
KeepCurrent
@_keepcurrent
We organize #meetups, #hackathons and conduct #tailormade #trainings and #workshops for companies: #MachineLearning #MLOps, #DataScience & #SoftwareDevelopment.
You might like




Do you like yellow? Then, according to LLMs, you are probably a school bus driver! Excited to share our new paper about Semantic Leakage in Language Models! Joint work with my wonderful collaborators @terra @alisawuffles @luke @nlpnoah Paper: gonenhila.github.io/files/Semantic… 1/10


Probably the craziest week in Open Source AI (yet): 1. Mistral (in collaboration with Nvidia) dropped Apache 2.0 licensed NeMo 12B LLM, better than L3 8B and Gemma 2 9B. Models are multilingual with 128K context and a highly efficient tokenizer - tekken. 2. Apple released DCLM…

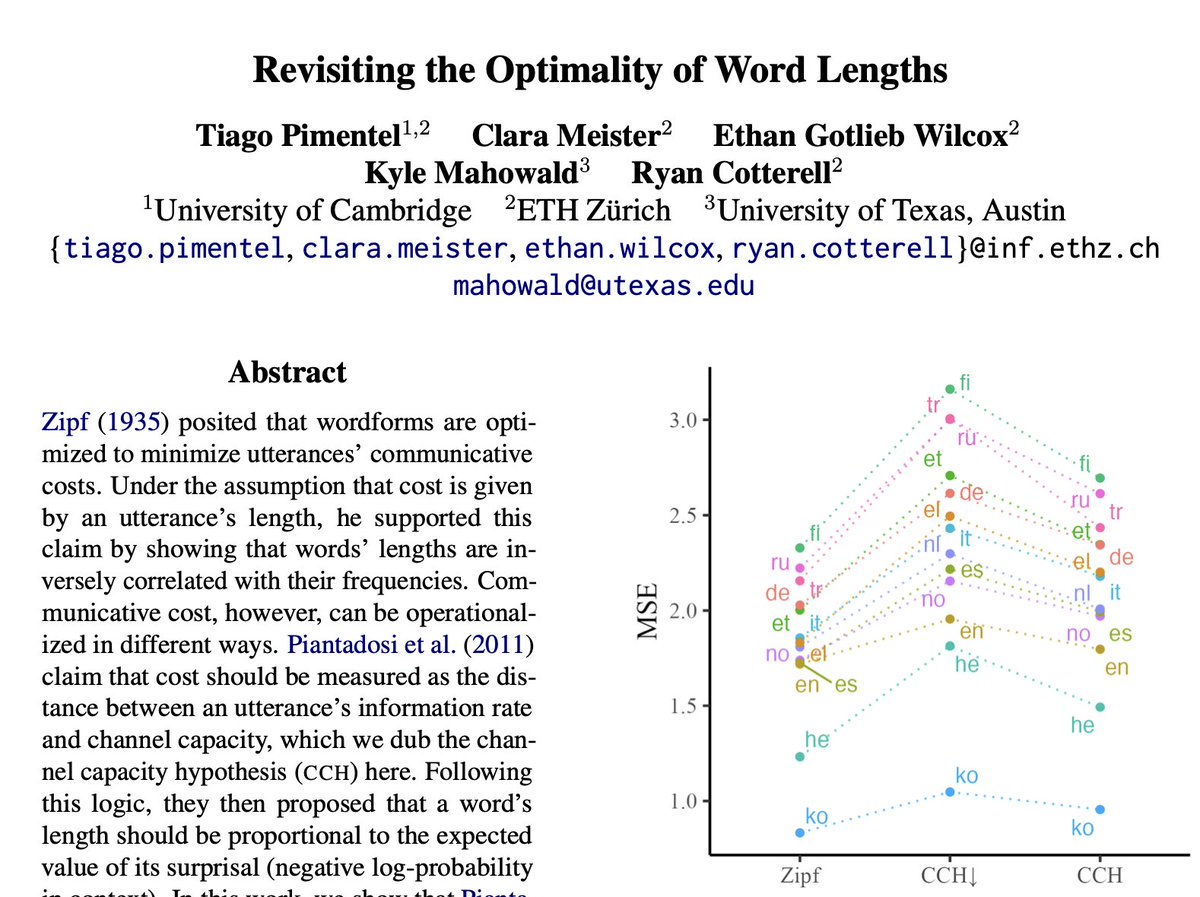
Are you interested in word lengths and natural language’s efficiency? If yes, our new #EMNLP2023 paper has everything you need: drama, suspense, a new derivation of Zipf’s law, an update to Piantadosi et al’s classic word length paper, transformers... 🧵 arxiv.org/abs/2312.03897

You don’t have to train from scratch whenever developing a smaller model of an existing model family. Sharing our latest work - “Initializing Models with Larger Ones” arxiv preprint: arxiv.org/abs/2311.18823 code: github.com/OscarXZQ/weigh…


🎉Excited to announce our paper's acceptance at #EMNLP2023! We explore a fascinating question: When faced with (un)answerable queries, do LLMs actually grasp the concept of (un)answerability?🧐 This work is a collaborative effort with @clu_avi @ravfogel @omerNLP and Ido Dagan 1/n

There is a paper by Google trending right now, that claims transformer in-context learning cannot generalize between two function classes I have reproduced their experiment in a colab and come to a very different conclusion...


ACL org announcement: 📢The list of accepted workshops in the ACL Conferences (@aclmeeting, @eaclmeeting, @naaclmeeting, @emnlpmeeting) in 2024 is out! Please help spread the word. Retweeting w/ references, esp. w/organisers information is very much appreciated - thanks! #NLProc

Pandas 2.0 is here! This is the biggest overhaul of Pandas since its inception, and it has been years in the making. However, you will probably not notice too many changes, and all your existing Pandas code will most likely run the same as before. All the major changes are under…


Psychologists have posited hundreds of cognitive biases over the years. A new paper argues that they all boil down to one of a handful of fundamental beliefs coupled with confirmation bias. doi.org/10.1177/174569…


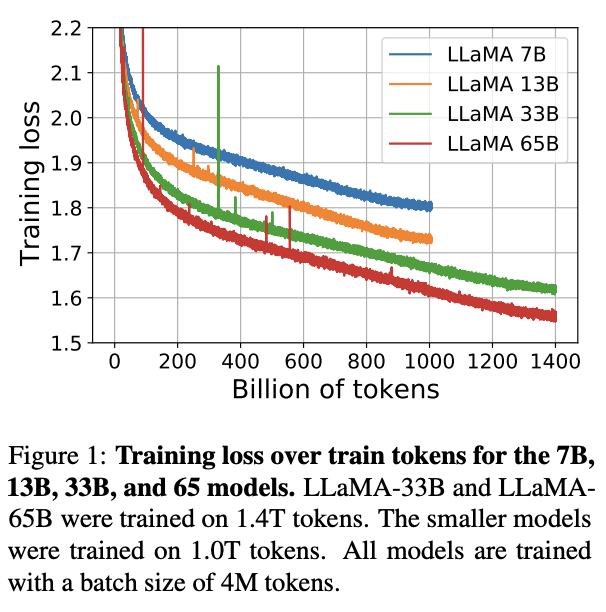
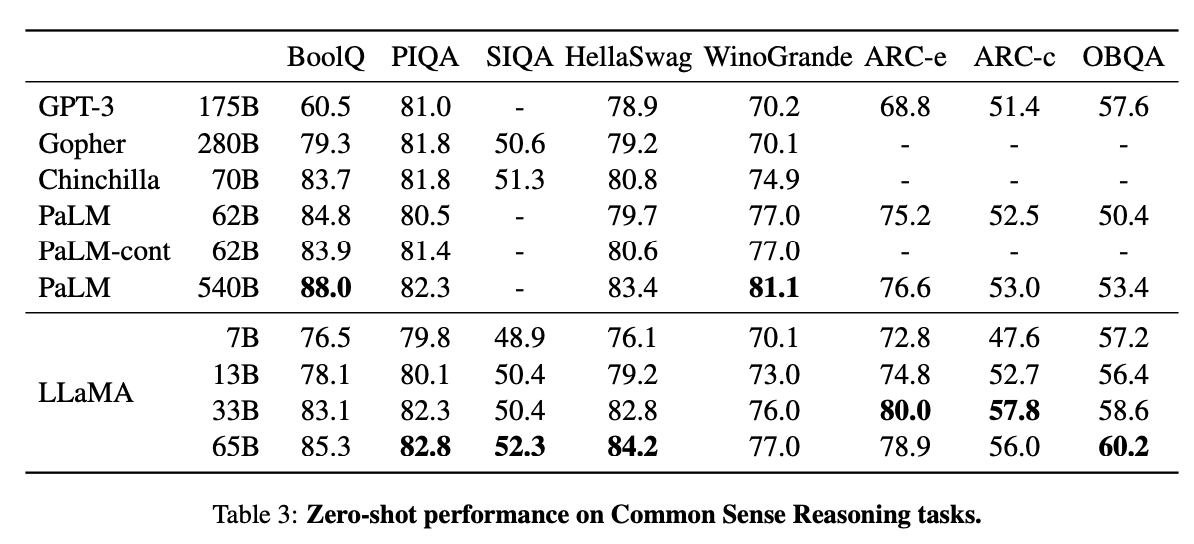
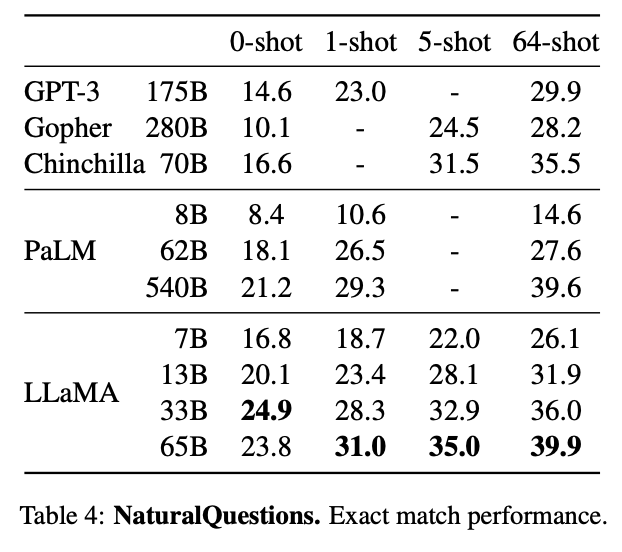
Today we release LLaMA, 4 foundation models ranging from 7B to 65B parameters. LLaMA-13B outperforms OPT and GPT-3 175B on most benchmarks. LLaMA-65B is competitive with Chinchilla 70B and PaLM 540B. The weights for all models are open and available at research.facebook.com/publications/l… 1/n


Read about Non-Parametric Model deepai.org/machine-learni… #OrdinalNumber #NonParametricModel


You can now watch the recorded material from #NeurIPS2022 online without registration at: slideslive.com/neurips-2022

1/ The 2022 climate data is out. And it’s terrifying. Overall, 2022 was the fifth warmest year on record. Below is a short🧵on 2022’s record-breaking droughts, floods, ‘rain bombs,’ wildfires & more Cc: @dwallacewells @JesseJenkins @ylecun @leahstokes @Noahpinion @MichaelEMann


If you are looking for a winter break project, here is the full collection of ML/coding puzzles. (I think this is more useful than prompting, but who knows?) * github.com/srush/tensor-p… * github.com/srush/gpu-puzz… * github.com/srush/autodiff… * github.com/srush/raspy





*Thinking Like Transformers* Awesome blog post by @srush_nlp based on the paper by the same name. If you write a programming language inspired by the way Transformers work, how easy would it be to program in it? 👀 Blog: srush.github.io/raspy/ Paper: arxiv.org/pdf/2106.06981…



📍🧵🚨 QA on plots & charts is a complex task requiring sophisticated reasoning - our visual language models struggle with this. LLMs are super strong reasoners - but they only work for text. What do we do? We translate plots & charts to text so LLM can understand!


🚨Help NLP models process negation🚨 Introducing ℂ𝕆ℕ𝔻𝔸ℚ𝔸, a *contrastive* reading comprehension dataset that requires reasoning about negation w/ @nlpmattg & @anmarasovic @ai2_allennlp, at #EMNLP2022 📝Paper arxiv.org/abs/2211.00295 🚀Data github.com/AbhilashaRavic… [1/8]
![lasha_nlp's tweet image. 🚨Help NLP models process negation🚨
Introducing ℂ𝕆ℕ𝔻𝔸ℚ𝔸, a *contrastive* reading comprehension dataset that requires reasoning about negation
w/ @nlpmattg & @anmarasovic @ai2_allennlp, at #EMNLP2022
📝Paper arxiv.org/abs/2211.00295
🚀Data github.com/AbhilashaRavic… [1/8]](https://pbs.twimg.com/media/FhDJ74lVQAABUjB.jpg)

It's here! Upload *any paper* to Explainpaper and start instantly getting explanations! Ask follow up questions if you need a more in-depth answer. Go to explainpaper.com and go read all the papers you've been saving! 📝📝📝

We (joint work with @ramin_m_h) have released PyHopper, a hyperparameter tuning platform for streamlining machine learning research. Pyhopper's goal is to enable people of any skill level to set up advanced multi-GPU hyperparameter tuning processes in less than a minute.


Ever wanted to know more about generalisation in NLP but overwhelmed with the number of papers on ArXiv? Fear not! We read 400+ papers, 600+ experiments, and designed a taxonomy 📝 to categorise the research for you! (1/n) 🧵 arxiv.org/abs/2210.03050



































































































United States Trends
- 1. Grammy 307K posts
- 2. Dizzy 9,515 posts
- 3. Clipse 18.4K posts
- 4. Kendrick 58.9K posts
- 5. addison rae 22.3K posts
- 6. olivia dean 14.3K posts
- 7. #GOPHealthCareShutdown 4,596 posts
- 8. AOTY 20.2K posts
- 9. Leon Thomas 18.2K posts
- 10. Katseye 112K posts
- 11. ravyn lenae 3,976 posts
- 12. gaga 97.6K posts
- 13. Alfredo 2 N/A
- 14. #FanCashDropPromotion 3,824 posts
- 15. Kehlani 33.1K posts
- 16. lorde 12.1K posts
- 17. Orban 30.9K posts
- 18. #FursuitFriday 11.8K posts
- 19. The Weeknd 11.9K posts
- 20. Alex Warren 6,983 posts



Something went wrong.
Something went wrong.