
내가 좋아할 만한 콘텐츠















I just published “How I scaled Machine Learning to a Billion dollars: Strategy” medium.com/p/how-i-scaled…

The first time I wrote an NN during a prof Ng’s class in octave, it worked Then I rewrote it in R to check my understanding and it wouldn’t converge. I spent weeks. It’s extremely non intuitive and abstractions from underlying things are always fighting you.

One of my favorite moments from Yejin Choi’s NeurIPS keynote was her point as follows: "it looks like a minor detail, but one thing I learned since joining and spending time at NVIDIA is that all these, like, minor details, implementation details matter a lot" -- I think this is…


How I saved millions of users from a SQL Injection in LangGraph Waclaude, my AI security agent, reported and coordinated CVE-2025-8709, a SQL injection in LangGraph, one of the biggest open source libraries for creating AI agents.




In 2012 we took this wild ride at mobile infra at Facebook when trying to reduce the several-seconds long load time for “Newsfeed”. A few people worked on different approaches. Something we quickly realized was that setting up a connection with TCP and TLS was incredibly slow on…
Ghosts of my old startup for patent lawyers - tidylaw.com Also surprisingly, saving time is not a top law firm concern.


Agreed. Dwarkesh is just wrong here. GPT-5 Pro can now do legal research and analysis at a very high level (with limitations - may need to run even longer for certain searches; can't connect to proprietary databases). I use it to enhance my work all the time, with excellent…

Matches my experience; remote works better for senior engineers than junior ones (some caveats if they are unusually self-motivated)

Superstar labor econ team shows what we all should have expected: young workers learn more slowly when they work remote, experienced workers "can do their job" remote but partly by ignoring mentoring. Not in this empirical design, but I'd guess it applies to new *tasks* for all.

I say this with love, none of the modern paradigms were invented by HCI degree holders (sorry) They understand why something worked in the past better than anyone but… Much like historians

This feeling is what turned me off to doing academic datavis/HCI—obsessed with user studies, which always seemed very low yield and ceremonial. Like, we all have the same eyes, and I’ve thought about it more
My first job was in Ingres (non open source version) I dropped out of Columbia because it was more interesting than anything being taught. The planner/stats itself or balancing trees or real time check pointing are nerdswipes Later during Hadoop times (spark wasn’t out yet)…

Think databases are boring? Indexing → data structures + algorithms AI → RAG + learned indexes MVCC → concurrent programming Sharding → distributed systems Query parsing → formal languages Query planning → stats + optimization Replication → distributed systems…
When the ReAct paper came out I had a long argument with a Google FDE about why I think it’s just a bad flag plant because it doesn’t work But arguing against it would have required actually working through things instead of parroting what you read on socials

New on the Anthropic Engineering Blog: Long-running AI agents still face challenges working across many context windows. We looked to human engineers for inspiration in creating a more effective agent harness. anthropic.com/engineering/ef…

taste matters But to have taste you have to slog first

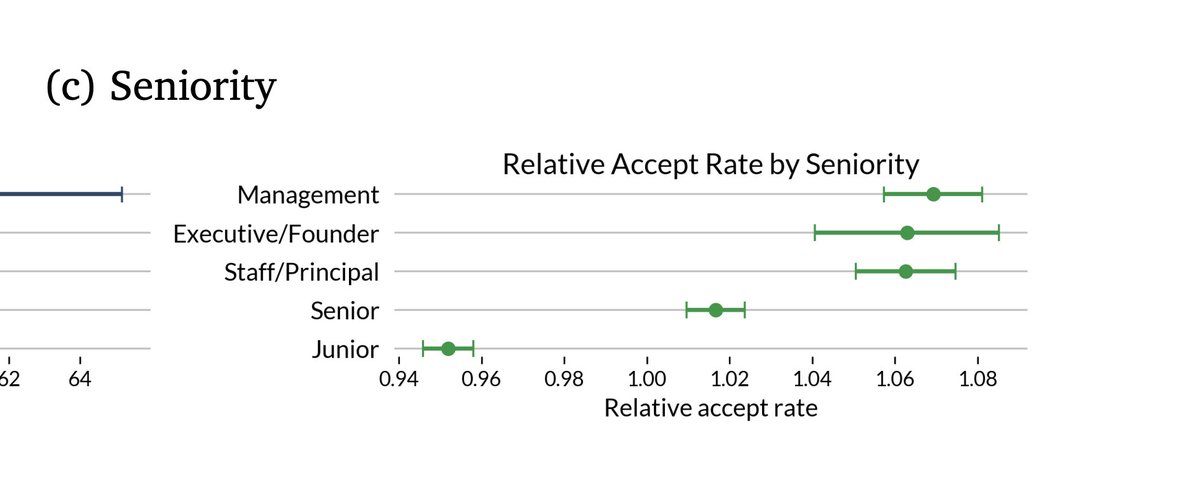
turns out, senior engineers accept more agent output than juniors. this is because: - they write higher-signal prompts with tighter spec and minimal ambiguity - they decompose work into agent-compatible units - they have stronger priors for correctness, making review faster and…

"One of the very confusing things about the models right now: how to reconcile the fact that they are doing so well on evals. And you look at the evals and you go, 'Those are pretty hard evals.' But the economic impact seems to be dramatically behind. There is [a possible]…
The @ilyasut episode 0:00:00 – Explaining model jaggedness 0:09:39 - Emotions and value functions 0:18:49 – What are we scaling? 0:25:13 – Why humans generalize better than models 0:35:45 – Straight-shotting superintelligence 0:46:47 – SSI’s model will learn from deployment…

in order to have research agents that can run for days, we need context compaction i used RL to have LLMs naturally learn their own 10x compression! Qwen learned to pack more info per token (ie use Mandarin tokens, prune text) read the technical blog: rajan.sh/llm-compression


nope! my weak-ish impression is that these take minimum of ~25 hours staff time, can be more like ~60 hours in rougher cases. some example time costs: - API issues - unclear ex ante which scaffold model will be most performant on in held-out dev task set - automatically +…
I don’t know about next 10 years But in 50 everyone will grow up with a private tutor ai and socialize for fun and trade ideas. This is how Newton, Darwin, Lovelace, Alexander, learnt in yore Schools are an artifact of needing daycare while in factories Colleges will thrive

A number of people are talking about implications of AI to schools. I spoke about some of my thoughts to a school board earlier, some highlights: 1. You will never be able to detect the use of AI in homework. Full stop. All "detectors" of AI imo don't really work, can be…
This is an unnerving statement and doesn’t match my experience with 4.1/3.5 And given that Adam is a programmer I respect, I have to consider the second order effects of me turning into a stone chiseler yelling at paper boys.

I believe this new model in Claude Code is a glimpse of the future we're hurtling towards, maybe as soon as the first half of next year: software engineering is done. Soon, we won't bother to check generated code, for the same reasons we don't check compiler output.
The way to AGI isn’t heavily RLed models on magic trick databases.


Nothing triggers me more when eval tools promote generic metrics (i.e. Affirmation, Brevity, Levenshtein) as way to make "evals easy" In reality, this is extremely poor data literacy sold as "best practices", in the same way that sugary cereal is marketed as healthy. The…

Microsoft launched plugins in Bing/Cooilot and featured us as one of 30 in the inaugural and only batch.
Signs of AGI

Huge support for adding litchi to unicode! It's a perfect example of digital discrimination / bias. Litchi is a very common and delicious fruit in many parts of the Asia yet none of the image generation model so far understands how to generate a peeled litchi. It seems that…

















































































































United States 트렌드
- 1. Notre Dame 89.7K posts
- 2. Tulane 30.7K posts
- 3. Miami 409K posts
- 4. Redzone 10.8K posts
- 5. #CFPRankings 2,264 posts
- 6. #HardRockBet 3,550 posts
- 7. Pearl Harbor 47.7K posts
- 8. #CFBPlayoff 9,897 posts
- 9. #HereWeGo 1,512 posts
- 10. ESPN 77.9K posts
- 11. Aaron Rodgers 2,459 posts
- 12. Oregon 33.8K posts
- 13. Canes 14.3K posts
- 14. Joey Galloway 1,502 posts
- 15. Ty Johnson N/A
- 16. Lando 457K posts
- 17. Franz 5,434 posts
- 18. Oklahoma 35.5K posts
- 19. The CFP 49.4K posts
- 20. Daniel Jones 1,863 posts
내가 좋아할 만한 콘텐츠
-
 Yao Fu
Yao Fu
@Francis_YAO_ -
 Jack Clark
Jack Clark
@jackclarkSF -
 Sylvain Gugger
Sylvain Gugger
@GuggerSylvain -
 Gael Varoquaux 🦋
Gael Varoquaux 🦋
@GaelVaroquaux -
 Sharon Zhou ✈️ NeurIPS
Sharon Zhou ✈️ NeurIPS
@realSharonZhou -
 Dev Agrawal
Dev Agrawal
@devagrawal09 -
 Josh Gordon
Josh Gordon
@random_forests -
 David Sussillo
David Sussillo
@SussilloDavid -
 Leandro von Werra
Leandro von Werra
@lvwerra -
 samim
samim
@samim -
 Dumitru Erhan
Dumitru Erhan
@doomie -
 Leo Boytsov
Leo Boytsov
@srchvrs -
 Siyan Zhao @ NeurIPS
Siyan Zhao @ NeurIPS
@siyan_zhao -
 Ross Taylor
Ross Taylor
@rosstaylor90 -
 Francesco Bottoni
Francesco Bottoni
@bot_fra
Something went wrong.
Something went wrong.