
Rylan Schaeffer
@RylanSchaeffer
CS PhD Student at Stanford Trustworthy AI Research with @sanmikoyejo. Prev interned/worked @ Meta, Google, MIT, Harvard, Uber, UCL, UC Davis
You might like















"we find that simply training on self-generations with the exact same arch can actually improve performance" Same as what we showed in our model collapse paper arxiv.org/abs/2404.01413 ! Synthetic data done correctly can be a fantastic resource!
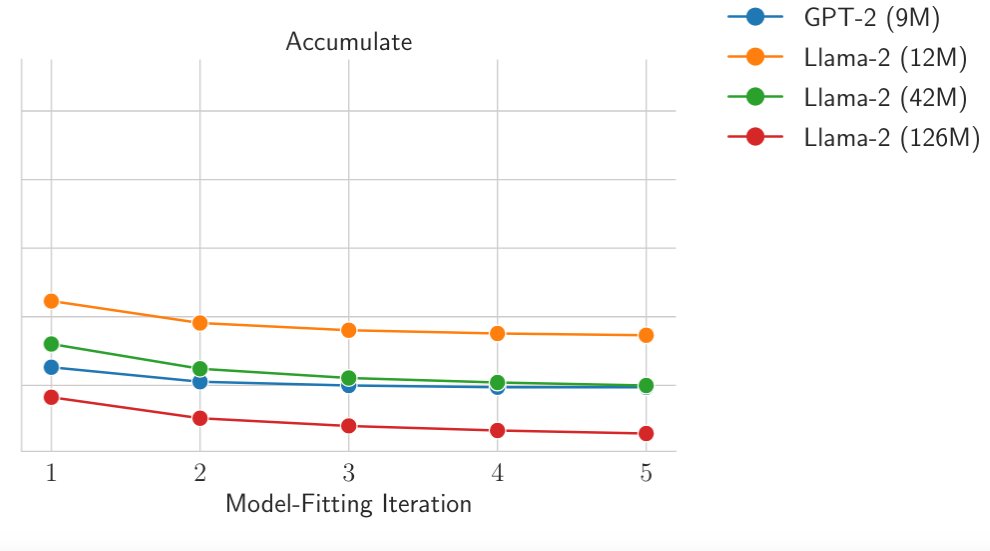

Are ♾ parameters necessary for data efficiency wins? Via distillation, we compress an 8-ensemble into a single model and retain most of the improvement. Furthermore, we find that simply training on self-generations with the exact same arch can actually improve performance


Introducing RND1, the most powerful base diffusion language model (DLM) to date. RND1 (Radical Numerics Diffusion) is an experimental DLM with 30B params (3B active) with a sparse MoE architecture. We are making it open source, releasing weights, training details, and code to…

Transfusion combines autoregressive with diffusion to train a single transformer, but what if we combine Flow with Flow? 🤔 🌊OneFlow🌊 the first non-autoregressive model to generate text and images concurrently using a single transformer—unifying Edit Flow (text) with Flow…

We’re hiring someone to run the Anthropic Fellows Program! Our research collaborations have led to some of our best safety research and hires. We’re looking for an exceptional ops generalist, TPM, or research/eng manager to help us significantly scale and improve our collabs 🧵
I've tried using GPT 5, GPT 5 Thinking and GPT 5 Pro for AI/ML research I'm underwhelmed :( I can't tell whether the problem is my expectations are higher, but it feels like a non-improvement over previous OpenAI models.

The voxel pagodas have a special place in my heart 🌸 It's been my go-to vibe eval since early Deep Think development. Glad it made it into the demo!


The hardest scaling law prediction problems are no match for @YingXiao armed only with a spreadsheet and his measuring stick

Advanced version of Gemini Deep Think (announced at #GoogleIO) using parallel inference time computation achieved gold-medal performance at IMO, solving 5/6 problems with rigorous proofs as verified by official IMO judges! Congrats to all involved! deepmind.google/discover/blog/…

Come to Convention Center West room 208-209 2nd floor to learn about optimal data selection using compression like gzip! tldr; you can learn much faster if you use gzip compression distances to select data given a task! DM if you are interested or what to use the code!

🚨 What’s the best way to select data for fine-tuning LLMs effectively? 📢Introducing ZIP-FIT—a compression-based data selection framework that outperforms leading baselines, achieving up to 85% faster convergence in cross-entropy loss, and selects data up to 65% faster. 🧵1/8


Large Language Monkeys are scaling and they are hungry! 🍌 #ICML2025

I'll be at @icmlconf #ICML2025 next week to present three papers - reach out if you want to chat about generative AI, scaling laws, synthetic data or any other AI topic! #1 How Do Large Language Monkeys Get Their Power (Laws)? x.com/RylanSchaeffer…

If you want to learn about the power (laws) of large language monkeys (and get a free banana 🍌), come to our poster at #ICML2025 !!

One of two claims is true: 1) We fully automated AI/ML research, published one paper and then did nothing else with the technology, or 2) People lie on Twitter Come to our poster E2809 at #ICML2025 now to find out which!!!

We refused to cite the paper due to severe misconduct of the authors of that paper: plagiarism of our own prior work, predominantly AI-generated content (ya, the authors plugged our paper into an LLM and generated another paper), IRB violations, etc. Revealed during a long…
I'm excited to announce that @pfau is wrong - people do still care about non language modeling ML research! #ICML2025

Post-AGI employment opportunity: AI Chain of Thought Inspector?

#ICML2025 hot take: A famous researcher (redacted) said they feel like AI safety / existential risk from AI is the most important challenge of our time, and despite many researchers being well intentioned, this person feels like the field has produced no deliverables, has no idea…
An #ICML2025 story from yesterday: @BrandoHablando and I made a new friend who told us that she saw me give a talk at NeurIPS 2023 and then messaged Brando to chat, without realizing that Brando and I are different people 😂

An #ICML2025 story from yesterday: @BrandoHablando and I made a new friend who told us that she saw me give a talk at NeurIPS 2023 and then messaged Brando to chat, without realizing that Brando and I are different people 😂





















































































































United States Trends
- 1. Auburn 18.4K posts
- 2. #UFCRio 39.3K posts
- 3. Penn State 25K posts
- 4. Indiana 46.1K posts
- 5. James Franklin 12.8K posts
- 6. Oregon 68.8K posts
- 7. Hugh Freeze N/A
- 8. Diane Keaton 204K posts
- 9. Andrew Vaughn 1,161 posts
- 10. Charles 92.4K posts
- 11. Nuss 4,269 posts
- 12. Do Bronx 5,501 posts
- 13. Mateer 12.8K posts
- 14. King Miller N/A
- 15. Michigan 53.7K posts
- 16. #iufb 7,927 posts
- 17. Makai Lemon 1,218 posts
- 18. Drew Allar 6,003 posts
- 19. #AEWCollision 7,023 posts
- 20. Northwestern 9,698 posts
You might like
-
 Daniel Yamins
Daniel Yamins
@dyamins -
 Jascha Sohl-Dickstein
Jascha Sohl-Dickstein
@jaschasd -
 Sophia Sanborn
Sophia Sanborn
@naturecomputes -
 rishi
rishi
@RishiBommasani -
 Patrick Mineault
Patrick Mineault
@patrickmineault -
 Woosuk Kwon
Woosuk Kwon
@woosuk_k -
 Gatsby Computational Neuroscience Unit
Gatsby Computational Neuroscience Unit
@GatsbyUCL -
 SueYeon Chung
SueYeon Chung
@s_y_chung -
 Blake Bordelon ☕️🧪👨💻
Blake Bordelon ☕️🧪👨💻
@blake__bordelon -
 Surya Ganguli
Surya Ganguli
@SuryaGanguli -
 James Whittington
James Whittington
@jcrwhittington -
 Dileep George
Dileep George
@dileeplearning -
 Brando Miranda
Brando Miranda
@BrandoHablando -
 Adrienne Fairhall
Adrienne Fairhall
@alfairhall -
 Alex Williams
Alex Williams
@ItsNeuronal
Something went wrong.
Something went wrong.