
Saurabh Bhatnagar
@analyticsaurabh
http://tora.bohita.com First Fashion Recommendation ML @ Rent The Runway 🦄, Founded ML at Barnes & Nobles. Past, @Virevol, Unilever, HP, ...
قد يعجبك















I just published “How I scaled Machine Learning to a Billion dollars: Strategy” medium.com/p/how-i-scaled…
Bengio once said that there are only 10 people in the world who understand deep learning and 8 are in my lab. His disdain for ‘others’ has always been palpable. Brilliant scientist though

Yoshua Bengio says AI does not create enough new jobs to balance the ones it replaces A handful of engineers earn huge salaries, while a vast number of workers face displacement as models master cognitive tasks "if we automate most of the cognitive work, what's gonna be left?"
Honest day’s work

There is lot more to say on these beautiful visualizations. Please let me know of any errors or other cool things we should know. More at my blog: How to Get and Interpret GPU Memory Profiling shital.com/blog/gpu-memor…
I’m going to avoid reading this article for as long as I can 🙈

Bombshell: Oliver Sacks (a humane man & a fine essayist) made up many of the details in his famous case studies, deluding neuroscientists, psychologists, & general readers for decades. The man who mistook his wife for a hat? The autistic twins who generated multi-digit prime…

Now that’s a labor of love

#KostasKeynoteLessons: Curious about the "Keynote magic" behind my slides? I’m releasing the full Keynote source file for my recent Gaussian Splatting lecture, all 10 GIGAbytes of it! Grab the files in the thread and feel free to remix.
3X Faster and Lighter!

You can now train LLMs 3× faster with no accuracy loss, via our new RoPE and MLP kernels. Our Triton kernels plus smart auto packing delivers ~3× faster training & 30% less VRAM vs optimized FA3 setups. Train Qwen3-4B 3x faster on just 3.9GB VRAM. Blog: docs.unsloth.ai/new/3x-faster-…


So after all these hours talking about AI, in these last five minutes I am going to talk about: Horses. Engines, steam engines, were invented in 1700. And what followed was 200 years of steady improvement, with engines getting 20% better a decade. For the first 120 years of…
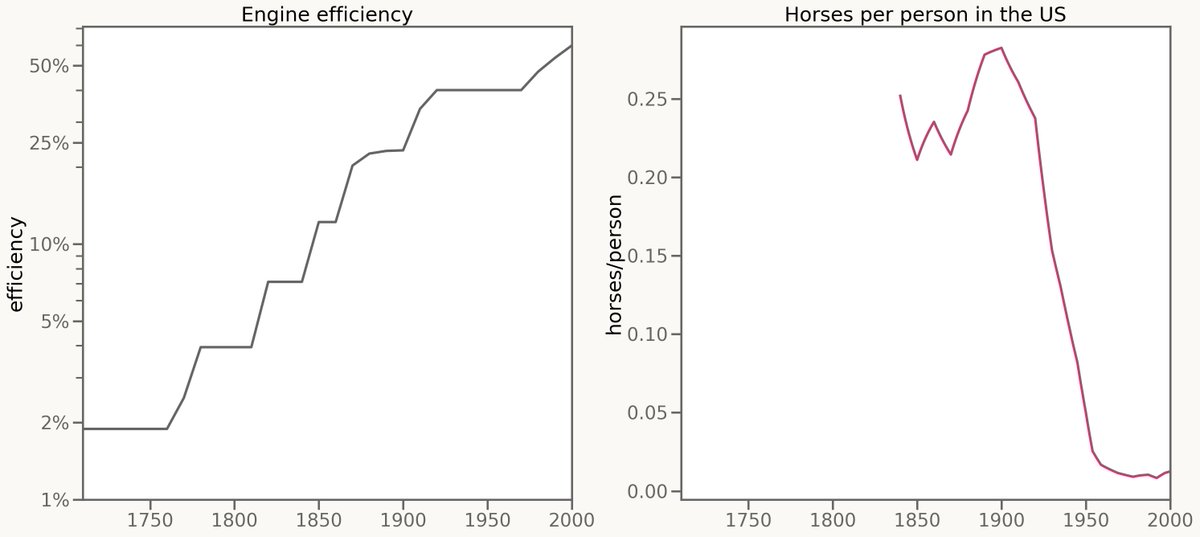
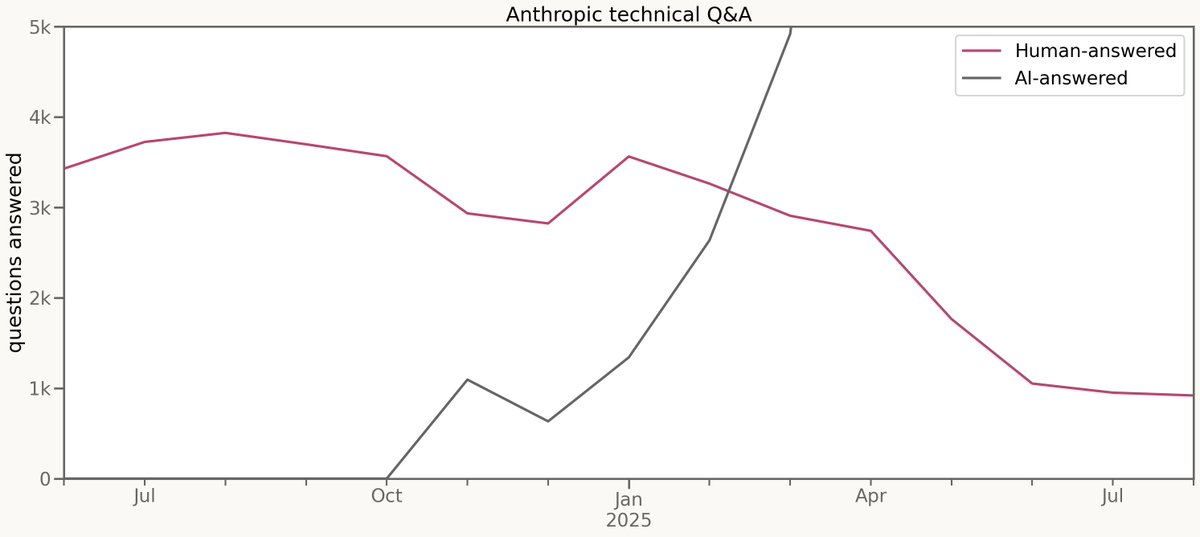
So people were asking me only 1/8th the questions they had
But from my perspective, from equivalence to me, it hasn't been steady at all. I was one of the first researchers hired at Anthropic. This pink line, back in 2024, was a large part of my job. Answer technical questions for new hires. Back then, me and other old-timers were…
The first time I wrote an NN during a prof Ng’s class in octave, it worked Then I rewrote it in R to check my understanding and it wouldn’t converge. I spent weeks. It’s extremely non intuitive and abstractions from underlying things are always fighting you.

One of my favorite moments from Yejin Choi’s NeurIPS keynote was her point as follows: "it looks like a minor detail, but one thing I learned since joining and spending time at NVIDIA is that all these, like, minor details, implementation details matter a lot" -- I think this is…


How I saved millions of users from a SQL Injection in LangGraph Waclaude, my AI security agent, reported and coordinated CVE-2025-8709, a SQL injection in LangGraph, one of the biggest open source libraries for creating AI agents.




In 2012 we took this wild ride at mobile infra at Facebook when trying to reduce the several-seconds long load time for “Newsfeed”. A few people worked on different approaches. Something we quickly realized was that setting up a connection with TCP and TLS was incredibly slow on…
Ghosts of my old startup for patent lawyers - tidylaw.com Also surprisingly, saving time is not a top law firm concern.


Agreed. Dwarkesh is just wrong here. GPT-5 Pro can now do legal research and analysis at a very high level (with limitations - may need to run even longer for certain searches; can't connect to proprietary databases). I use it to enhance my work all the time, with excellent…

Matches my experience; remote works better for senior engineers than junior ones (some caveats if they are unusually self-motivated)

Superstar labor econ team shows what we all should have expected: young workers learn more slowly when they work remote, experienced workers "can do their job" remote but partly by ignoring mentoring. Not in this empirical design, but I'd guess it applies to new *tasks* for all.

I say this with love, none of the modern paradigms were invented by HCI degree holders (sorry) They understand why something worked in the past better than anyone but… Much like historians

This feeling is what turned me off to doing academic datavis/HCI—obsessed with user studies, which always seemed very low yield and ceremonial. Like, we all have the same eyes, and I’ve thought about it more
My first job was in Ingres (non open source version) I dropped out of Columbia because it was more interesting than anything being taught. The planner/stats itself or balancing trees or real time check pointing are nerdswipes Later during Hadoop times (spark wasn’t out yet)…

Think databases are boring? Indexing → data structures + algorithms AI → RAG + learned indexes MVCC → concurrent programming Sharding → distributed systems Query parsing → formal languages Query planning → stats + optimization Replication → distributed systems…
When the ReAct paper came out I had a long argument with a Google FDE about why I think it’s just a bad flag plant because it doesn’t work But arguing against it would have required actually working through things instead of parroting what you read on socials

New on the Anthropic Engineering Blog: Long-running AI agents still face challenges working across many context windows. We looked to human engineers for inspiration in creating a more effective agent harness. anthropic.com/engineering/ef…

taste matters But to have taste you have to slog first

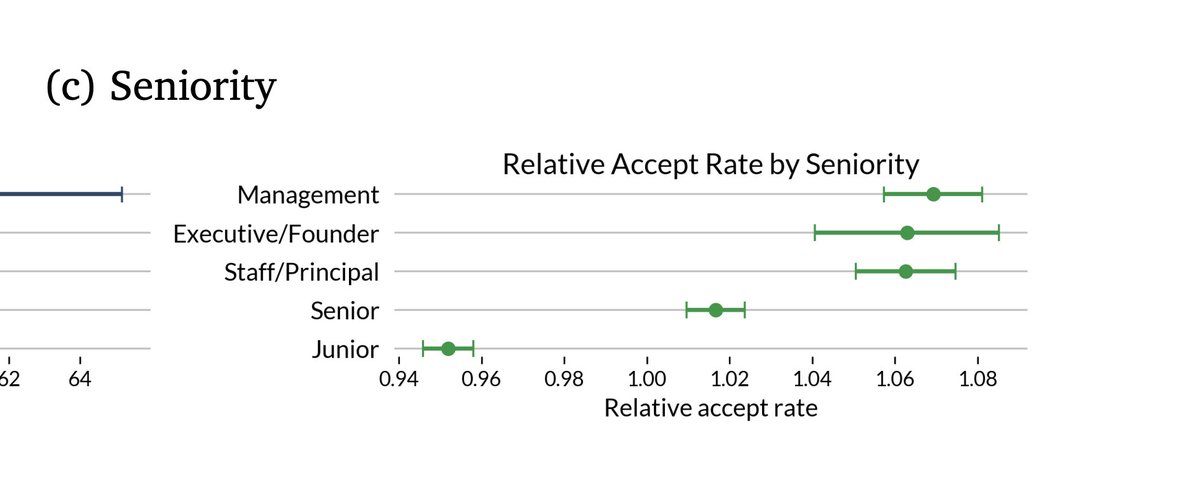
turns out, senior engineers accept more agent output than juniors. this is because: - they write higher-signal prompts with tighter spec and minimal ambiguity - they decompose work into agent-compatible units - they have stronger priors for correctness, making review faster and…
















































































































United States الاتجاهات
- 1. #Fliffmas N/A
- 2. Provo 1,422 posts
- 3. 60 Minutes 123K posts
- 4. Greenland 28.7K posts
- 5. NextNRG Inc. 1,116 posts
- 6. #IDontWantToOverreactBUT N/A
- 7. Bari Weiss 102K posts
- 8. The Odyssey 50.3K posts
- 9. Barry Manilow N/A
- 10. Happy Holidays 66.7K posts
- 11. Chris Rea 18.2K posts
- 12. #MondayMotivation 33.5K posts
- 13. Lincoln Riley N/A
- 14. Christopher Nolan 51.1K posts
- 15. Petrino 1,636 posts
- 16. Byrum Brown N/A
- 17. Kittle 1,395 posts
- 18. Christmas Eve 24.7K posts
- 19. George Conway 1,117 posts
- 20. Ghost of Tsushima N/A
قد يعجبك
-
 Yao Fu
Yao Fu
@Francis_YAO_ -
 Jack Clark
Jack Clark
@jackclarkSF -
 Sylvain Gugger
Sylvain Gugger
@GuggerSylvain -
 Gael Varoquaux 🦋
Gael Varoquaux 🦋
@GaelVaroquaux -
 Sharon Zhou ✈️ NeurIPS
Sharon Zhou ✈️ NeurIPS
@realSharonZhou -
 Dev Agrawal
Dev Agrawal
@devagrawal09 -
 Jakub Tomczak
Jakub Tomczak
@jmtomczak -
 Josh Gordon
Josh Gordon
@random_forests -
 David Sussillo
David Sussillo
@SussilloDavid -
 Leandro von Werra
Leandro von Werra
@lvwerra -
 samim
samim
@samim -
 Dumitru Erhan
Dumitru Erhan
@doomie -
 Leo Boytsov
Leo Boytsov
@srchvrs -
 Fernando Pereira
Fernando Pereira
@earnmyturns -
 Siyan Zhao
Siyan Zhao
@siyan_zhao
Something went wrong.
Something went wrong.