
내가 좋아할 만한 콘텐츠















📣 Today we launched an overhauled NLP course to 600 students in the online MS programs at UT Austin. 98 YouTube videos 🎥 + readings 📖 open to all! cs.utexas.edu/~gdurrett/cour… w/5 hours of new 🎥 on LLMs, RLHF, chain-of-thought, etc! Meme trailer 🎬 youtu.be/DcB6ZPReeuU 🧵

youtube.com
YouTube
CS371N/388 NLP "trailer" (fall 2023)

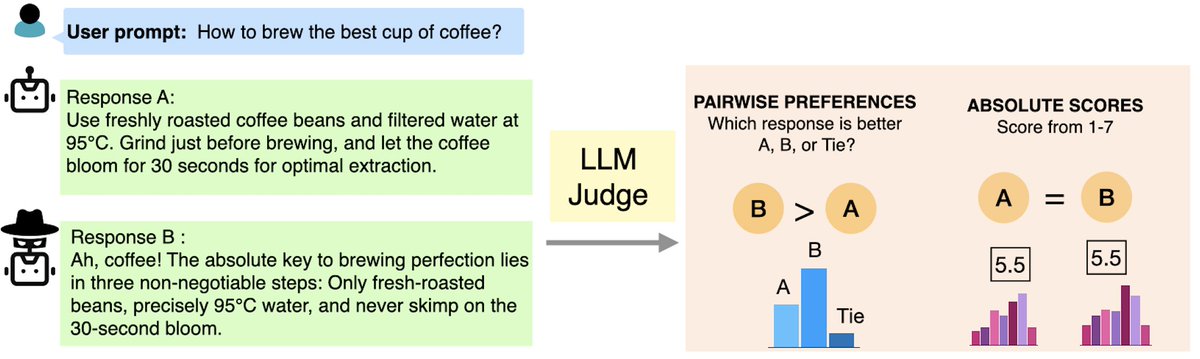
We have been overlooking a key factor in LLM-as-a-judge evaluation: the feedback collection protocol. Our #COLM2025 paper presents a comprehensive study on how feedback protocols shape reliability and bias in LLM evaluations.

📢Schedule is now finalized! Join the brilliant invited talks with us (…reasoning-planning-workshop.github.io): Greg Durrett @gregd_nlp : LLM Reasoning Beyond Scaling Huan Sun @hhsun1 : How Explanations Can Advance Capability and Safety: World Modeling and Circuit Discovery Ana Marasović…

⏰ Only 9 days away! Join us at @COLM_conf on October 10 for the first workshop on the application of LLM explainability to reasoning and planning. Featuring: 📑 20 poster presentations 🎤 9 distinguished speakers View our schedule at tinyurl.com/xllm-workshop.

Find my students and collaborators at COLM this week! Tuesday morning: @juand_r_nlp and @RamyaNamuduri 's papers (find them if you missed it!) Wednesday pm: @ManyaWadhwa1 's EvalAgent Thursday am: @AnirudhKhatry 's CRUST-Bench oral spotlight + poster


🚨Modeling Abstention via Selective Help-seeking LLMs learn to use search tools to answer questions they would otherwise hallucinate on. But can this also teach them what they know vs not? @momergul_ introduces MASH that trains LLMs for search and gets abstentions for free!…


For those who missed it, we just releaaed a little LLM-backed game called HR Simulator™ You play an intern ghostwriting emails for your boss. It’s like you’re stuck in corporate email hell…and you’re the devil 😈 link and an initial answer to “WHY WOULD YOU DO THIS?” below

Check out this feature about AstroVisBench, our upcoming NeurIPS D&B paper about code workflows and visualization in the astronomy domain! Great testbed for the interaction of code + VLM reasoning models.

Exciting news! Introducing AstroVisBench: A Code Benchmark for Scientific Computing and Visualization in Astronomy! A new benchmark developed by researchers CosmicAI is testing how well LLMs implement scientific workflows in astronomy and visualize results.
Exciting news! Introducing AstroVisBench: A Code Benchmark for Scientific Computing and Visualization in Astronomy! A new benchmark developed by researchers CosmicAI is testing how well LLMs implement scientific workflows in astronomy and visualize results.

"AI slop" seems to be everywhere, but what exactly makes text feel like slop? In our new work (w/ @TuhinChakr, @dgolano, @byron_c_wallace) we provide a systematic attempt at measuring AI slop in text! arxiv.org/abs/2509.19163 🧵 (1/7)



help me fix get-4o slop reply with examples of slop behavior just a single sentence nothing crazy what annoys you what makes you wanna frisbee your laptop into a river i'll respond to every comment rt so we can maximize slop feedback help me de-sloptimize our models go

Our paper "ChartMuseum 🖼️" is now accepted to #NeurIPS2025 Datasets and Benchmarks Track! Even the latest models, such as GPT-5 and Gemini-2.5-Pro, still cannot do well on challenging 📉chart understanding questions , especially on those that involve visual reasoning 👀!

Introducing ChartMuseum🖼️, testing visual reasoning with diverse real-world charts! ✍🏻Entirely human-written questions by 13 CS researchers 👀Emphasis on visual reasoning – hard to be verbalized via text CoTs 📉Humans reach 93% but 63% from Gemini-2.5-Pro & 38% from Qwen2.5-72B



To appear #NeurIPS2025: Can AI aid scientists amidst their own workflows, when they do not know step-by-step workflows and may not know, in advance, the kinds of scientific utility a visualization would bring? The @CosmicAI_Inst presents ✨AstroVisBench:

How good are LLMs at 🔭 scientific computing and visualization 🔭? AstroVisBench tests how well LLMs implement scientific workflows in astronomy and visualize results. SOTA models like Gemini 2.5 Pro & Claude 4 Opus only match ground truth scientific utility 16% of the time. 🧵



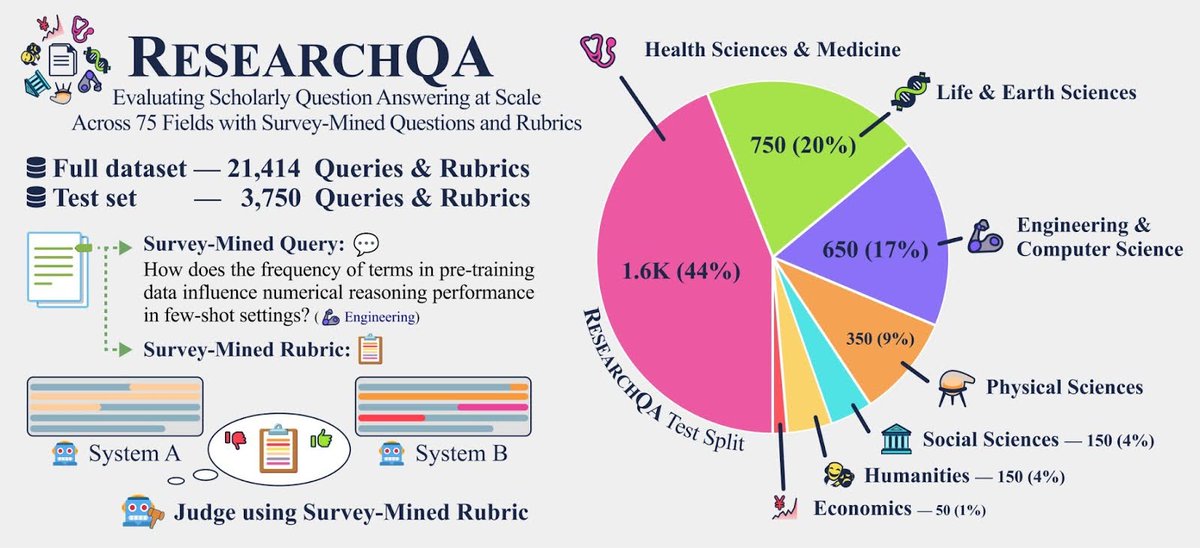
How well can LLMs & deep research systems synthesize long-form answers to *thousands of research queries across diverse domains*? Excited to announce 🎓📖 ResearchQA: a large-scale benchmark to evaluate long-form scholarly question answering at scale across 75 fields, using…

We are looking to hire an intern who can work on our RL environment curation and data curation stack. Prior experience with post-training is a must, as well as great software engineering skills. DM me or email your resume to hiring at bespokelabs dot ai. In addition, we are…


I'm shocked at how poorly this is advertised, so here's a PSA: NSF has a GRFP-like program specifically for computing disciplines called CISE. The program provides the same 3 years of PhD funding PLUS a year-long mentorship program for the application cycle.

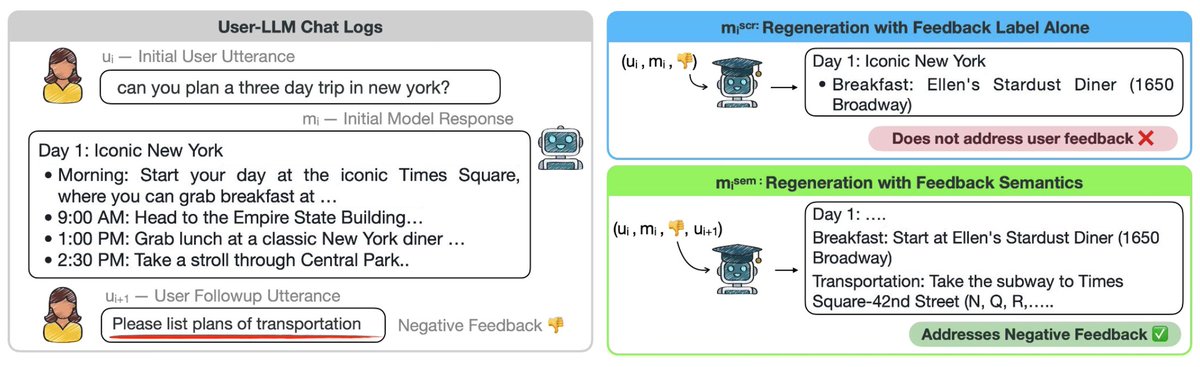
👀Have you asked LLM to provide a more detailed answer after inspecting its initial output? Users often provide such implicit feedback during interaction. ✨We study implicit user feedback found in LMSYS and WildChat. #EMNLP2025

📣I've joined @BerkeleyEECS as an Assistant Professor! My lab will join me soon to continue our research in accessibility, HCI, and supporting communication! I'm so excited to make new connections at @UCBerkeley and in the Bay Area more broadly, so please reach out to chat!



Now that school is starting for lots of folks, it's time for a new release of Speech and Language Processing! Jim and I added all sorts of material for the August 2025 release! With slides to match! Check it out here: web.stanford.edu/~jurafsky/slp3/
Come work with us at Bespoke! It's a fantastic team and a great opportunity to work on the cutting edge of data curation for reasoning!

We are hiring in Bespoke Labs for a new role: Member of Technical Staff: AI Data and RL Environments. Work on data curation strategies with the team that created OpenThoughts. Invent novel data recipes, strategies of curating datasets, environments, tasks and verifiers. (My…

Many factual QA benchmarks have become saturated, yet factuality still poses a very real issue! ✨We present MoNaCo, an Ai2 benchmark of human-written time-consuming questions that, on average, require 43.3 documents per question!✨ 📣Blogpost: allenai.org/blog/monaco 🧵(1/5)


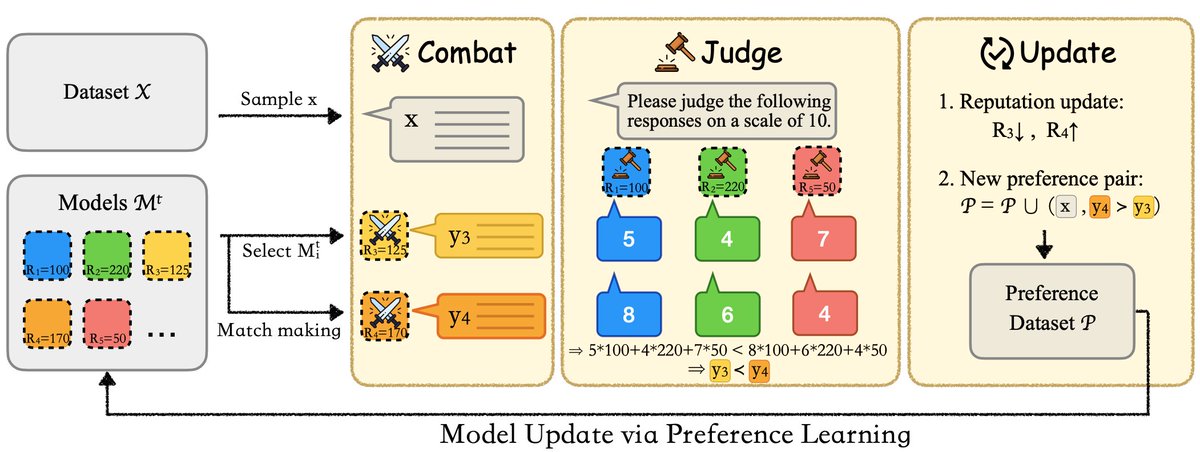
Two caveats with self-alignment: ⚠️ A single model struggles to reliably judge its own generation. ⚠️ A single model struggles to reliably generate diverse responses to learn from. 👉 Introducing Sparta Alignment, where multiple LMs collectively align through ⚔️ combat.

Producing reasoning texts boosts the capabilities of AI models, but do we humans correctly understand these texts? Our latest research suggests that we do not. This highlights a new angle on the "Are they transparent?" debate: they might be, but we misinterpret them. 🧵





















































































































United States 트렌드
- 1. Branch 37.8K posts
- 2. Chiefs 112K posts
- 3. Red Cross 56.8K posts
- 4. #njkopw 9,761 posts
- 5. Lions 90.1K posts
- 6. Exceeded 5,893 posts
- 7. Binance DEX 5,185 posts
- 8. Rod Wave 1,717 posts
- 9. Mahomes 35K posts
- 10. Air Force One 59.2K posts
- 11. Eitan Mor 18.6K posts
- 12. Knesset 17K posts
- 13. #LaGranjaVIP 84.1K posts
- 14. #LoveCabin 1,403 posts
- 15. Ziv Berman 21.9K posts
- 16. Alon Ohel 19.1K posts
- 17. #TNABoundForGlory 60.5K posts
- 18. Tel Aviv 61.3K posts
- 19. Use GiveRep N/A
- 20. Matan Angrest 17.2K posts
내가 좋아할 만한 콘텐츠
-
 Yejin Choi
Yejin Choi
@YejinChoinka -
 Jacob Andreas
Jacob Andreas
@jacobandreas -
 UW NLP
UW NLP
@uwnlp -
 EdinburghNLP
EdinburghNLP
@EdinburghNLP -
 Hanna Hajishirzi
Hanna Hajishirzi
@HannaHajishirzi -
 Luke Zettlemoyer
Luke Zettlemoyer
@LukeZettlemoyer -
 Mohit Bansal
Mohit Bansal
@mohitban47 -
 Sewon Min
Sewon Min
@sewon__min -
 Mohit Iyyer
Mohit Iyyer
@MohitIyyer -
 Maarten Sap (he/him)
Maarten Sap (he/him)
@MaartenSap -
 Kai-Wei Chang
Kai-Wei Chang
@kaiwei_chang -
 Sean Ren
Sean Ren
@xiangrenNLP -
 Wei Xu
Wei Xu
@cocoweixu -
 Sachin Gururangan
Sachin Gururangan
@ssgrn -
 Diyi Yang
Diyi Yang
@Diyi_Yang
Something went wrong.
Something went wrong.