a joke of a budget (2048 GPUs for 2 months, $6M). For reference, this level of capability is supposed to require clusters of closer to 16K GPUs, the ones being…

🚀 Introducing DeepSeek-V3! Biggest leap forward yet: ⚡ 60 tokens/second (3x faster than V2!) 💪 Enhanced capabilities 🛠 API compatibility intact 🌍 Fully open-source models & papers 🐋 1/n

Randomly checked which LLM AIs could correctly count Rs in the word strawberry, and Gemini got it right. ChatGPT and Claude both said 2.

Here's a new paper that directly studies this question: arxiv.org/abs/2410.22071
I've been exploring the hypothesis that LLMs already know the knowledge that they need and the problem is to get them to recall that knowledge and apply it in the right contexts. In Human Problem Solving, Newell and Simon describe tactics that people use to "evoke" knowledge. 1/

If you haven't decided yet who to vote for, here's why I think you should vote for Harris.


Dad from Jamaica, mom from India, they met in California. They had a baby named Kamala. She grew up and married a Jewish guy from Brooklyn. That’s America! This was lost in all of Trump's ugly, divisive, racist attacks yesterday. Kamala Harris’ story is uniquely American,…

Neural Network Diffusion Diffusion models have achieved remarkable success in image and video generation. In this work, we demonstrate that diffusion models can also generate high-performing neural network parameters. Our approach is simple, utilizing an autoencoder and a…

Here's my take on the Sora technical report, with a good dose of speculation that could be totally off. First of all, really appreciate the team for sharing helpful insights and design decisions – Sora is incredible and is set to transform the video generation community. What we…

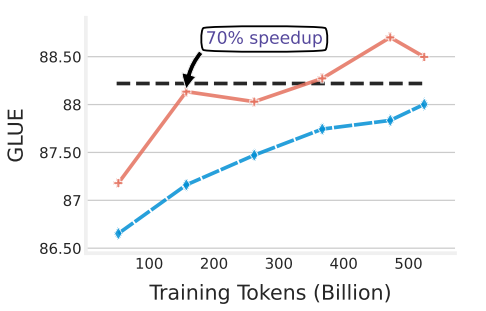
Google presents How to Train Data-Efficient LLMs Models trained on ASK-LLM data consistently outperform full-data training—even when we reject 90% of the original dataset, while converging up to 70% faster arxiv.org/abs/2402.09668

It's only been 5 hours since Open AI announced Sora, and people are going crazy over it. Here are 10 wild examples you don't want to miss: 1. Snow dogs

This video was made with the not-yet-released Sora AI technology just announced from OpenAi. This changes everything. It's 27 seconds from a text prompt. Here is their prompt: Prompt: A white and orange tabby cat is seen happily darting through a dense garden, as if chasing…
AGI research appears to be converging on a structure similar to the human brain.

It was an honor to give a guest lecture yesterday at Stanford’s CS330 class, "Deep Multi-Task and Meta-Learning"! I discussed a few very simple intuitions for how I personally think about large language models. Slides: docs.google.com/presentation/d… Here are the six intuitions: (1)…


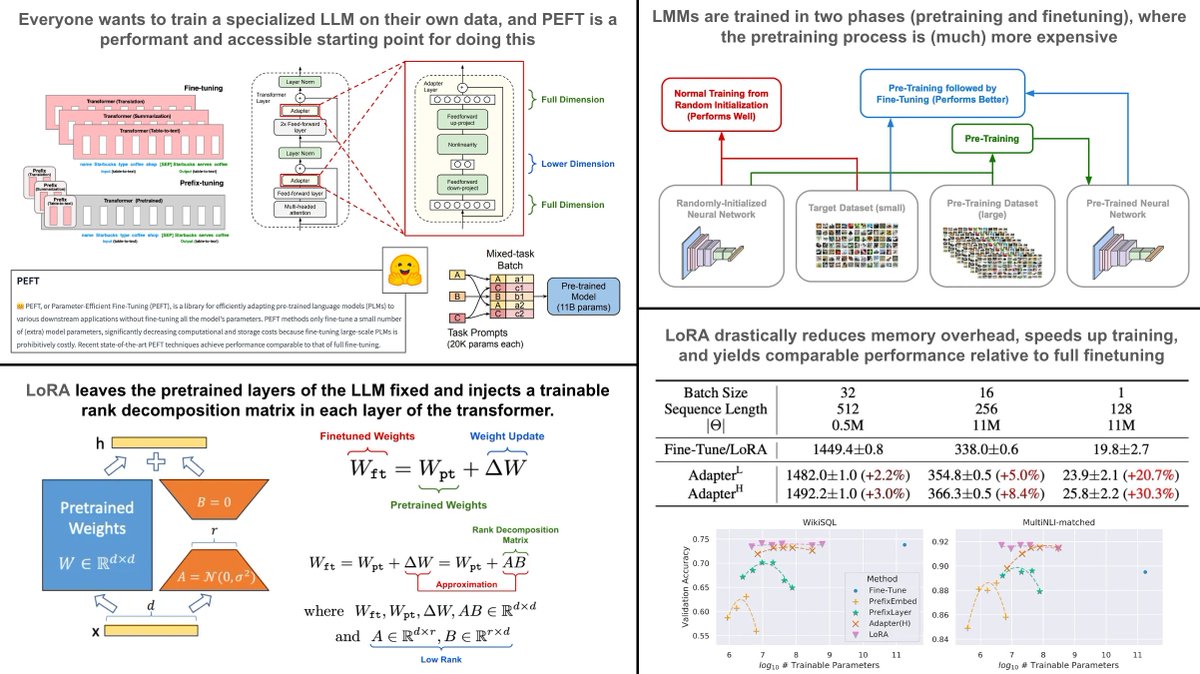
Due to the recent surge in popularity of AI and language models, one of the most common questions I hear is: How can we train a specialized LLM over our own data? The answer is actually pretty simple… TL;DR: Training LLMs end-to-end is quite difficult due to the size of the…

I agree 100%

Animals and humans get very smart very quickly with vastly smaller amounts of training data. My money is on new architectures that would learn as efficiently as animals and humans. Using more data (synthetic or not) is a temporary stopgap made necessary by the limitations of our…
New YouTube video: 1hr general-audience introduction to Large Language Models youtube.com/watch?v=zjkBMF… Based on a 30min talk I gave recently; It tries to be non-technical intro, covers mental models for LLM inference, training, finetuning, the emerging LLM OS and LLM Security.

College admissions has always been about a student body that generates the most value for the university. Enabling students to succeed by connecting them to power, wealth, and intellectual diversity has been the most successful approach yet, but is ending. #AffirmativeAction


We spoke directly to Wayne LaPierre at the NRA Convention and thanked him for all his thoughts and prayers.

I have this old 2006 BusinessWeek framed as a reminder. The “risky bet” that Wall Street disliked was AWS, which generated revenue of more than $62 billion last year.
































































































United States Trends
- 1. FINALLY DID IT 427 B posts
- 2. The PENGU 221 B posts
- 3. The Jupiter 210 B posts
- 4. Brigitte Bardot 81 B posts
- 5. Good Sunday 57,2 B posts
- 6. Phrases for Telephone Calls N/A
- 7. #tide 2.940 posts
- 8. #sundayvibes 3.561 posts
- 9. #zodiac 4.867 posts
- 10. Tang 80,8 B posts
- 11. MIN YOONGI 26,2 B posts
- 12. YOONGIS 2.789 posts
- 13. SUGA 88,8 B posts
- 14. #humble 2.363 posts
- 15. WE LOVE YOU YOONGI 15,4 B posts
- 16. #volcano 2.709 posts
- 17. Sunday of 2025 11,9 B posts
- 18. Pulisic 6.434 posts
- 19. Derrick Henry 39,3 B posts
- 20. X-Men 23,6 B posts


Something went wrong.
Something went wrong.