
Chris Glaze
@chris_m_glaze
Principal Research Scientist at @SnorkelAI. PhD in computational neuroscience. Previously: @penn @UofMaryland

SnorkelAI is headed to #NeurIPS2025 this December with @fredsala and the team. Come talk benchmarks, rubrics, RL envs, & more. 🔬✨


Chain-of-thought just became the newest safety nightmare in AI, and nobody was ready for this. A team from Anthropic, Stanford, and Oxford found something brutal: if you wrap a harmful request inside a long, harmless reasoning chain, the model’s guardrails weaken until it stops…

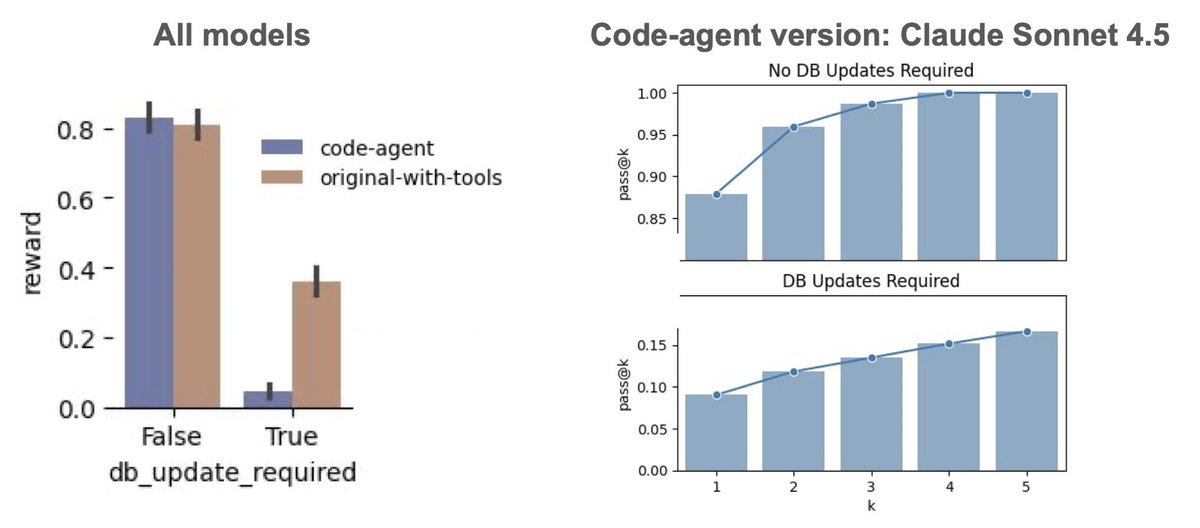
What’s the future-state of AI agents in real-world scenarios? How often will they just solve problems as coders vs interacting with more constrained but complex tool sets? Models like Claude Sonnet 4.5 are indeed impressive at coding and can in theory use these same skills to…
New from @ArminPCM : how Snorkel builds reinforcement learning (RL) environments that train and evaluate agents in realistic, enterprise-grade settings.


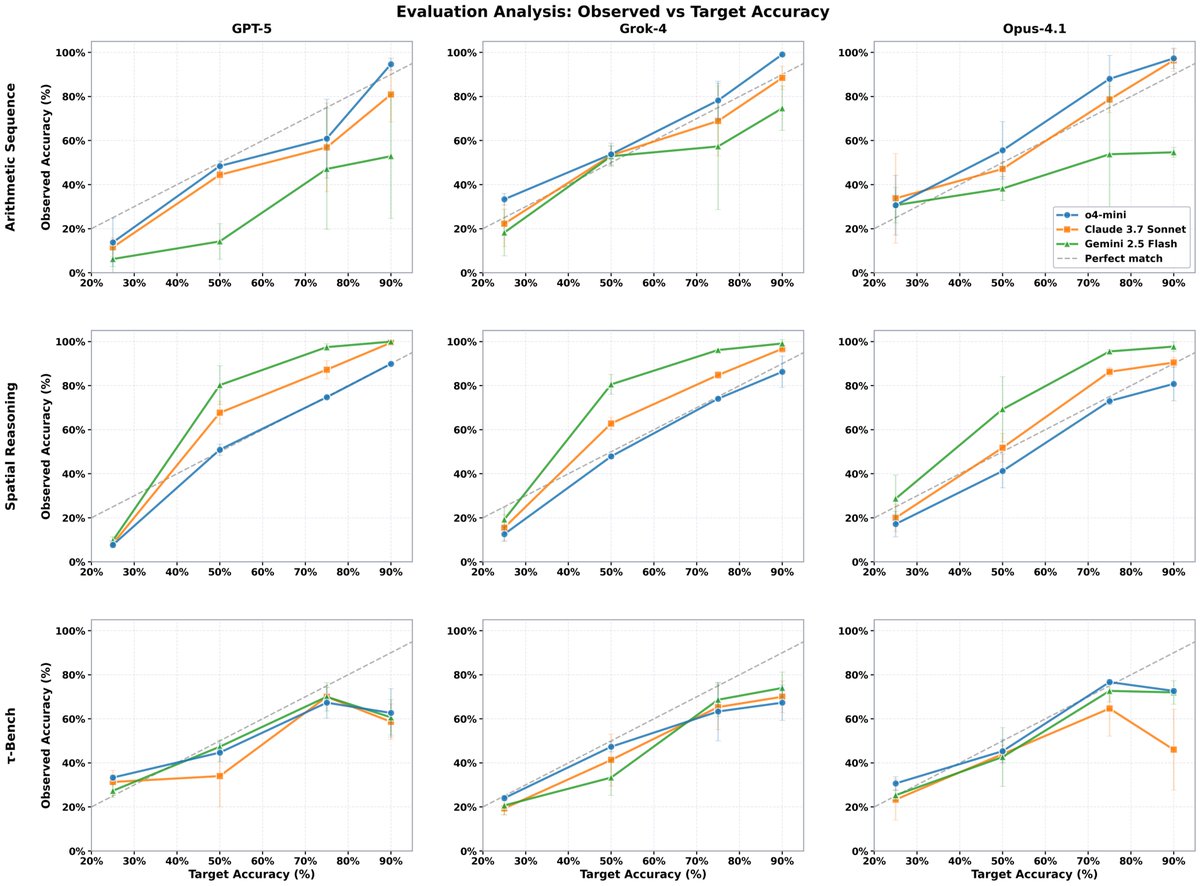
🚨 New research from @SnorkelAI tackles a critical problem: LLMs are evolving faster than our ability to evaluate them 📊 We develop BeTaL— Benchmark Tuning with an LLM-in-the-loop— a framework that automates benchmark design using reasoning models as optimizers. BeTaL produces…

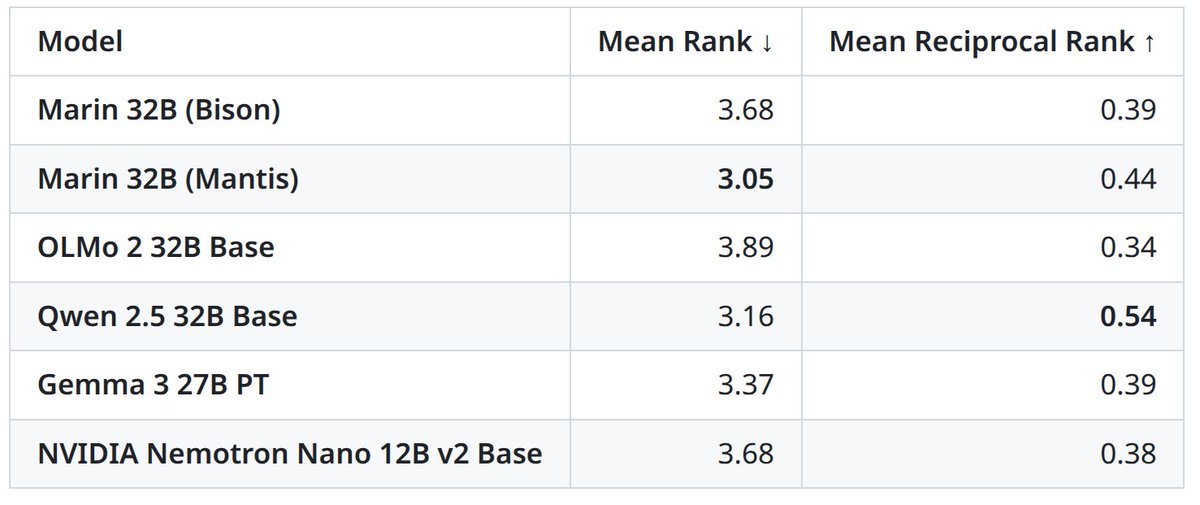
⛵Marin 32B Base (mantis) is done training! It is the best open-source base model (beating OLMo 2 32B Base) and it’s even close to the best comparably-sized open-weight base models, Gemma 3 27B PT and Qwen 2.5 32B Base. Ranking across 19 benchmarks:
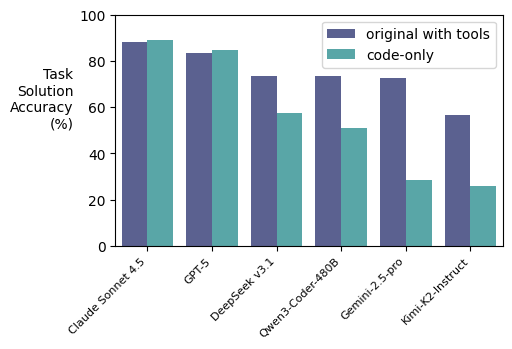
Just how good are AI agents at exploring their environments in novel ways to solve real-world enterprise problems? As part of our ongoing experiments around agentic autonomy at @SnorkelAI we’re making “code-only” versions of environments in which we challenge agents to solve…



Super excited to present our new work on hybrid architecture models—getting the best of Transformers and SSMs like Mamba—at #COLM2025! Come chat with @nick11roberts at poster session 2 on Tuesday. Thread below! (1)

Black holes just proved Stephen Hawking right with the clearest signal yet sciencedaily.com/releases/2025/…
AI eval:basic software testing :: AI capability:basic software capability. AI evals are difficult to get right (is probably why we see <<80% agreement rates often). Requires critical thinking about the problem domain, usability, objectives. Rubrics are vital and their…

Trend I'm following: evals becoming a must-have skill for product builders and AI companies. It's the first new hard skill in a long time that PMs/engineers/founders have had to learn to be successful. The last one was maybe SQL, and Excel? A few examples: @garrytan: "Evals are…
The term “horizon” is used inconsistently in the LM benchmarking lit, and not always super aligned with how the term is used in the RL lit. TL;DR: long horizon ≠ complex. Frontier models may do well on complex tasks but can still fail on basics of long horizon planning. METR…

Definitely tracks with our observations. Point (3) especially begs for how to most effectively involve experts in the dev process.

Most takes on RL environments are bad. 1. There are hardly any high-quality RL environments and evals available. Most agentic environments and evals are flawed when you look at the details. It’s a crisis: and no one is talking about it because they’re being hoodwinked by labs…
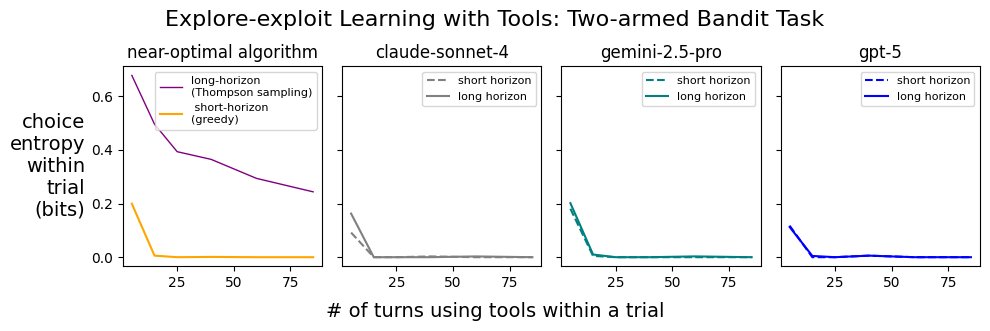
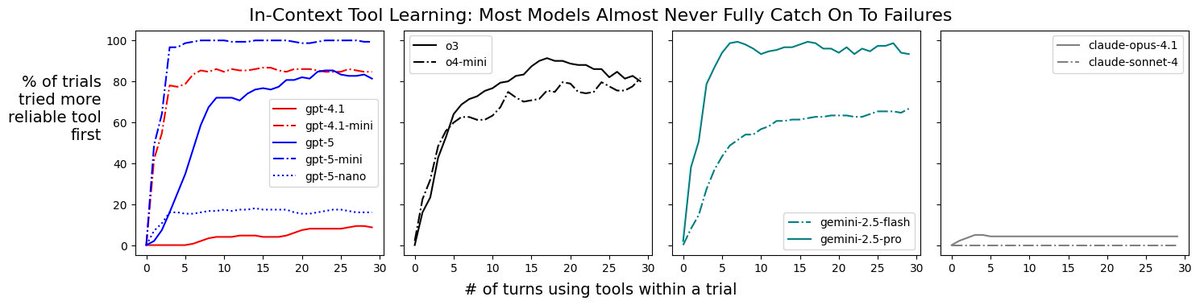
From ongoing idealized experiments I've been running on AI agents at @SnorkelAI: in this one, most frontier models either (1) are slow to learn about tool-use failures in-context or (2) have a very high tolerance for these failures, showing almost no in-context learning at all.…
Tested gpt-oss-120b on @SnorkelAI 's agent benchmarks - performance seems split on real world tasks. It did well on multi-step Finance, but poorly on multi-turn Insurance. Think this could be a limitation of either domain knowledge or handling multi-turn scenarios.

Agentic AI will transform every enterprise–but only if agents are trusted experts. The key: Evaluation & tuning on specialized, expert data. I’m excited to announce two new products to support this–@SnorkelAI Evaluate & Expert Data-as-a-Service–along w/ our $100M Series D! ---…
There is an explosion of total nonsense around LLM auto-eval in the space these days... be wary of approaches that claim to kick the human out of the loop! E.g. 'Using GPT-4 to auto-eval' makes sense only if you are trying to *distill* GPT-4 functionality. I.e. you are…
4/ Either way, the key step remains the same- tuning LLM systems on good data! Whether tuning/aligning an LLM or an LLM + RAG system, the key is the data you use, and how you develop it! Check out our work here @SnorkelAI !
🎉We are making big strides towards programmatic alignment! Using a reward model w/ DPO, Snorkel AI ranked 2nd on the AlpacaEval 2.0 LLM leaderboard using only a 7B model! Hear from the researcher behind this achievement at our Enterprise LLM Summit tomorrow! #SnorkelAI #AI #LLMs…




























































































United States Trends
- 1. #GMMTV2026 3.24M posts
- 2. Good Tuesday 32.2K posts
- 3. MILKLOVE BORN TO SHINE 491K posts
- 4. #tuesdayvibe 2,426 posts
- 5. #NuestraBanderaEsBolívar 1,620 posts
- 6. Taco Tuesday 11.3K posts
- 7. Kelly 332K posts
- 8. WILLIAMEST MAGIC VIBES 65.3K posts
- 9. Alan Dershowitz 3,595 posts
- 10. #DittoSeries 90.8K posts
- 11. Enron 1,697 posts
- 12. Barcelona 168K posts
- 13. MAGIC VIBES WITH JIMMYSEA 87.1K posts
- 14. University of Minnesota N/A
- 15. JOSSGAWIN MAGIC VIBES 28.6K posts
- 16. #TuesdayFeeling 1,087 posts
- 17. MAGIC VIBES WITH EMIBONNIE 114K posts
- 18. TOP CALL 9,459 posts
- 19. AI Alert 8,194 posts
- 20. Maddow 16.6K posts
Something went wrong.
Something went wrong.