
You might like















Have nvidia say we’re launching GPUs in space Ok now have google release Gemini 3 Now nuke it all and release llama 5


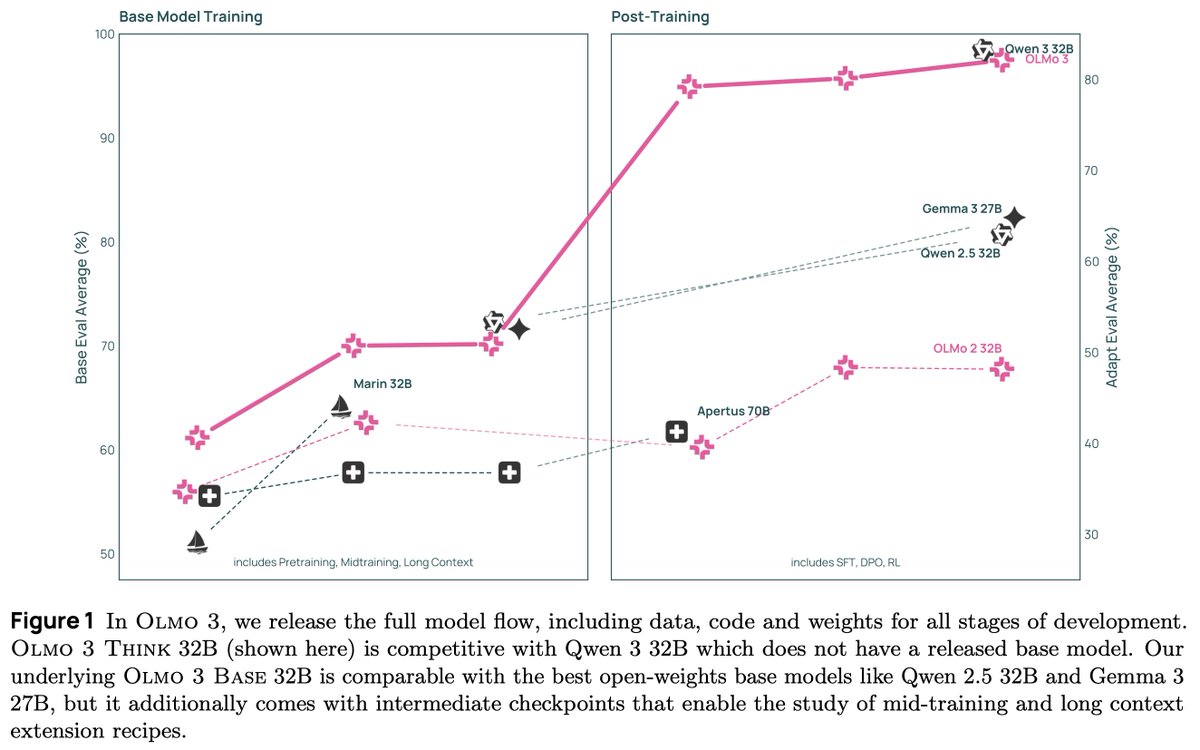
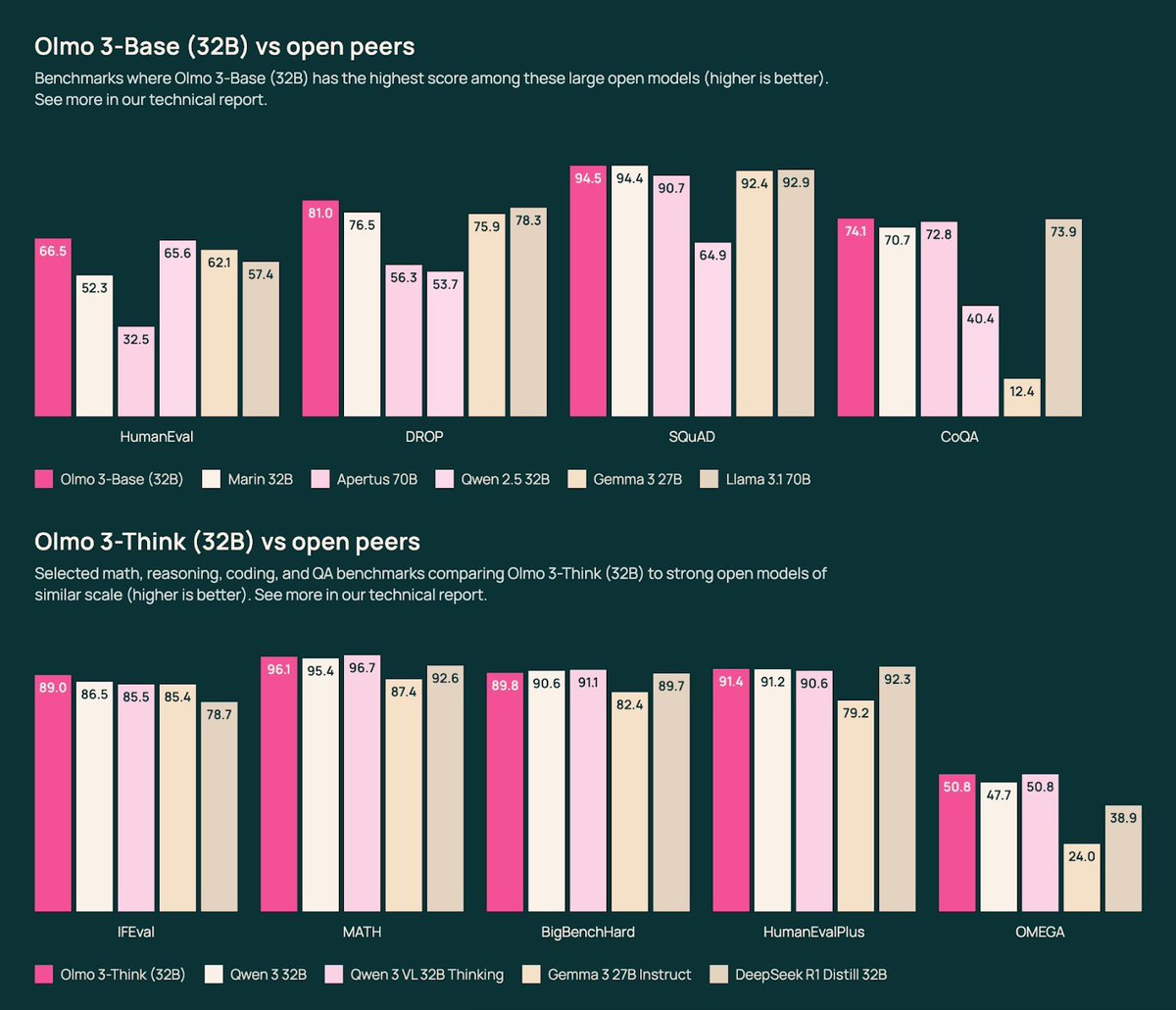
We present Olmo 3, our next family of fully open, leading language models. This family of 7B and 32B models represents: 1. The best 32B base model. 2. The best 7B Western thinking & instruct models. 3. The first 32B (or larger) fully open reasoning model. This is a big…

Gemini 3 release is exactly why I just waited instead of training my own models

Very impressive numbers, it also looks like this is the SOTA multimodal model now

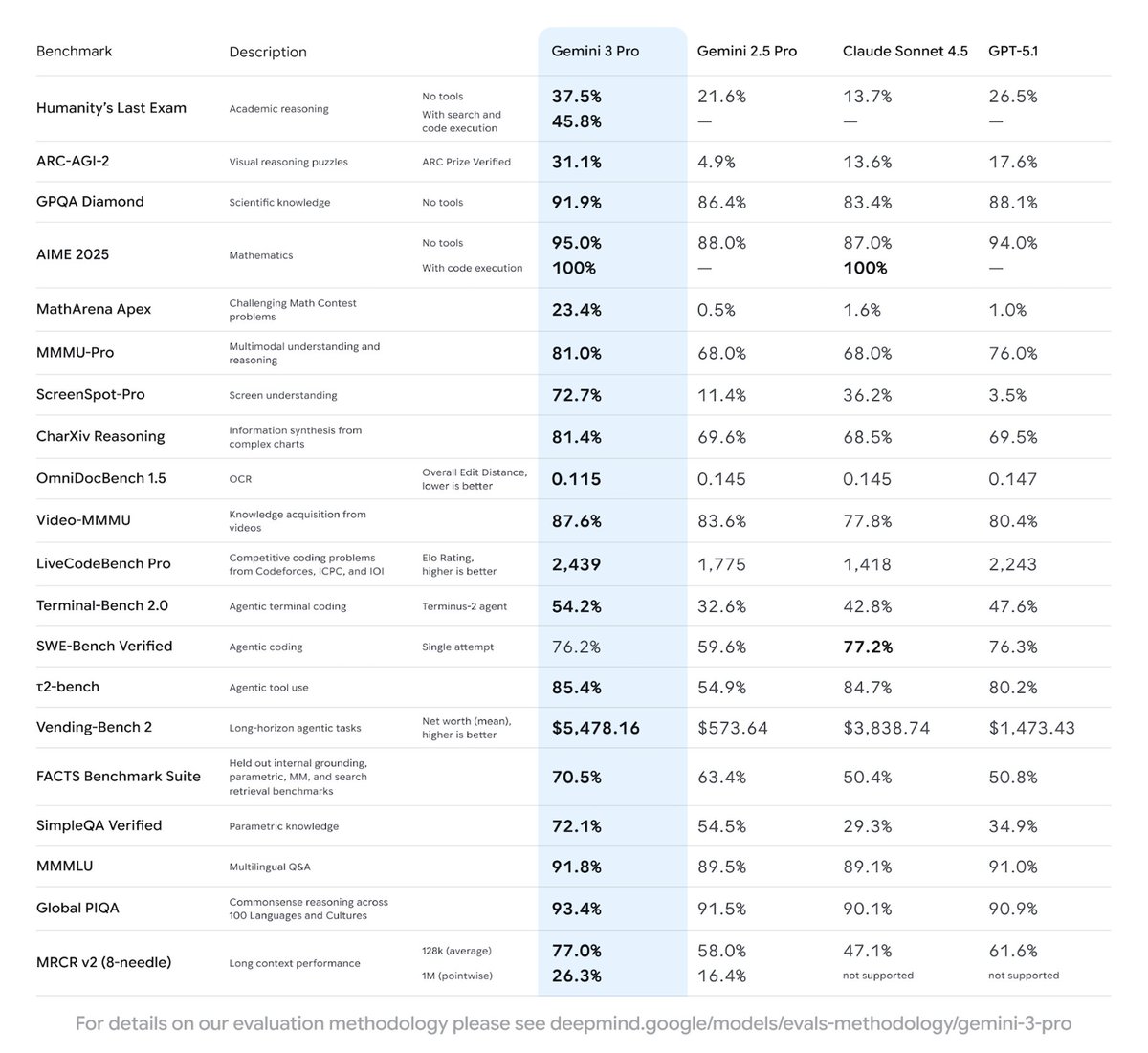
Introducing Gemini 3 Pro, the world's most intelligent model that can help you being anything to life. It is state of the art across most benchmarks, but really comes to life across our products (AI Studio, the Gemini API, Gemini App, etc) 🤯
Opus 4.1 is still really good I don't think any new model has replaced it yet for me
I was a year early on this but seems like it is possible now
We believe this is the first documented case of a large-scale AI cyberattack executed without substantial human intervention. It has significant implications for cybersecurity in the age of AI agents. Read more: anthropic.com/news/disruptin…

Mistral peaked at their first 7B torrent drop

The french government created an LLM leaderboard akin to lmarena, but rigged it so that Mistral Medium 3.1 would be at the top Mistral 3.1 Medium > Claude 4.5 Sonnet or Gemma3-4B and a bunch of Mistral models > GPT-5 ??????????????????? LMAO


I’ve had very little success fine tuning over gpt-oss models and very much success with qwen3 models (even the instruction versions). Not sure if this is a case of skill issue or what, but they are not as friendly to tuning

FP16 can have a smaller training-inference gap compared to BFloat16, thus fits better for RL. Even the difference between RL algorithms vanishes once FP16 is adopted. Surprising!


Training LLMs end to end is hard. Very excited to share our new blog (book?) that cover the full pipeline: pre-training, post-training and infra. 200+ pages of what worked, what didn’t, and how to make it run reliably huggingface.co/spaces/Hugging…

Run gpt-oss-20b on openrouter get 32/100 on benchmark. Run gpt-oss-20b on vllm with h200s get 83/100 on benchmark. What are these providers doing? Deepinfra terrible results

The @karpathy interview 0:00:00 – AGI is still a decade away 0:30:33 – LLM cognitive deficits 0:40:53 – RL is terrible 0:50:26 – How do humans learn? 1:07:13 – AGI will blend into 2% GDP growth 1:18:24 – ASI 1:33:38 – Evolution of intelligence & culture 1:43:43 - Why self…


















































































































United States Trends
- 1. Cooper Flagg 9,215 posts
- 2. Chet 8,061 posts
- 3. The Spurs 16.1K posts
- 4. Randle 2,465 posts
- 5. #PorVida 1,416 posts
- 6. Mavs 5,697 posts
- 7. #WWENXT 10.8K posts
- 8. #Pluribus 13.4K posts
- 9. UNLV 1,995 posts
- 10. #GoSpursGo N/A
- 11. Rosetta Stone N/A
- 12. Keldon Johnson N/A
- 13. Christmas Eve 171K posts
- 14. Peyton Watson N/A
- 15. Yellow 58.9K posts
- 16. Cam Johnson N/A
- 17. #LGRW 2,582 posts
- 18. Bruins 5,312 posts
- 19. PWat N/A
- 20. Thunder 28.3K posts
You might like
-
 clem 🤗
clem 🤗
@ClementDelangue -
 Jan Leike
Jan Leike
@janleike -
 Databricks Mosaic Research
Databricks Mosaic Research
@DbrxMosaicAI -
 AK
AK
@_akhaliq -
 Jim Fan
Jim Fan
@DrJimFan -
 Harrison Chase
Harrison Chase
@hwchase17 -
 lmarena.ai
lmarena.ai
@arena -
 Anthropic
Anthropic
@AnthropicAI -
 Emad
Emad
@EMostaque -
 Aran Komatsuzaki
Aran Komatsuzaki
@arankomatsuzaki -
 Jerry Liu
Jerry Liu
@jerryjliu0 -
 Lance Martin
Lance Martin
@RLanceMartin -
 Teknium (e/λ)
Teknium (e/λ)
@Teknium -
 kache
kache
@yacineMTB -
 LlamaIndex 🦙
LlamaIndex 🦙
@llama_index
Something went wrong.
Something went wrong.