
martin palazzo
@boardsofdata
science & startup worker. AI, biotech, manufacturing. @stammbio @udesa
Tal vez te guste















Molecular biology 🧬 wet lab iteration for cell therapies implies intense R&D resources. By leveraging AI, computational biology algorithms and multi-omics assay data @StammBio presents MoNA: a cell representation atlas designed to accelerate bio-innovation cycles. Take a look👇



Data often lie on a low-dimensional manifold embedded in a high-dimensional space. But these manifolds are often highly non-linear, making linear dimensionality reduction methods like PCA insufficient. This has motivated the development of non-linear dimensionality reduction.
Is this a circular RNA reference ? 😅


AI ppl: we basically solved bio with the thinking sands Bio ppl: after decades of lab toil, we solved how to stably express GFP in stem cells

1/ Happy to share important work done with my co-author Andrew Khalil in the labs of Rudolf Jaenisch @WhiteheadInst @MITBiology @MIT and Dave Mooney @Harvard @wyssinstitute trying to assess and fix the major problem of transgene silencing in human ESC/iPSC based work

We’re moving biology from the wet lab to the gpu cluster.

I find it fascinating that momentum in standard convex optimization is just about making convergence faster, but in nonconvex problems, it's sometimes the only way a method can work at all. Just saw a new example of this phenomenon in the case of difference-of-convex functions.


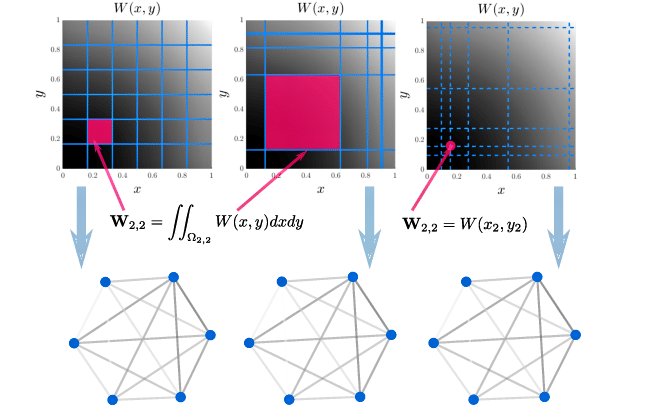
Graphons are mathematical objects that model the structure of massive networks. In machine learning, they provide a powerful framework for analyzing and generating large graphs. They are used to estimate the underlying structure of a network, predict missing links, and understand…

Theorem: The maximum possible duration of the computational singularity is 470 years. Proof: The FLOPs capacity of all computers which existed in the year 1986 is estimated to be at most 4.5e14 (Hilbert et al. 2011). Based on public Nvidia revenue and GPU specs, this capacity…

How does neural feature geometry evolve during training? Modeling feature spaces as geometric graphs, we show that nonlinear activations drive transformations resembling discrete Ricci flow - revealing how class structure emerges and suggesting geometry-informed training…


The simplex method is an algorithm that turns an optimization problem, like setting up an investment portfolio, into a geometry problem. Recently, the scientists Sophie Huiberts (left) and Eleon Bach reduced the runtime of the simplex method. quantamagazine.org/researchers-di…




🚨 We wrote a new AI textbook "Learning Deep Representations of Data Distributions"! TL;DR: We develop principles for representation learning in large scale deep neural networks, show that they underpin existing methods, and build new principled methods.


A 7 million parameter model from Samsung just outperformed DeepSeek-R1, Gemini 2.5 Pro, and o3-mini on reasoning benchmarks like ARC-AGI. Let that sink in. It’s 10,000x smaller yet smarter. The secret is recursion. Instead of brute-forcing answers like giant LLMs, it drafts a…


*The Origins of Representation Manifolds in LLMs* by Modell et al. They study the presence of "interpretable features" in LLMs embedded as manifolds and how their geometry connects to the internal representations of the models. arxiv.org/abs/2505.18235


This new research showed empirically that KL divergence is the most accurate predictor of catastrophic forgetting in LLMs! And since forgetting tracks KL drift from the base, methods that keep KL small tend to forget less too.


HOW INFORMATION FLOWS THROUGH TRANSFORMERS Because I've looked at those "transformers explained" pages and they really suck at explaining. There are two distinct information highways in the transformer architecture: - The residual stream (black arrows): Flows vertically through…



KV caching overcomes statelessness in a very meaningful sense and provides a very nice mechanism for introspection (specifically of computations at earlier token positions) the Value representations can encode information from residual streams of past positions without…

💡 Me encantaron las sesiones de pósters en el Simposio Científico de IA y Aplicaciones #SCIAA2025! Había muchos trabajos interesantes. En particular quiero destacar dos proyectos que me llamaron la atención: 🔹 Impacto del Prompt Engineering en el rendimiento de LLMs: estudio…


Que capo
At 26, during the Reign of Terror in France, Jean-Baptiste Joseph Fourier narrowly avoided the guillotine. A decade later, he made a discovery that changed mathematics forever. @shalmawegs reports: quantamagazine.org/what-is-the-fo…


The most complex biological system that we meaningfully understand is a single virion. Everything more complex than that (including bacteria, single human cells, animals, and of course, humans) is totally beyond our comprehension.
Llego el dia de decidir entre: - Bosch - Makita - DeWalt - Black & Decker

























































































































United States Tendencias
- 1. #UFC322 188K posts
- 2. Islam 298K posts
- 3. Morales 39K posts
- 4. Valentina 16.6K posts
- 5. #byucpl N/A
- 6. Prates 37K posts
- 7. Ilia 8,074 posts
- 8. Sark 6,257 posts
- 9. LING BA TAO HEUNG 436K posts
- 10. #LingTaoHeungAnniversary 434K posts
- 11. Khabib 13.3K posts
- 12. Dagestan 3,459 posts
- 13. Dillon Danis 14.3K posts
- 14. Kirby 18.8K posts
- 15. Georgia 91.3K posts
- 16. Zhang 28.1K posts
- 17. #GoDawgs 9,896 posts
- 18. Ole Miss 12.8K posts
- 19. #Toonami 2,505 posts
- 20. Weili 8,869 posts
Tal vez te guste
-
 gabo mindlin
gabo mindlin
@GaboMindlin -
 Laboratorio de Inteligencia Artificial Aplicada
Laboratorio de Inteligencia Artificial Aplicada
@liaa_icc -
 Diego F. Slezak
Diego F. Slezak
@dfslezak -
 factor~data
factor~data
@FactorData -
 Pablo Groisman 🎲
Pablo Groisman 🎲
@pgroisma -
 Machín Lenin
Machín Lenin
@MachinLenin -
 Enzo Ferrante
Enzo Ferrante
@enzoferrante -
 Maestria Data Mining
Maestria Data Mining
@DataminingDC -
 Data Science Argentina
Data Science Argentina
@DataScienceArg -
 R en Buenos Aires
R en Buenos Aires
@renbaires -
 Juan Manuel Pérez
Juan Manuel Pérez
@perezjotaeme -
 Instituto sinc(i) - UNL/CONICET
Instituto sinc(i) - UNL/CONICET
@sinc_i -
 Pablo Zivic
Pablo Zivic
@ideasrapidas -
 Rodrigo Echeveste
Rodrigo Echeveste
@RSEcheveste -
 Agustín Gravano
Agustín Gravano
@AgustinGravano
Something went wrong.
Something went wrong.