
Zhiyong Wang
@Zhiyong16403503
Postdoc at Edinburgh, Ph.D. at CUHK. Former Visiting Scholar at Cornell. Working on reinforcement learning and multi-armed bandits.

i knew it was probably time to graduate when one of my papers was described as a "classical result" 🤣. jokes aside, should be an excellent watch!

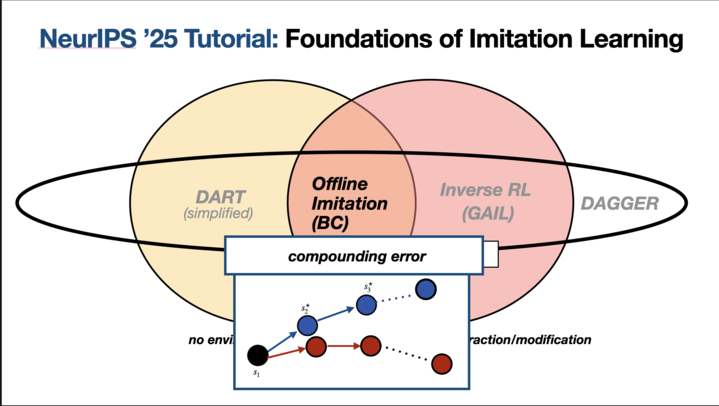
Happening this Tuesday 1:30 PST @ NeurIPS: Foundations of Imitation Learning: From Language Modeling to Continuous Control A tutorial with Adam Block & Max Simchowitz (@max_simchowitz).


🧐🧐 Why do we pretrain LLMs with log likelihood? Why does action chunking work so well in robotics? Why is EMA so ubiquitous? And could their be a mathematical basis for Moravec’s paradox? 🤖🤖 Come check out our NeurIPS 2025 Tutorial “Foundations of Imitation Learning” with…

At #NeurIPS2025? Join us for a Social on Wednesday at 7 PM, featuring a fireside chat with Jon Kleinberg and mentoring tables. Ft. mentors @canondetortugas @SurbhiGoel_ @HamedSHassani @tatsu_hashimoto @andrew_ilyas @chijinML @thegautamkamath @MountainOfMoon + more!


I’ll be at #neurips2025 🚀 presenting A*-PO! 📍 Exhibit Hall C,D,E 🗓️ Wed Dec 3, 11:00 a.m. – 2:00 p.m. PST 📌 arxiv.org/abs/2505.20686 Happy to chat!
Current RLVR methods like GRPO and PPO require explicit critics or multiple generations per prompt, resulting in high computational and memory costs. We introduce ⭐A*-PO, a policy optimization algorithm that uses only a single sample per prompt during online RL without critic.


I’m recruiting several PhD students at Carnegie Mellon University! If you’re interested in LLM reasoning, agents, or diffusion language models, consider applying to the CMU ECE PhD program. Applications are due Dec 15. ece.cmu.edu/admissions/gra…

I’m excited to be joining UT Austin CS as an assistant professor in Fall 2026! I’ll be building a research group at the intersection of theory & ML and am recruiting this cycle — if you’re interested in working with me, please apply (deadline is Dec 15): cs.utexas.edu/graduate-progr…
As good a time as any to announce I'm on the job market this year! I develop provably efficient reinforcement learning algorithms that are directly applicable to problems across both robotics and language modeling. See gokul.dev for more!

Announcing (w Adam Smith and @thejonullman) the 2025 edition of the Foundations of Responsible Computing Job Market Profiles! Check out 40 job market candidates (for postdoc, industry, and faculty positions) in mathematical research in computation and society writ large! 1/3


🤖 Robots rarely see the true world's state—they operate on partial, noisy visual observations. How should we design algorithms under this partial observability? Should we decide (end-to-end RL) or distill (from a privileged expert)? We study this trade-off in locomotion. 🧵(1/n)

Excited to announce our NeurIPS ’25 tutorial: Foundations of Imitation Learning: From Language Modeling to Continuous Control With Adam Block & Max Simchowitz (@max_simchowitz)

MSR NYC is hiring spring and summer interns in AI/ML/RL!


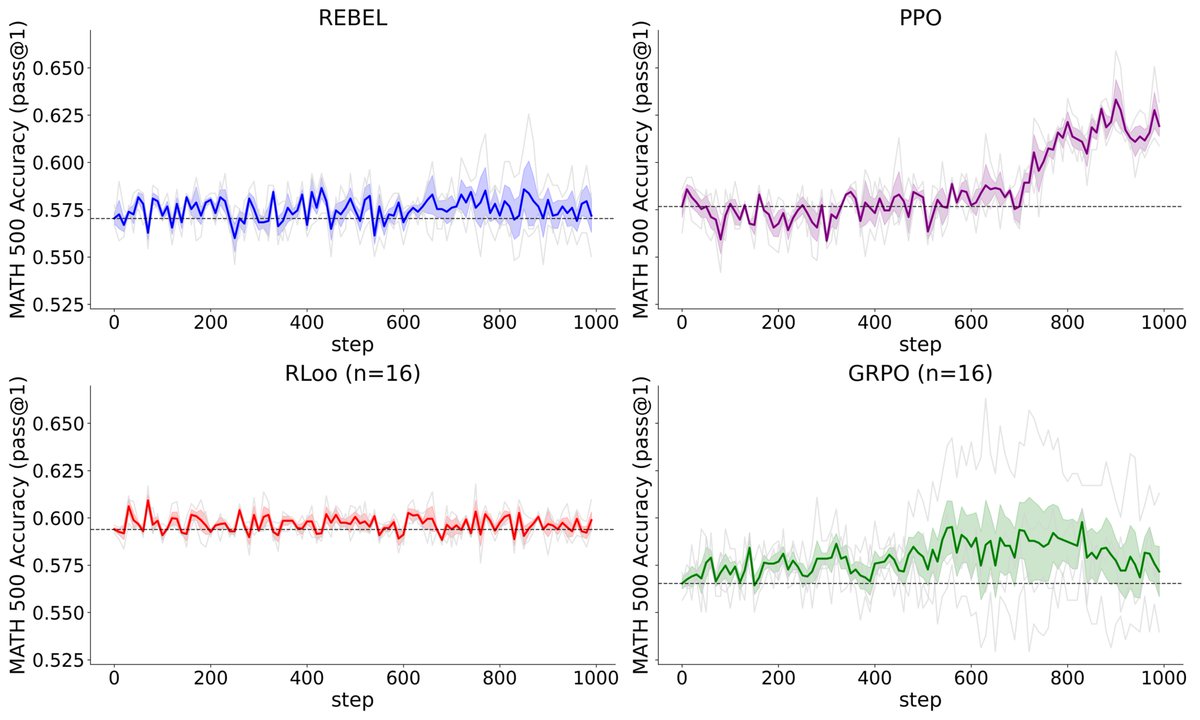
New in the #DeeperLearningBlog: @GaoZhaolin and collaborators including the #KempnerInstitute's Kianté Brantley presents a powerful new #RL algorithm tailored for reasoning tasks with #LLMs that updates using only one generation per prompt. bit.ly/44US1Mt @xkianteb #AI
![KempnerInst's tweet card. Recent LLM advances show the effectiveness of RL with rule-based rewards, but methods like GRPO and PPO are costly due to critics or multiple generations per prompt. We propose a […]](https://pbs.twimg.com/card_img/1994400968541097984/eAf3Q9zw?format=png&name=orig)

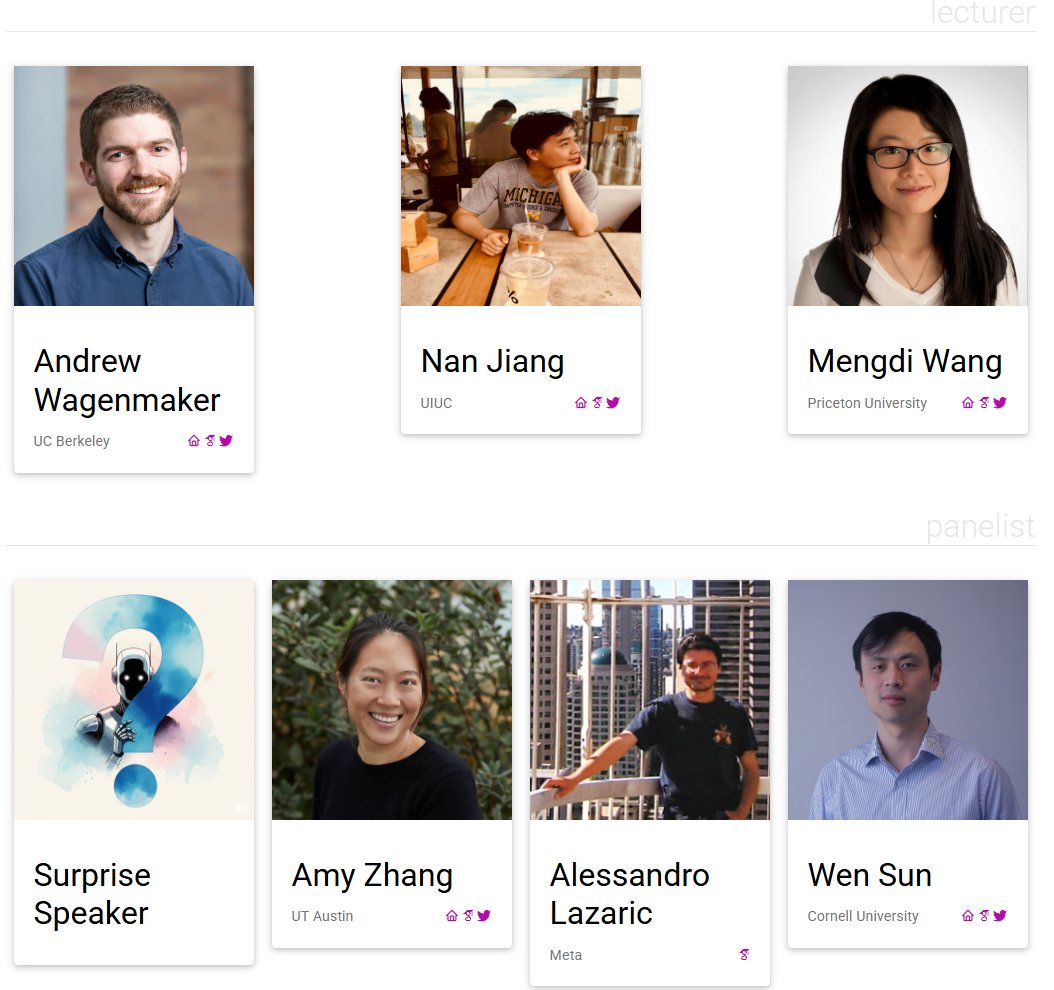
Delighted to announce that the 2nd edition of our workshop has been accepted to #NeurIPS2025! We have an amazing lineup of speakers: @WenSun1, @ajwagenmaker, @yayitsamyzhang, @MengdiWang10, @nanjiang_cs, Alessandro Lazaric, and a special guest!

How can small LLMs match or even surpass frontier models like DeepSeek R1 and o3 Mini in math competition (AIME & HMMT) reasoning? Prior work seems to suggest that ideas like PRMs do not really work or scale well for long context reasoning. @kaiwenw_ai will reveal how a novel…

I’m presenting two papers on value-based RL for post-training & reasoning on Friday at @ai4mathworkshop at #ICML2025! 1️⃣ Q#: lays theoretical foundations for value-based RL for post-training LMs; 2️⃣ VGS: practical value-guided search scaled up for long CoT reasoning. 🧵👇
Happy to share our work "Provable Zero-Shot Generalization in Offline Reinforcement Learning" at ICML 2025! 📍 Poster | 🗓️July 16, 11:00 AM – 1:30 PM 📌 West Exhibition Hall B2-B3 #W-1012 🤖 How can offline RL agents generalize zero-shot to unseen environments? We introduce…
Does RL actually learn positively under random rewards when optimizing Qwen on MATH? Is Qwen really that magical such that even RLing on random rewards can make it reason better? Following prior work on spurious rewards on RL, we ablated algorithms. It turns out that if you…
Recent work has seemed somewhat magical: how can RL with *random* rewards make LLMs reason? We pull back the curtain on these claims and find out this unexpected behavior hinges on the inclusion of certain *heuristics* in the RL algorithm. Our blog post: tinyurl.com/heuristics-con…

Curious how to combine federated learning and in-context learning for QA tasks — with privacy preservation, efficiency, and boosting performance round by round? 🚀 Meet Fed-ICL — our framework collaboratively refines answers without transmitting model weights or sharing raw…

Tired of over-optimized generations that stray too far from the base distribution? We present SLCD: Supervised Learning based Controllable Diffusion, which (provably) solves the KL constrained reward maximization problem for diffusion through supervised learning! (1/n)


by incorporating self-consistency during offline RL training, we unlock three orthogonal directions of scaling: 1. efficient training (i.e. limit backprop through time) 2. expressive model classes (e.g. flow matching) 3. inference-time scaling (sequential and parallel) which,…


I won't be at #ICLR2025 myself this time around but please go talk to lead authors @nico_espinosa_d, @GaoZhaolin, and @runzhe_wu about their bleeding-edge algorithms for imitation learning and RLHF!































































































United States Trends
- 1. Good Thursday 24.4K posts
- 2. rUSD N/A
- 3. #DMDCHARITY2025 1.46M posts
- 4. Earl Campbell 2,181 posts
- 5. Halle Berry 3,562 posts
- 6. Steve Cropper 7,693 posts
- 7. #ALLOCATION 706K posts
- 8. The BIGGЕST 1.1M posts
- 9. #JUPITER 228K posts
- 10. #TusksUp N/A
- 11. #LifeAITestnet 6,734 posts
- 12. Market Focus 4,652 posts
- 13. Milo 12.7K posts
- 14. Mike Lindell 24.4K posts
- 15. seokjin 166K posts
- 16. Jamal Murray 8,203 posts
- 17. Metroid Prime 4 15.3K posts
- 18. Cafe 169K posts
- 19. #TheChallenge41 2,266 posts
- 20. #Survivor49 3,001 posts
Something went wrong.
Something went wrong.