
Cameron R. Wolfe, Ph.D.
@cwolferesearch
Research @Netflix • Writer @ Deep (Learning) Focus • PhD @optimalab1 • I make AI understandable
You might like















Reinforcement Learning (RL) is quickly becoming the most important skill for AI researchers. Here are the best resources for learning RL for LLMs… TL;DR: RL is more important now than it has ever been, but (probably due to its complexity) there aren’t a ton of great resources…

The original PPO-based RLHF pipeline had 4 model copies: 1. Policy 2. Reference 3. Critic 4. Reward Model Recent GRPO-based RLVR pipelines have eliminated all of these models except for the policy. - The critic is no longer needed because values are estimated from group…
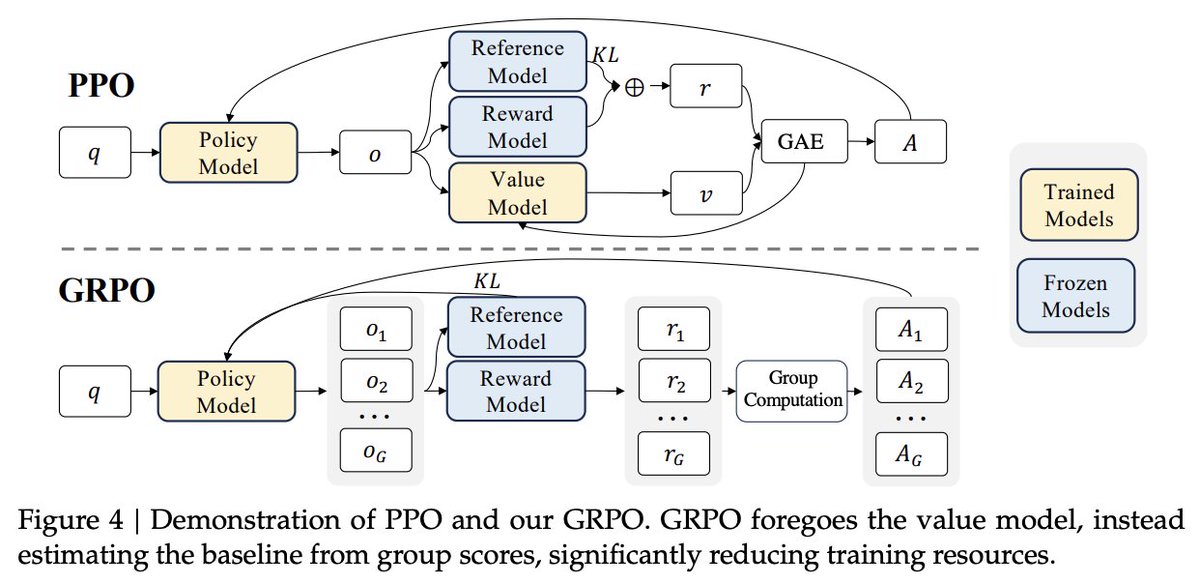
Interesting note from Olmo-3 that KL divergence is excluded from GRPO loss. This is becoming a standard choice for reasoning / RL training pipelines, and it doesn't seem to cause training instability. Yet another reminder that RL for LLMs very different than traditional DeepRL.

The Olmo technical reports / artifacts are by far the most useful resource for those working on LLMs outside of closed frontier labs. You can read the papers, read the code, look at the data, and even train the models yourself. No other resource provides this level of detail, and…

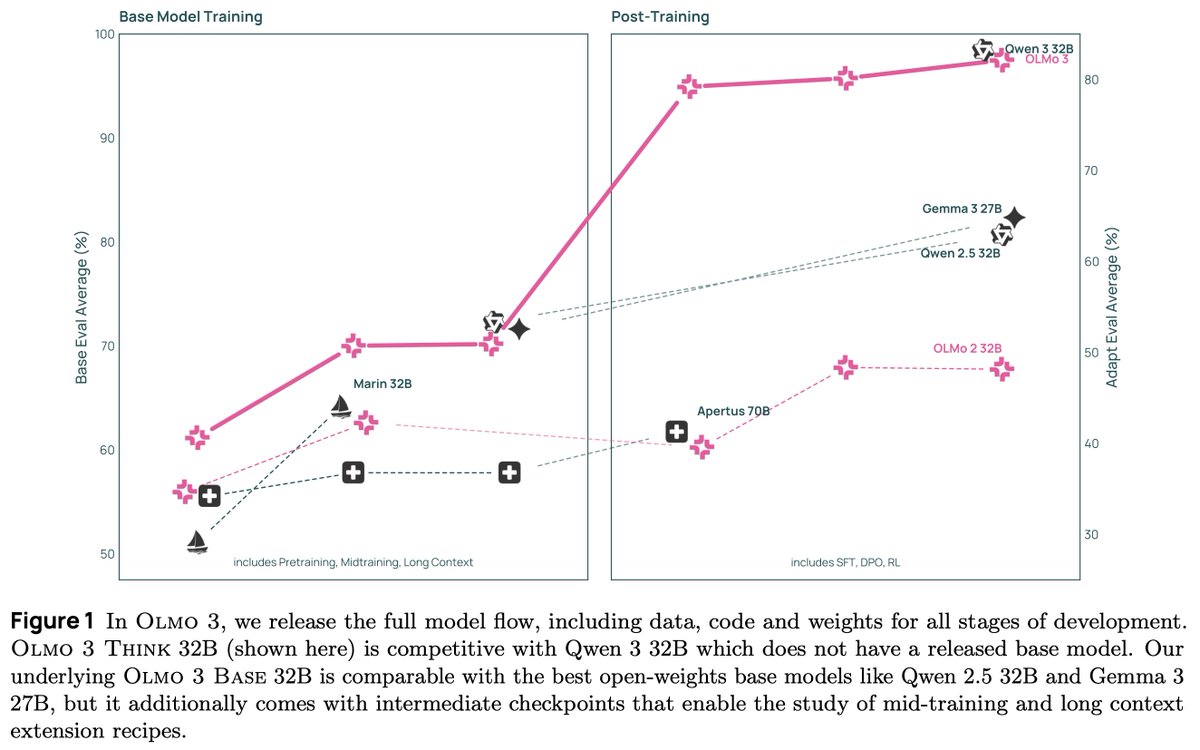
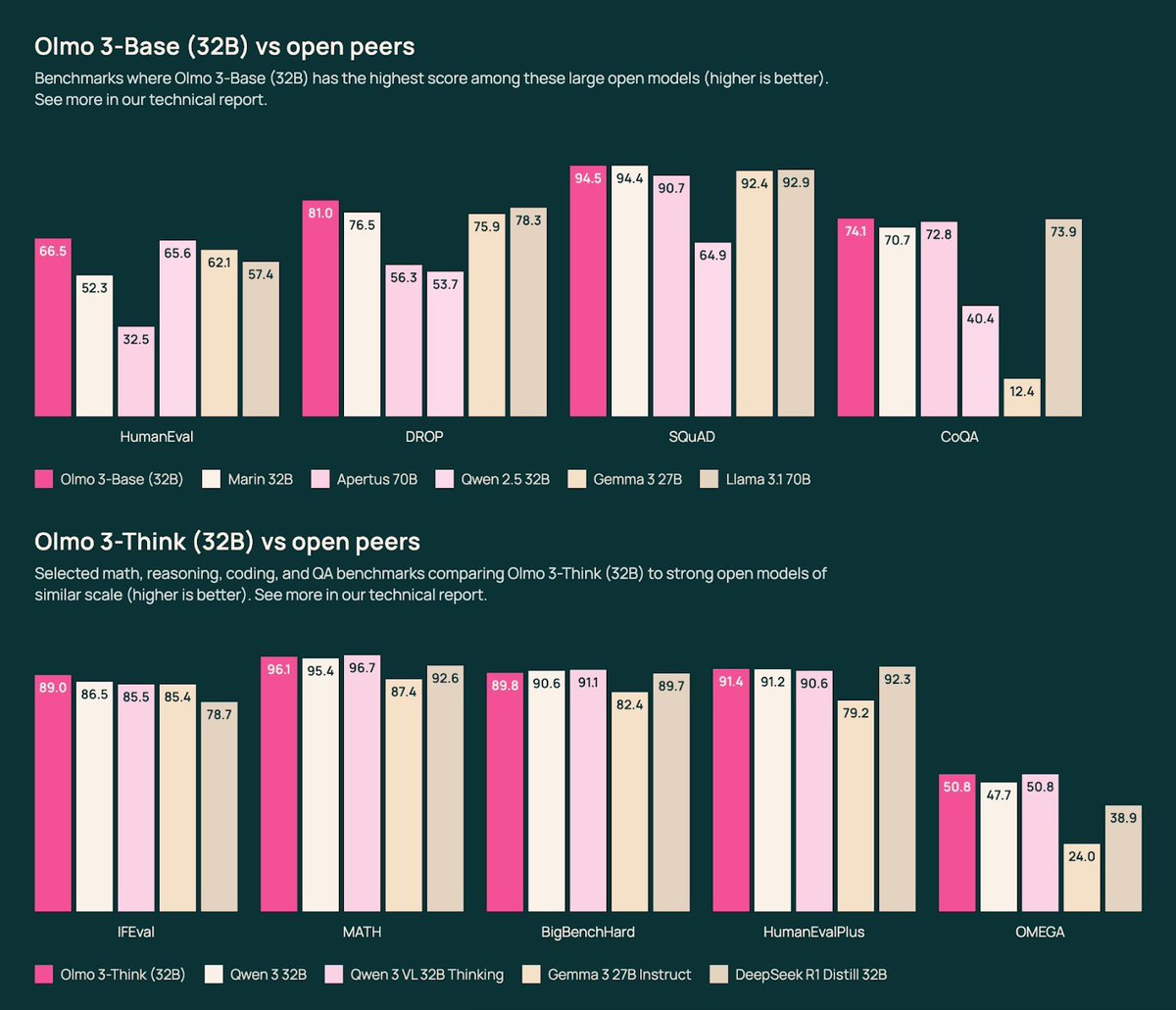
We present Olmo 3, our next family of fully open, leading language models. This family of 7B and 32B models represents: 1. The best 32B base model. 2. The best 7B Western thinking & instruct models. 3. The first 32B (or larger) fully open reasoning model. This is a big…

Generalized Advantage Estimation (GAE)–used in PPO–is one of the most complicated aspects of reinforcement learning (RL). Here’s how it works and how we can implement it… The advantage tells us how much better a given action is compared to the average action in a given state:…

This is (in my opinion) one of the top-3 most useful books to be written on LLMs. I highly recommend reading / buying it. I've personally read it >10 times since Nathan started writing it.
I'm excited to announce my RLHF Book is now in pre-order for the Manning Early Access Program (MEAP), @ManningBooks, and for this milestone it's 50% off. Excited to land in print in early 2026! Lots of improvements coming soon. Link below & thanks for the support!

The next AI Agents in Production conference is on November 18th. For those interested in the practical side of LLMs / agents, this is a good event to attend. Some highlights: - Completely free. - Everything can be viewed online. - Good talks from top companies (OAI, GDM, Meta,…

Couldn't be more excited for better interaction between X / substack. Check out my newsletter here: cameronrwolfe.substack.com

Update 2: even correcting for the fake views, traffic to Substack links from X is up substantially. (full post reads, signups, etc. also track.) We're so back!

The memory folding mechanism proposed in this paper is great. It makes sense that agents should spend time explicitly compressing their memory into a semantic / organized format to avoid context explosion. Worth mentioning though that memory compression / retention in agents…

assistive coding tools definitely make me more productive, but the pattern isn't uniform. biggest productivity boost comes later in the day / at night when I'm mentally exhausted. LLMs lower the barrier to entry for getting extra work done. validating or iterating on code with an…
The value of RL is very clearly / nicely articulated by DeepSeekMath… - RL enhances maj@k (majority vote), but not pass@k. - RL boosts the probability of correct completions that are already in top-k. - RL does NOT clearly enhance model capabilities.


I can't believe I'm saying this - I'm officially a published author :D After three years, my first book is out. "AI for the Rest of Us" with @BloomsburyAcad is finally in the world. I wrote it because I watched too many people get left behind in AI conversations. The gap…


"Through clever storytelling and illustration, [Sundaresan] brings technical concepts to life[.]" — Dr. Cameron R. Wolfe, Senior Research Scientist at Netflix (@cwolferesearch) Learn more: bit.ly/42ZCs4z @DSaience
![BloomsburyAcad's tweet image. "Through clever storytelling and illustration, [Sundaresan] brings technical concepts to life[.]" — Dr. Cameron R. Wolfe, Senior Research Scientist at Netflix (@cwolferesearch)
Learn more: bit.ly/42ZCs4z @DSaience](https://pbs.twimg.com/media/G4hhZ9BWwAASaYq.jpg)

























































































































United States Trends
- 1. Black Friday 457K posts
- 2. Nebraska 11.2K posts
- 3. Iowa 12.7K posts
- 4. Swift 55.9K posts
- 5. Lane Kiffin 8,359 posts
- 6. Rhule 2,343 posts
- 7. Jalon Daniels N/A
- 8. Black Ops 7 Blueprint 9,934 posts
- 9. Sumrall 3,245 posts
- 10. Go Birds 11.5K posts
- 11. Egg Bowl 7,647 posts
- 12. Kansas 16.5K posts
- 13. #Huskers 1,259 posts
- 14. #kufball N/A
- 15. Mississippi State 5,140 posts
- 16. Sydney Brown N/A
- 17. Kamario Taylor N/A
- 18. Ben Johnson 2,333 posts
- 19. #SoleRetriever N/A
- 20. UConn 5,452 posts
You might like
-
 Google DeepMind
Google DeepMind
@GoogleDeepMind -
 Hugging Face
Hugging Face
@huggingface -
 clem 🤗
clem 🤗
@ClementDelangue -
 Jim Fan
Jim Fan
@DrJimFan -
 François Chollet
François Chollet
@fchollet -
 Jan Leike
Jan Leike
@janleike -
 LangChain
LangChain
@LangChainAI -
 hardmaru
hardmaru
@hardmaru -
 Wojciech Zaremba
Wojciech Zaremba
@woj_zaremba -
 Aran Komatsuzaki
Aran Komatsuzaki
@arankomatsuzaki -
 Harrison Chase
Harrison Chase
@hwchase17 -
 Percy Liang
Percy Liang
@percyliang -
 elvis
elvis
@omarsar0 -
 Jerry Liu
Jerry Liu
@jerryjliu0 -
 Yi Tay
Yi Tay
@YiTayML
Something went wrong.
Something went wrong.