
Safe Autonomous Systems Lab
@SASlabUCSD
The Safe Autonomous Systems Lab @UCSanDiego
Congratulations to our students Marfred Barrera for receiving the NSF GRFP and Hyun Joe Jeong for receiving an Honorable Mention!
Will Sharpless’ paper, titled Linear Supervision for Nonlinear, High-Dimensional Neural Control and Differential Games, was nominated for Best Paper at @l4dc_conf! Link: arxiv.org/pdf/2412.02033
We had the pleasure to host David Fridovich-Keil in MAE 248 who talked about “Dynamic game theory in multi-agent interactive settings”. youtu.be/DCcj4SqlVNk
youtube.com
YouTube
David Fridovich-Keil - Dynamic game theory in multi-agent interactive...
Our first guest lecturer this year in MAE 248 was Mansur Maturidi Arief, who presented on machine learning, optimization, and sample-efficient simulation methods to assist scalable decision-making tasks that consider risks of catastrophic failure events. youtu.be/16X62Ss-fPA?si…
youtube.com
YouTube
Mansur M Arief - Scalable decision-making validation under catastro...
Join project with @natanaso and Prof. Cortés got highlighted in @TechXplore_com techxplore.com/news/2024-06-m…
techxplore.com
A method to enable safe mobile robot navigation in dynamic environments
To successfully complete missions in dynamic and unstructured real-world environments, mobile robots should be able to adapt their actions in real-time to avoid collisions with nearby objects, people...
🚨📄New paper: arxiv.org/abs/2404.02472 Real-time navigation in a priori unknown environment remains a challenging task, especially when an unexpected disturbance occurs. In this letter, we propose the framework Safe Returning Fast and Safe Tracking to tackle this problem.
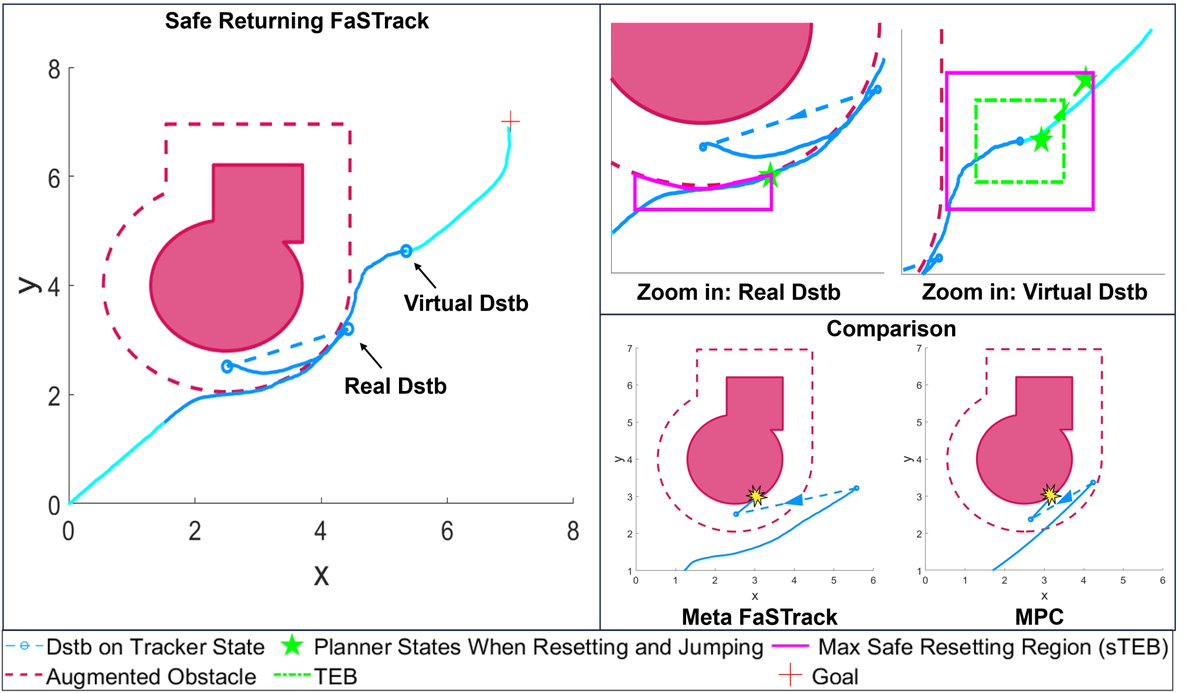
Our team had the pleasure of attending #L4DC2024 and #RSS2024, where we presented our latest research and engaged in insightful discussions.




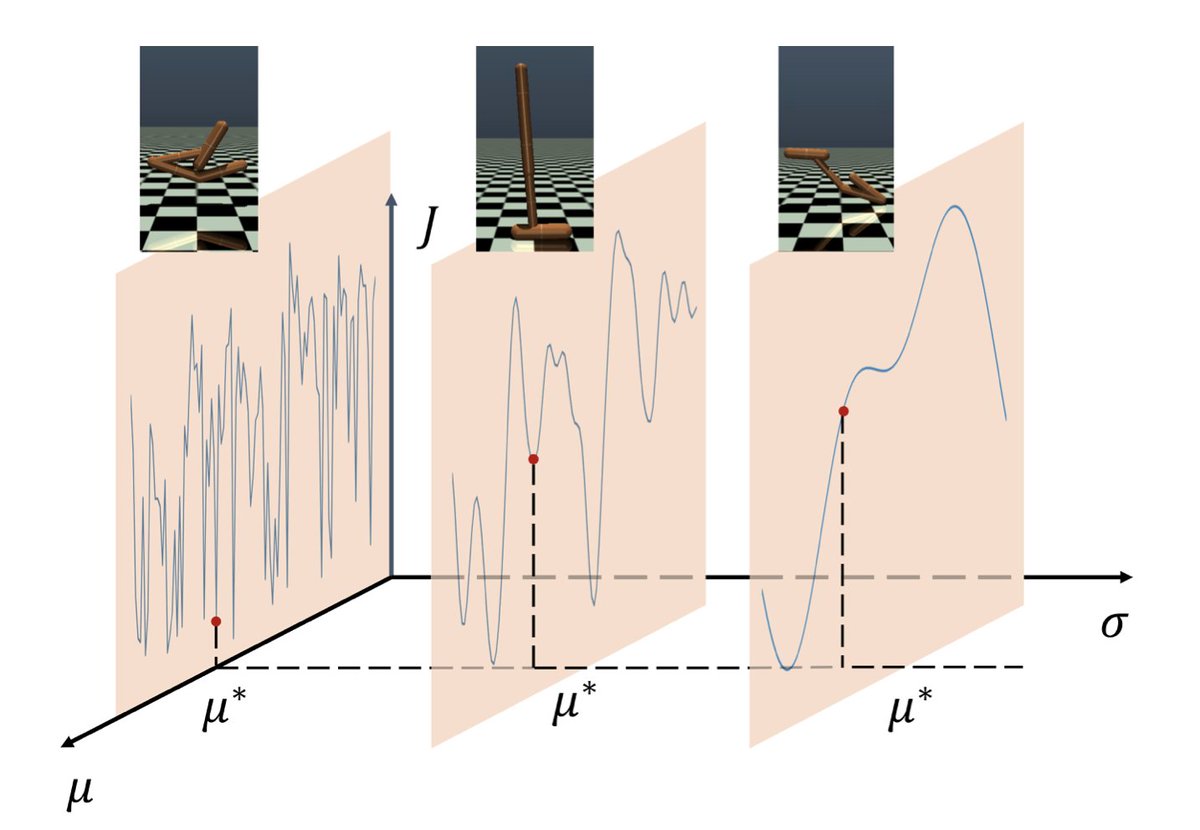
🚨📄New paper accepted to ICML: arxiv.org/pdf/2405.17832 This paper shows how policy gradient methods can be reformulated using the heat equation from physics, providing insight on how policy gradient methods mollify (smooth) the optimization landscape. Joint work with Prof. Gao
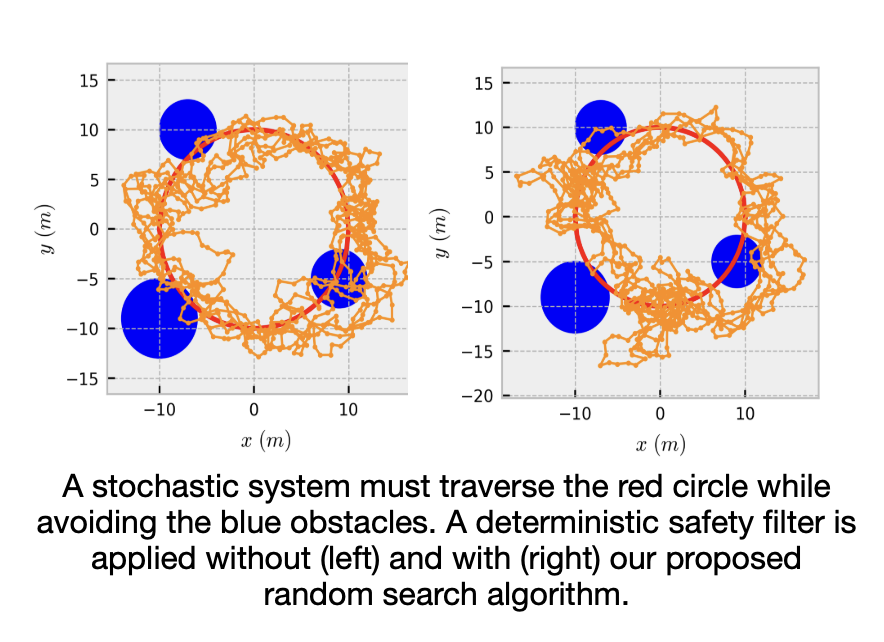
🚨📄New paper: arxiv.org/pdf/2309.08767 This paper explores how to generalize a deterministic safe control policy (from, for example, a control barrier function) to stochastic systems with partial state observation.
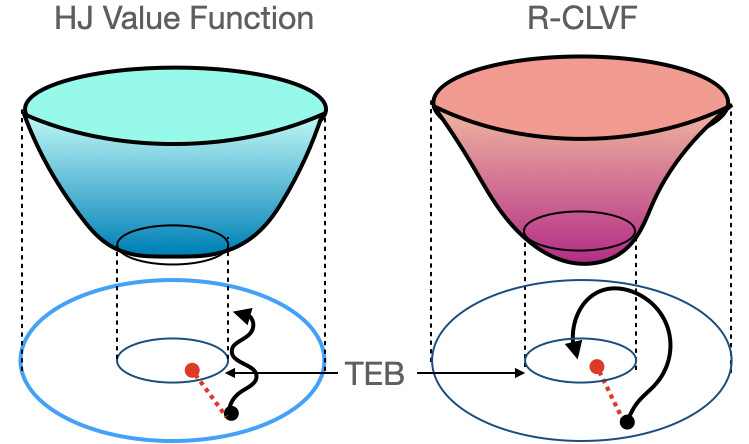
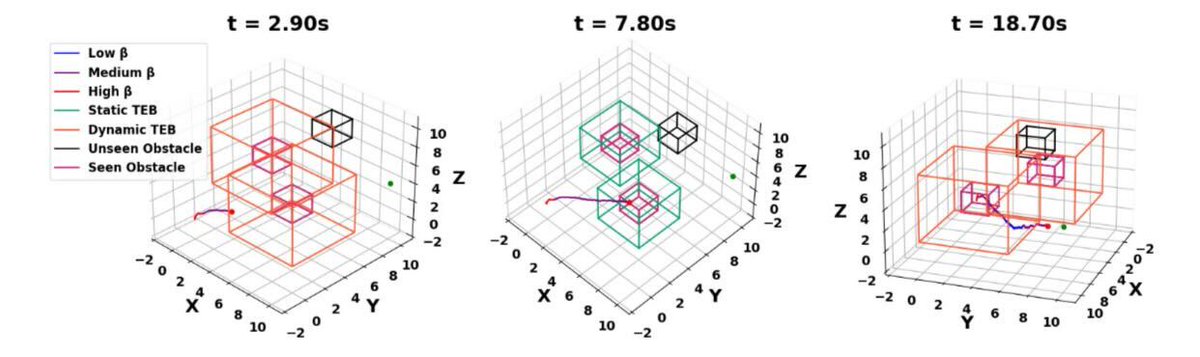
🚨📄New paper: arxiv.org/abs/2404.07431 This paper leverages DeepReach to adapt its planning algorithm in real time: In open environments the algorithm plans with a faster speed, and in narrow environment it slows down by querying its distance from obstacles.
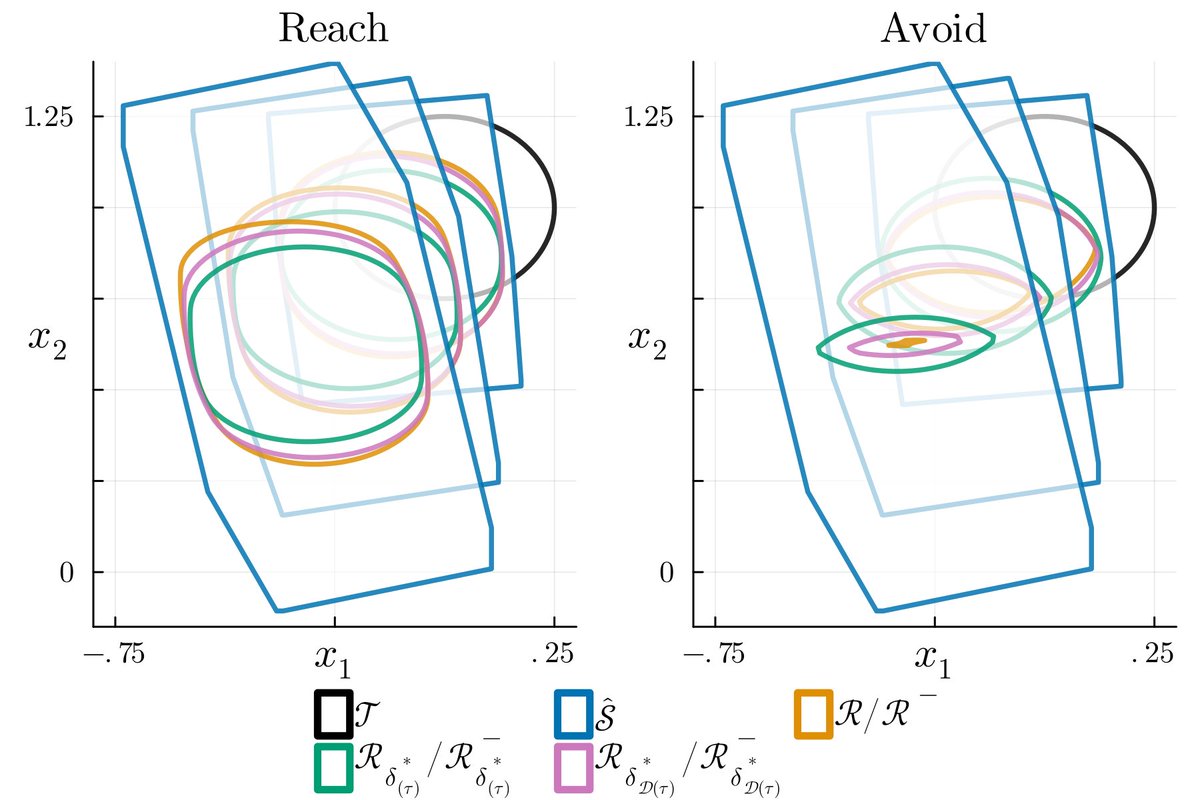
🚨📄New paper: arxiv.org/abs/2403.16982 In this paper, we make accurate, safe & dimension-robust HJR appxs via state-augmention with a smooth lift (eg Poly, RBF, NN). Lifted, linear models have vanishing error in the limit & yet may be rapidly solved by the Hopf formula.
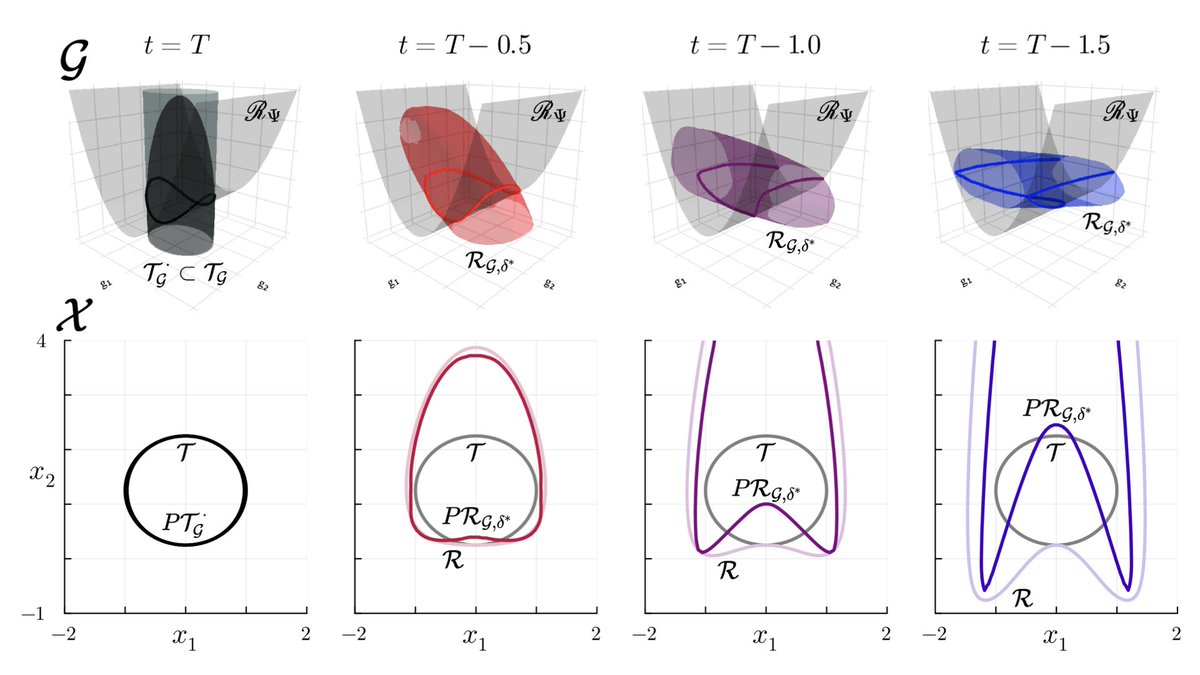
🚨📄New paper: arxiv.org/abs/2403.14184 In this paper, we make safe envelopes of nonlinear HJR games with linear models and “antagonistic error”, allowing safe Hopf-based solutions that avoid the curse of dimensionality. This yields controllers robust to disturbance and error!








































United States Trends
- 1. Happy Thanksgiving Eve 2,751 posts
- 2. Good Wednesday 24.7K posts
- 3. Colorado State 2,919 posts
- 4. #wednesdaymotivation 3,933 posts
- 5. Jim Mora 1,260 posts
- 6. #Wednesdayvibe 1,915 posts
- 7. Nuns 6,763 posts
- 8. Luka 67.5K posts
- 9. Hump Day 8,947 posts
- 10. Lakers 52.9K posts
- 11. Clippers 19.5K posts
- 12. Collar 46.9K posts
- 13. Kris Dunn 3,065 posts
- 14. Karoline Leavitt 25K posts
- 15. Periods 13.8K posts
- 16. The God 408K posts
- 17. Shirt 73.2K posts
- 18. Witkoff 172K posts
- 19. Bayern 86.3K posts
- 20. Check Analyze 3,373 posts
Something went wrong.
Something went wrong.