
你可能會喜歡













I love these results that simultaneously show the upside of great models like gpt 5 and Gemini, but also identify their flaws. There's work to be done ;) Which gpt 5 is this btw? Would be interesting to run pro


Cool work, excited to see which games end up being easier or harder and which models are good at which games. Presumably there is some game out there that Gemini or Claude just absolutely crush?

(9/9) We're releasing a ton of new and harder games on Game Arena every day. Think of 2 page -> 20+ page rulebook length! So stay tuned, and my DMs are open for those interested in partnering and early access!

Love mengus workshop!

Thank you for the visibility. If you like old Magic cards and want to see them being played in the best in paper with highly edited content make sure to check out Mengu's Workshop on Youtube!!! 😍(No link because I still didn't understand if Twitter punishes these or not).
My phone "autocorrects" this every single time, glad to see I'm not the only one :p


Impressive work!

We evaluated Gemini 2.5 Deep Think on FrontierMath. There is no API, so we ran it manually. The results: a new record! We also conducted a more holistic evaluation of its math capabilities. 🧵


New ARC-AGI SOTA: GPT-5 Pro - ARC-AGI-1: 70.2%, $4.78/task - ARC-AGI-2: 18.3%, $7.41/task @OpenAI’s GPT-5 Pro now holds the highest verified frontier LLM score on ARC-AGI’s Semi-Private benchmark



For those of you on Sora, my Cameos are open. Have at it

⬆️ LLMs’ forecasting abilities are steadily improving. GPT-4 (released March 2023) achieved a difficulty-adjusted Brier score of 0.131. Nearly two years later, GPT-4.5 (released Feb 2025) scored 0.101—a substantial improvement. A linear extrapolation of state-of-the-art LLM…


@NotionHQ has processed (well over) a trillion tokens on @OpenAI , and now we have this cool token to show for it.


GPT-5 Pro found a counterexample to the NICD-with-erasures majority optimality (Simons list, p.25). simons.berkeley.edu/sites/default/… At p=0.4, n=5, f(x) = sign(x_1-3x_2+x_3-x_4+3x_5) gives E|f(x)|=0.43024 vs best majority 0.42904.



Terence Tao + AI for solving hard math problems🤯 In this example the insight comes from Terence, and the muscle—via an hourlong conversation with GPT-5 and some python code it wrote—comes from AI. "Here, the AI tool use was a significant time saver... Indeed I would have been…
Really cool stuff and cool to see a unique approach work out so well 😁

Our first-ever technical report is here! We’re providing an unprecedented look into the architecture and methodology behind our AI system; Aristotle, and shining light on the “how” behind our IMO gold-level performance. Read the full report below⬇️
Important work!

🚨 Just published! All frontier AI models have failed “Radiology’s Last Exam” - the toughest benchmark in radiology launched today! ✅ Board-certified radiologists scored 83%, trainees 45%, but the best performing AI from frontier labs, GPT-5, managed only 30%. ❌ These results…


What a champion



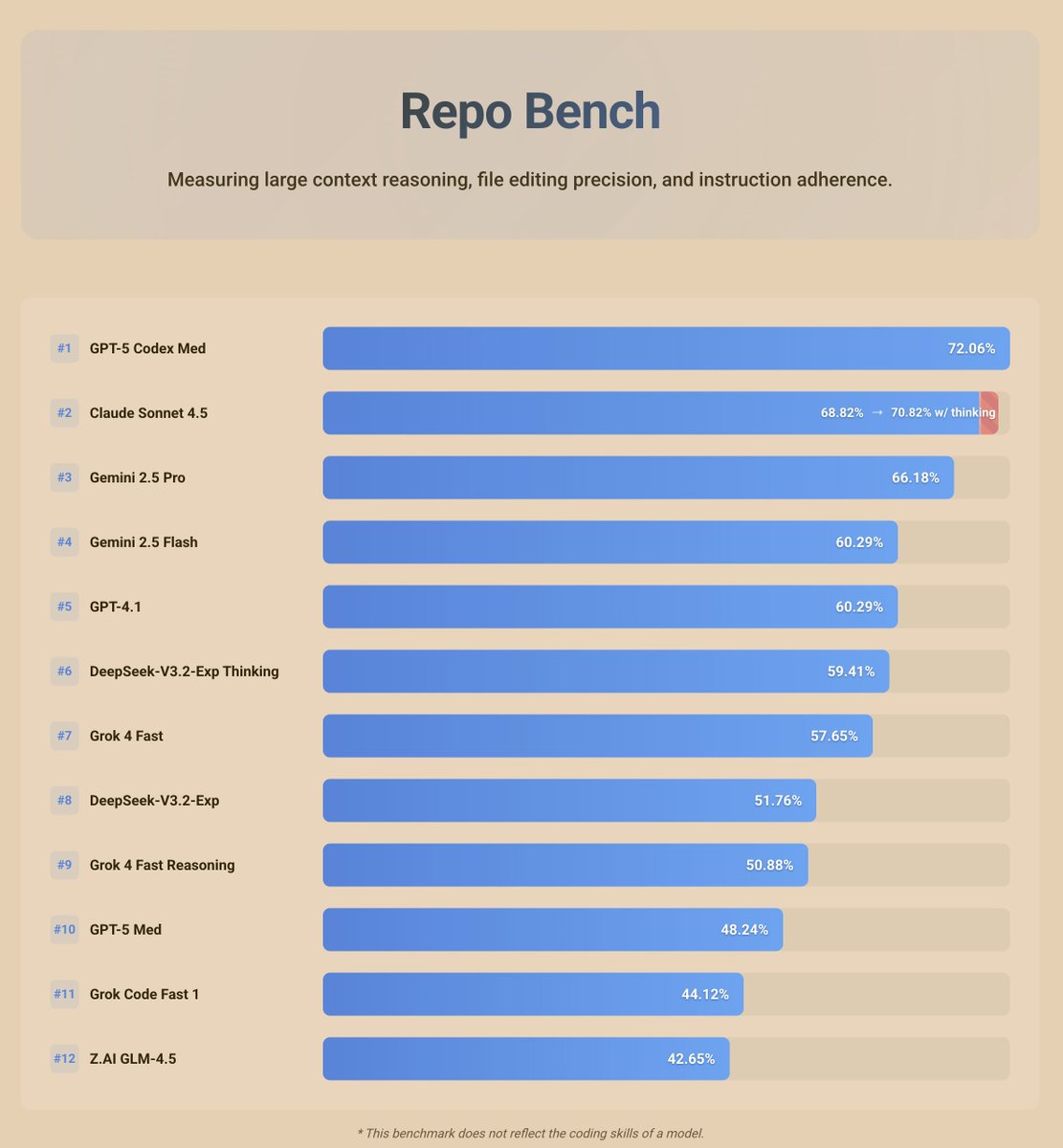
First results are out for the @RepoPrompt benchmark! Repo Bench is a test set designed to push models on instruction following, large context reasoning, and precision file editing. Gearing up to release this shortly in the next update so you can run the bench yourself



True 🤩🤩🤣😂🤣😂☺️😀😍😍

This is genuinely something I could see myself putting on my wall. Needs a bit more color though

Next up is Gemeni 2.5 Pro: Very nice organic shape- a phyllotaxis shape. Very fitting! Gemini strikes me as more organic in nature.

This is cool and the harmonic keyboard might be even cooler 😎





























































































United States 趨勢
- 1. Jets 83.1K posts
- 2. Jets 83.1K posts
- 3. Justin Fields 9,439 posts
- 4. Aaron Glenn 4,549 posts
- 5. Sean Payton 2,576 posts
- 6. London 204K posts
- 7. #HardRockBet 3,398 posts
- 8. Bo Nix 3,669 posts
- 9. Garrett Wilson 3,441 posts
- 10. HAPPY BIRTHDAY JIMIN 155K posts
- 11. #DENvsNYJ 2,217 posts
- 12. Tyrod 1,706 posts
- 13. #OurMuseJimin 200K posts
- 14. #JetUp 2,003 posts
- 15. #30YearsofLove 176K posts
- 16. Bam Knight N/A
- 17. Peart 1,906 posts
- 18. Kurt Warner N/A
- 19. Sutton 2,826 posts
- 20. Breece Hall 1,964 posts
你可能會喜歡
-
 Maria Eckstein
Maria Eckstein
@eckstein_maria -
 Marcelo Mattar
Marcelo Mattar
@marcelomattar -
 Griffiths Computational Cognitive Science Lab
Griffiths Computational Cognitive Science Lab
@cocosci_lab -
 Sebastian Musslick
Sebastian Musslick
@smusslick -
 Andra Mihali
Andra Mihali
@Lianaaan -
 Mayank Agrawal
Mayank Agrawal
@_magrawal -
 Eran Eldar
Eran Eldar
@eraneldar -
 Angela Radulescu
Angela Radulescu
@angelaradulescu -
 Ted Sumers
Ted Sumers
@tedsumers -
 Ionatan Kuperwajs
Ionatan Kuperwajs
@Ikuperwajs -
 Dan Mirea
Dan Mirea
@DanMirea4 -
 Qihong Lu | 吕其鸿
Qihong Lu | 吕其鸿
@Qihong_Lu -
 Matt Panichello
Matt Panichello
@MattPanichello
Something went wrong.
Something went wrong.