
青山依旧在,几度夕阳红 which means all heros and kings will die, no matter how great achievement they have made. This spirit maybe is influenced by buddism after Tang dynasty. Is this type of disillusionment Chinese culture unique ? Is there other culture with same spirit?


Reinforcement Learning of Large Language Models, Spring 2025(UCLA) Great set of new lectures on reinforcement learning of LLMs. Covers a wide range of topics related to RLxLLMs such as basics/foundations, test-time compute, RLHF, and RL with verifiable rewards(RLVR).



We're sharing the insights and the technical report behind Mem-Agent, our 4B model for persistent memory in LLMs. How we built it, the benchmarks, and why it works:


《智能体设计模式》中文翻译计划启动 接下来的一周,我将通过 AI 初次翻译 → AI 交叉评审 → 人工精读优化的方式来翻译这本书,所有翻译内容将持续更新到开源项目:github.com/ginobefun/agen… 本书由 Antonio Gulli 撰写、谷歌 Cloud AI 副总裁 Saurabh Tiwary 作序、高盛 CIO Marco Argenti…




正如设计模式曾是软件工程的圣经,这本由谷歌资深工程主管免费分享的《智能体设计模式》,正为火热的 AI Agent 领域带来首套系统性的设计原则与最佳实践。🔽


BTW, They released a deep dive on FP8 KVCache of main MLA. github.com/deepseek-ai/Fl… so, actually ≈1/5 compared to FP8 dense MLA.

As expected, NSA is not compatible with MLA, so DeepSeek chose another method: use a smaller (d=128) attention (w/o value) as the indexer. Asymptotic cost ratio = 128/576. In addition, indexer uses FP8 while main MLA uses 16-bit, so = 64/576 = 1/9.


Cool new blog post by Thinking machines: LoRA is all you need for SFT and RL, even for medium-sized post-training runs. Some highlights: Rank 64 or 128 seems to be very close to full FT in performance. Also interesting findings for how to set learning rates: The optimal FullFT…

LoRA makes fine-tuning more accessible, but it's unclear how it compares to full fine-tuning. We find that the performance often matches closely---more often than you might expect. In our latest Connectionism post, we share our experimental results and recommendations for LoRA.…


How does @deepseek_ai Sparse Attention (DSA) work? It has 2 components: the Lightning Indexer and Sparse Multi-Latent Attention (MLA). The indexer keeps a small key cache of 128 per token (vs. 512 for MLA). It scores incoming queries. The top-2048 tokens to pass to Sparse MLA.
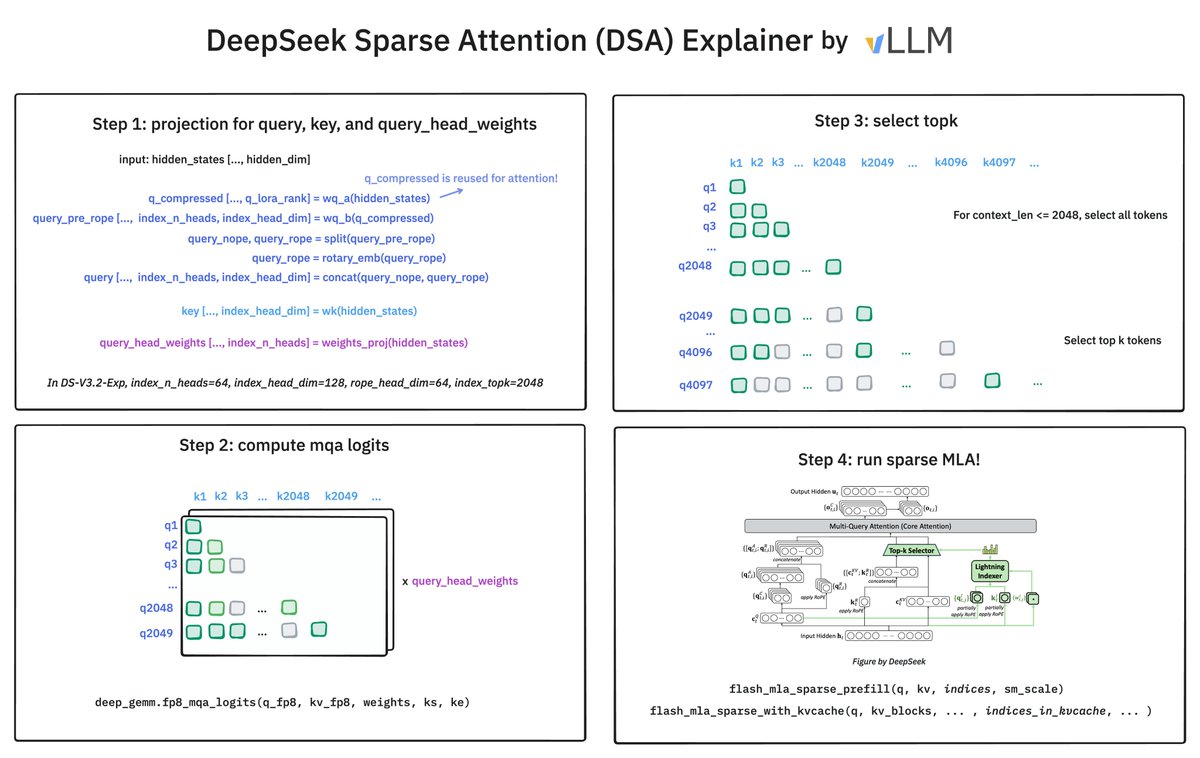

🚀 Introducing DeepSeek-V3.2-Exp — our latest experimental model! ✨ Built on V3.1-Terminus, it debuts DeepSeek Sparse Attention(DSA) for faster, more efficient training & inference on long context. 👉 Now live on App, Web, and API. 💰 API prices cut by 50%+! 1/n

ReasoningBank: memory for self-evolving LLM agents • Distills strategies from both successes & failures • Enables agents to learn, reuse, and improve over time • Outperforms prior memory methods on web & SWE tasks (+34.2% eff., –16% steps)


I quite enjoyed this and it covers a bunch of topics without good introductory resources! 1. A bunch of GPU hardware details in one place (warp schedulers, shared memory, etc.) 2. A breakdown/walkthrough of reading PTX and SASS. 3. Some details/walkthroughs of a number of other…

New in-depth blog post time: "Inside NVIDIA GPUs: Anatomy of high performance matmul kernels". If you want to deeply understand how one writes state of the art matmul kernels in CUDA read along. (Remember matmul is the single most important operation that transformers execute…


Introducing LLM.Q: Quantized LLM training in pure CUDA/C++! With LLM.Q, you can train your own LLM on consumer GPUs with natively quantized matmuls, on single workstations. No datacenter required. Inspired by @karpathy's llm.c, but natively quantized.
Today Thinking Machines Lab is launching our research blog, Connectionism. Our first blog post is “Defeating Nondeterminism in LLM Inference” We believe that science is better when shared. Connectionism will cover topics as varied as our research is: from kernel numerics to…


Some papers are timeless and "essential reading"! Understanding Integer Overflow in C/C++ users.cs.utah.edu/~regehr/papers…






The Ultimate Guide to Fine-Tuning LLMs. Here’s a 7-step roadmap that makes it simple. This technical report takes a deep look at the fine-tuning process for LLMs. Combining both theory and practice. 1. Introduction 2. Seven Stage Fine-Tuning Pipeline ↳ Stage-1: Data…

btw it's possible to use mantissa-free weights. The Chief Scientist of NVIDIA had a keynote with content about it. nvidia.com/en-us/on-deman…


Not sure if this is the case now but some miss that UE8M0 (Unsigned, Exponent 8, Mantissa 0) used for V3.1 is a microscaling data format. They're NOT using mantissa-free *weights*. It's just for large dynamic range, cheaply applied scale factors.


RL Is Neither a Panacea Nor a Mirage: Understanding Supervised vs. Reinforcement Learning Fine-Tuning for LLMs "RL primarily counteracts SFT-induced directional drift rather than finding new solutions. Our spectrum-aware analysis highlights inexpensive recovery knobs low-rank…


TogetherAI's Chief Scientist @tri_dao announced Flash Attention v4 at HotChips Conference which is up to 22% faster than the attention kernel implementation from NVIDIA's cuDNN library. Tri Dao was able to achieve this 2 key algorithmic changes. Firstly, it uses a new online…




I've written the full story of Attention Sinks — a technical deep-dive into how the mechanism was developed and how our research ended up being used in OpenAI's new OSS models. For those interested in the details: hanlab.mit.edu/blog/streaming…


just published a curated list of amazing blogs/articles on ai. highly selective. feel free to comment if you find anything interesting, will update it async. (link in replies)


































































































United States Trends
- 1. #AEWDynamite 23.5K posts
- 2. Epstein 1.28M posts
- 3. Skye Blue 2,776 posts
- 4. #Survivor49 2,124 posts
- 5. #AEWBloodAndGuts 3,354 posts
- 6. Cy Young 19.2K posts
- 7. Paul Skenes 13.6K posts
- 8. Raising Arizona N/A
- 9. Knicks 33.5K posts
- 10. Tarik Skubal 7,509 posts
- 11. Blood & Guts 15.9K posts
- 12. #ChicagoMed 1,341 posts
- 13. Savannah 5,684 posts
- 14. Starship 15.3K posts
- 15. Hannah Hidalgo 1,426 posts
- 16. #TheGoldenBachelor N/A
- 17. Igor 8,754 posts
- 18. Virginia Giuffre 71.2K posts
- 19. Gone in 60 1,026 posts
- 20. Megan Bayne 1,166 posts
Something went wrong.
Something went wrong.