
vLLM
@vllm_project
A high-throughput and memory-efficient inference and serving engine for LLMs. Join http://slack.vllm.ai to discuss together with the community!
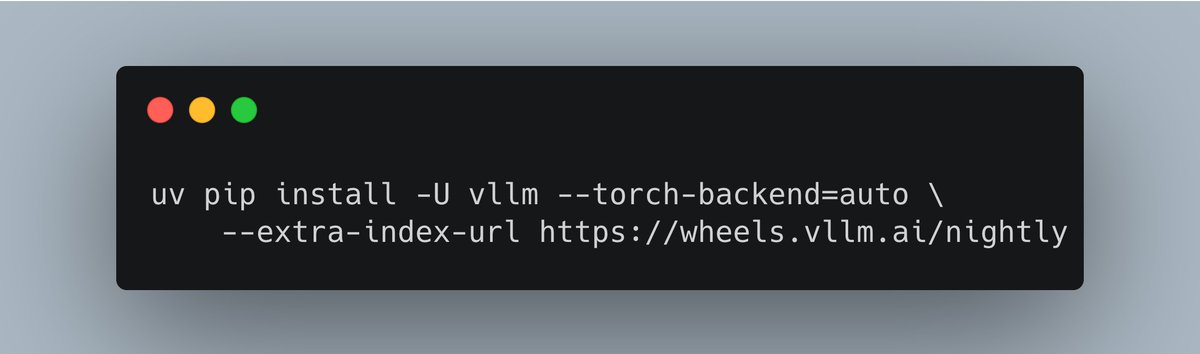
🚀 vLLM now offers an optimized inference recipe for DeepSeek-V3.2. ⚙️ Startup details Run vLLM with DeepSeek-specific components: --tokenizer-mode deepseek_v32 \ --tool-call-parser deepseek_v32 🧰 Usage tips Enable thinking mode in vLLM: –…


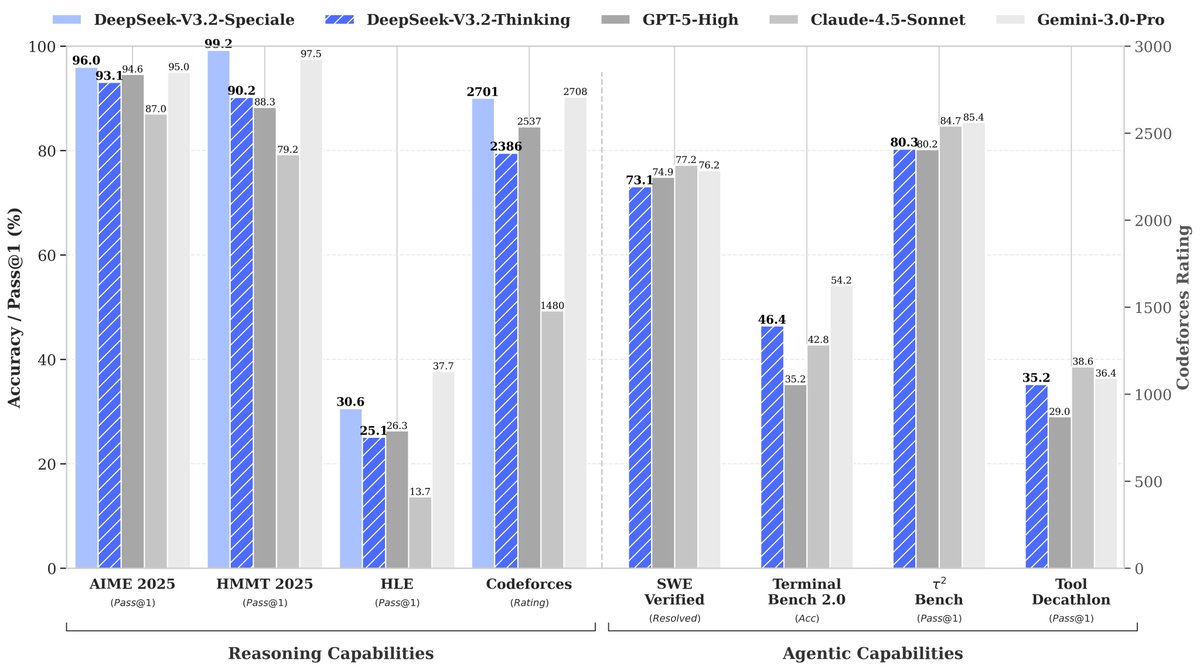
🚀 Launching DeepSeek-V3.2 & DeepSeek-V3.2-Speciale — Reasoning-first models built for agents! 🔹 DeepSeek-V3.2: Official successor to V3.2-Exp. Now live on App, Web & API. 🔹 DeepSeek-V3.2-Speciale: Pushing the boundaries of reasoning capabilities. API-only for now. 📄 Tech…
We’re taking CUDA debugging to the next level. 🚀 Building on our previous work with CUDA Core Dumps, we are releasing a new guide on tracing hanging and complicated kernels down to the source code. As kernels get more complex (deep inlining, async memory access), standard…

Have you ever felt you are developing cuda kernels and your tests often run into illegal memory access (IMA for short) and you have no idea how to debug? We have collaborated with the @nvidia team to investigate how cuda core dump can help, check out the blogpost to learn more!…
🤝 Proud to share the first production-ready vLLM plugin for Gaudi, developed in close collaboration with the Intel team and fully aligned with upstream vLLM. 🔧 This release is validated and ready for deployment, with support for the latest vLLM version coming soon. 📘 The…

LLM agents are powerful but can be slow at scale. @Snowflake's model-free SuffixDecoding from Arctic Inference now runs natively in vLLM, beating tuned N-gram speculation across concurrency levels while keeping CPU and memory overhead in check. Quick Start in vLLM:…

Suffix Decoding is at #NeurIPS2025 as a 🏅spotlight! It accelerates LLM inference for coding, agents, and RL. We also optimized its speculation speed by 7.4x and merged it into vLLM (incoming to SGLang). Talk to @GabrieleOliaro or me at poster #816 Friday 11am! Links in🧵

🎉 Congratulations to the Mistral team on launching the Mistral 3 family! We’re proud to share that @MistralAI, @NVIDIAAIDev, @RedHat_AI, and vLLM worked closely together to deliver full Day-0 support for the entire Mistral 3 lineup. This collaboration enabled: • NVFP4…

Introducing the Mistral 3 family of models: Frontier intelligence at all sizes. Apache 2.0. Details in 🧵

More inference workloads now mix autoregressive and diffusion models in a single pipeline to process and generate multiple modalities - text, image, audio, and video. Today we’re releasing vLLM-Omni: an open-source framework that extends vLLM’s easy, fast, and cost-efficient…

Transformers v5's first release candidate is out 🔥 The biggest release of my life. It's been five years since the last major (v4). From 20 architectures to 400, 20k daily downloads to 3 million. The release is huge, w/ tokenization (no slow tokenizers!), modeling & processing.

Love this: a community contributor built vLLM Playground to make inferencing visible, interactive, and experiment-friendly. From visual config toggles to automatic command generation, from GPU/M-chip support to GuideLLM benchmarking + LLMCompressor integration — it brings the…
vLLM is proud to support @PrimeIntellect 's post-training of the INTELLECT-3 model🥰

Introducing INTELLECT-3: Scaling RL to a 100B+ MoE model on our end-to-end stack Achieving state-of-the-art performance for its size across math, code and reasoning Built using the same tools we put in your hands, from environments & evals, RL frameworks, sandboxes & more

Interested in how NVIDIA Nemotron-H is being optimized for high performance inference in @vllm_project? Join @RedHat and @NVIDIAAI next week as we cover the Nemotron-H architecture, vLLM support, optimized MoE kernels, async scheduling, and new nsys profiles. Join links below 👇


Wide-EP and prefill/decode disaggregation APIs for vLLM are now available in Ray 2.52 🚀🚀 Validated at 2.4k tokens/H200 on Anyscale Runtime, these patterns maximize sparse MoE model inference efficiency, but often require non-trivial orchestration logic. Here’s how they…
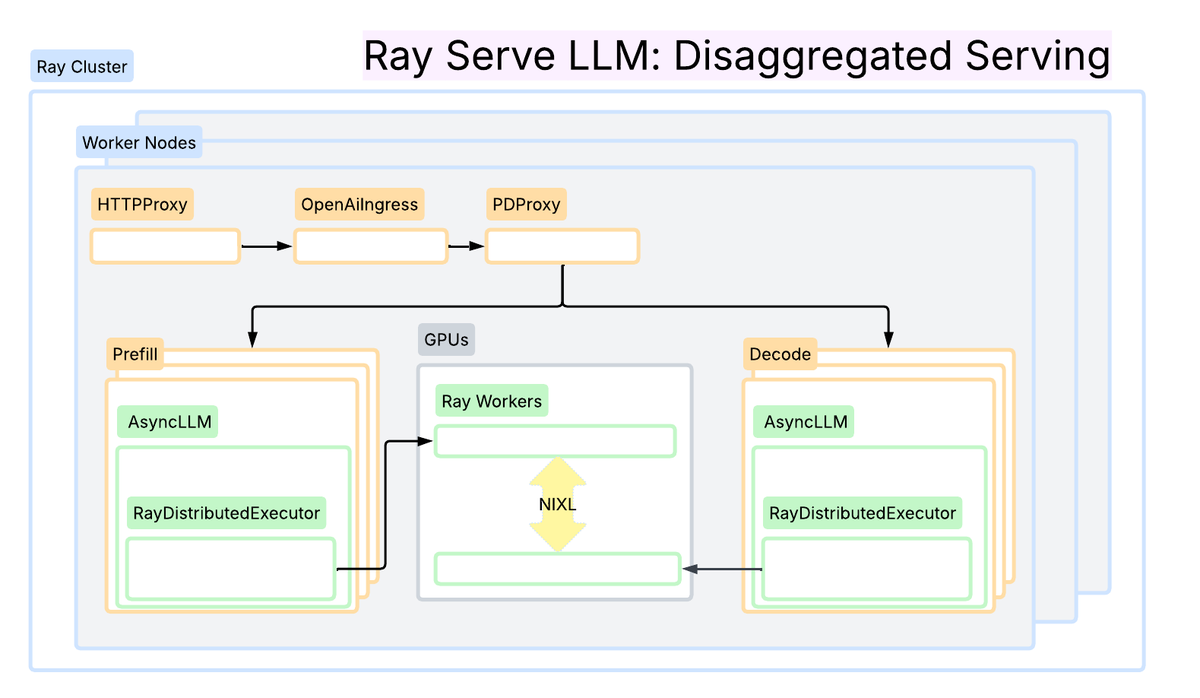
Running multi-node vLLM on Ray can be complicated: different roles, env vars, and SSH glue to keep things together. The new `ray symmetric-run` command lets you run the same entrypoint on every node while Ray handles cluster startup, coordination, and teardown for you. Deep…
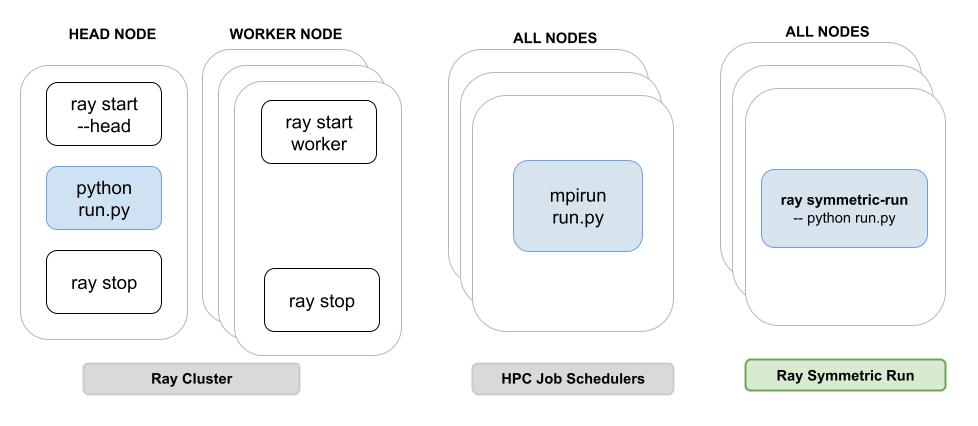
In 2.52, we're introducing ray symmetric-run -- a CLI command to simplify and improve the large model interactive development experience on Ray and @vllm_project! Spinning up multi-node vLLM with Ray on interactive environments can be tedious, requiring users to juggle separate…

📸 Scenes from the Future of Inferencing! PyTorch ATX, the @vllm_project community, and @RedHat brought together 90+ AI builders at Capital Factory back in September, to dive into the latest in LLM inference -> from quantization and PagedAttention to multi-node deployment.…


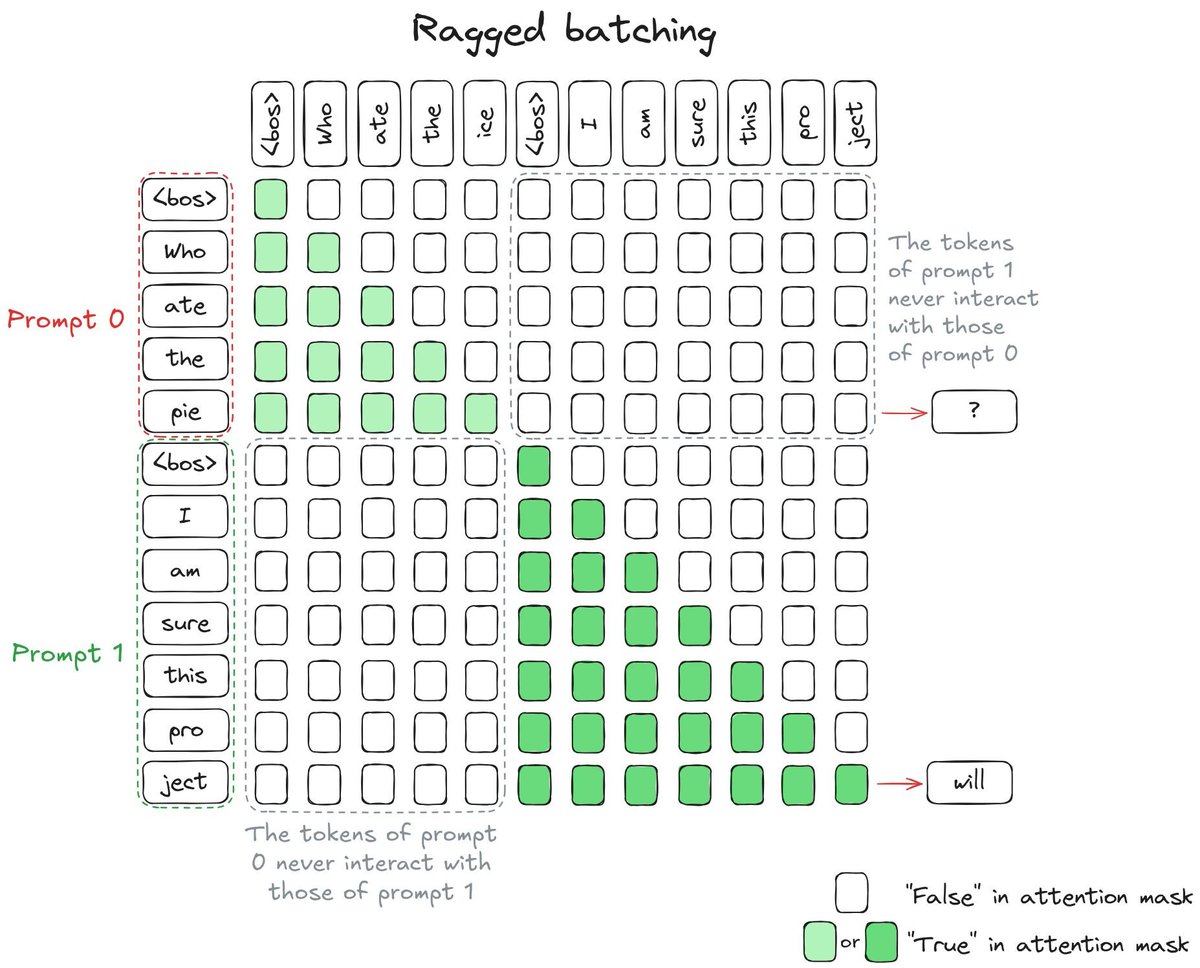
An amazing blog post dropped on @huggingface explaining how today's LLM inference engines like @vllm_project work! The concept of "continuous batching" is explained, along with KV-caching, attention masking, chunked prefill, and decoding. Continuous batching is the idea of…




































































United States Xu hướng
- 1. FIFA 301K posts
- 2. Paraguay 25.4K posts
- 3. Argentina 210K posts
- 4. Brazil 71.7K posts
- 5. Croatia 21.5K posts
- 6. Portugal 92.5K posts
- 7. FINALLY DID IT 426K posts
- 8. Matt Campbell 10.3K posts
- 9. Group L 15.4K posts
- 10. #USMNT 1,317 posts
- 11. Infantino 65.4K posts
- 12. Ghana 75.7K posts
- 13. Iowa State 8,848 posts
- 14. Warner Bros 227K posts
- 15. Wayne Gretzky 3,857 posts
- 16. Norway 29.7K posts
- 17. Senegal 45K posts
- 18. Hep B 14K posts
- 19. #Mundial2026 35.2K posts
- 20. Frank Gehry 2,065 posts
Something went wrong.
Something went wrong.