
Just open-sourced Lorata, a new data labeling tool for the GenAI era. You can now easily prepare training data for the text-to-image, image-editing models, and more!✨ An image editor with drawing and cropping tools is also built-in!
Supported trimming multiple video segments! You can easily create LoRA datasets for training video models like @Alibaba_Wan Wan 2.2 and @character_ai Ovi✨
Added video trimming support for video labeling tasks! Btw, GPT-5 with high reasoning is so strong that it solves most of the non-trivial tasks that other models can't handle, <3

We just hit the top of the Hugging Face trend list with two models! 🏆 🔹HunyuanImage 3.0: The largest and most powerful open-source text-to-image model to date with over 80 billion parameters. The performance is comparable to industry flagship closed-source models.…

Now you can easily create training data for @Alibaba_Qwen Qwen-Image-Edit-2509 in Lorata, and export dataset to @ostrisai's AI Toolkit for training! Everything runs on your local machine👀 Btw, the target image here is also generated using Qwen Image Edit, pretty nice quality✨
Just open-sourced Lorata, a new data labeling tool for the GenAI era. You can now easily prepare training data for the text-to-image, image-editing models, and more!✨ An image editor with drawing and cropping tools is also built-in!
Supported generating caption for images/videos using local/cloud vision language models✨ The video frames will be automatically extracted for captioning

Added video trimming support for video labeling tasks! Btw, GPT-5 with high reasoning is so strong that it solves most of the non-trivial tasks that other models can't handle, <3
Added video trimming support for video labeling tasks! Btw, GPT-5 with high reasoning is so strong that it solves most of the non-trivial tasks that other models can't handle, <3
Just open-sourced Lorata, a new data labeling tool for the GenAI era. You can now easily prepare training data for the text-to-image, image-editing models, and more!✨ An image editor with drawing and cropping tools is also built-in!
Supported labeling text-to-video and image-to-video data now And you can export the videos with different FPS too
Just open-sourced Lorata, a new data labeling tool for the GenAI era. You can now easily prepare training data for the text-to-image, image-editing models, and more!✨ An image editor with drawing and cropping tools is also built-in!
Google/GitHub search often fails to find desired repositories, so I'm building one But naively indexing README with an embedding model doesn't work well Gonna try LLM rephrasing before indexing and reranking with an LLM or reranking model

Made this GitHub repo explorer with just a single prompt in Windsurf, and yeah, it is mobile responsive

Using cheap LLMs to index and retrieve PDF content can be a good alternative to vector embedding for RAG My flow: 1. Parse PDF with Mistral OCR 2. Summarize each page with Gemini 2.5 Flash 3. Retrieve relevant pages with Gemini 2.5 Flash 4. Answer question with Claude 3.7 Sonnet


















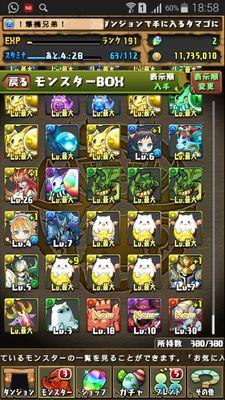



















































United States 트렌드
- 1. Eagles 145K posts
- 2. Lions 73.6K posts
- 3. Goff 15.6K posts
- 4. Dan Campbell 8,933 posts
- 5. Jalen 29.7K posts
- 6. Gibbs 7,207 posts
- 7. Chiefs 88.3K posts
- 8. #OnePride 5,013 posts
- 9. AJ Brown 7,404 posts
- 10. Nakobe Dean 1,328 posts
- 11. Broncos 64.3K posts
- 12. Kevin Patullo 5,290 posts
- 13. Adoree Jackson 1,999 posts
- 14. Collinsworth 2,175 posts
- 15. #DETvsPHI 3,194 posts
- 16. Vic Fangio 2,473 posts
- 17. Shedeur 51.2K posts
- 18. Jamo 4,211 posts
- 19. Sirianni 3,196 posts
- 20. NFC North 3,970 posts
Something went wrong.
Something went wrong.