
The wait is over! As the leading AI code review tool, CodeRabbit was given early access to OpenAI's GPT-5 model to evaluate the LLM's ability to reason through and find errors in complex codebases! Our evals found GPT-5 performed up to 190% better than other leading models!
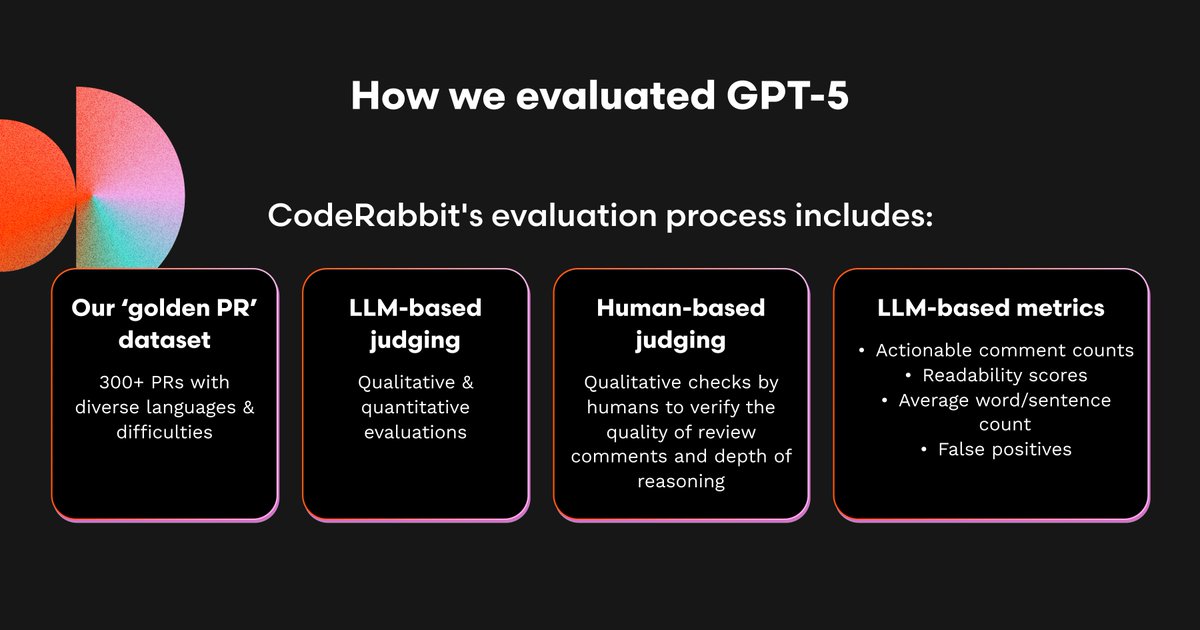
As part of our GPT-5 testing, we conducted extensive evals to uncover the model’s technical nuances, capabilities, and use cases around common code review tasks using over 300 carefully selected PRs.
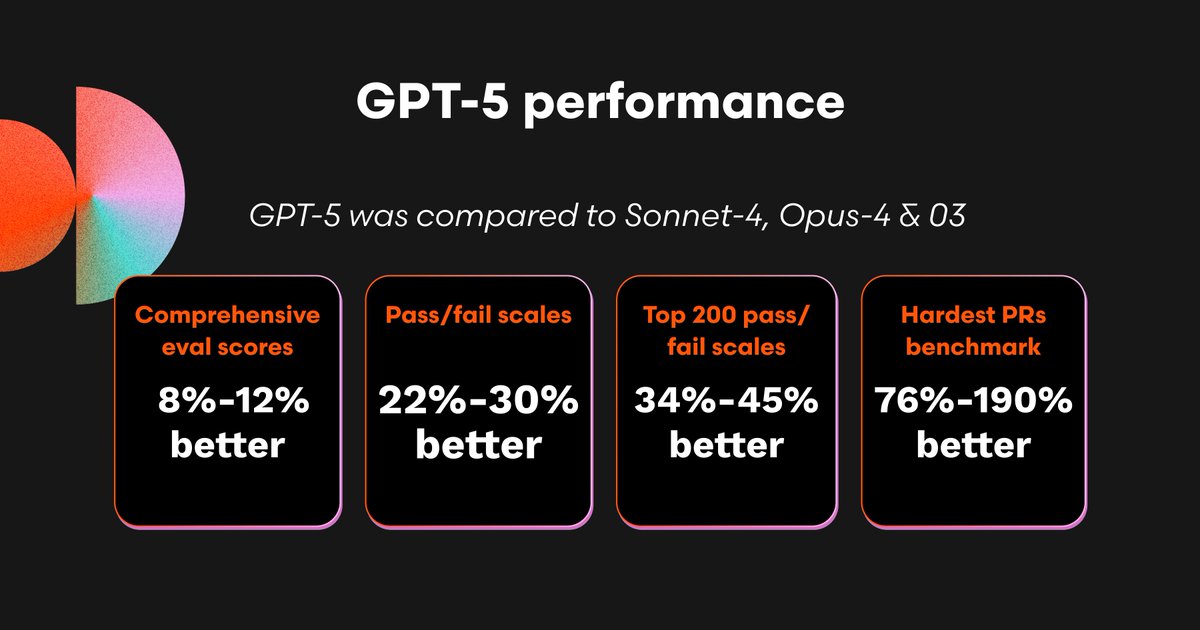
Across the whole dataset, GPT-5 outperformed Opus-4, Sonnet-4, and OpenAI's O3 on a battery of 300 varying difficulty, error diverse pull requests – representing a 22%-30% improvement over other models

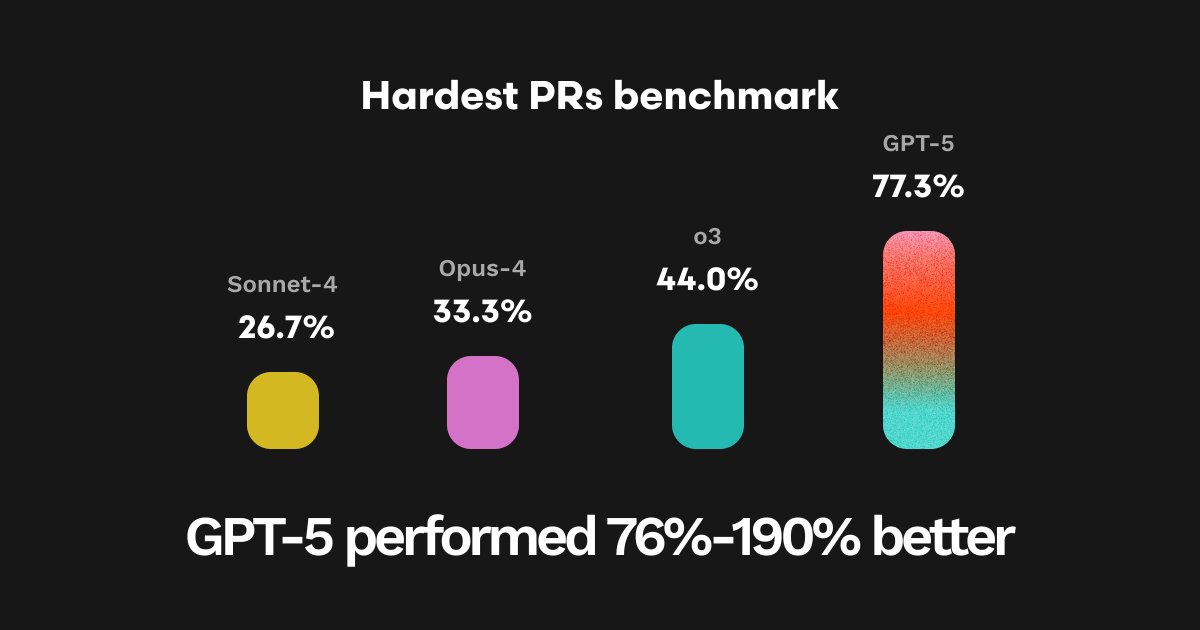
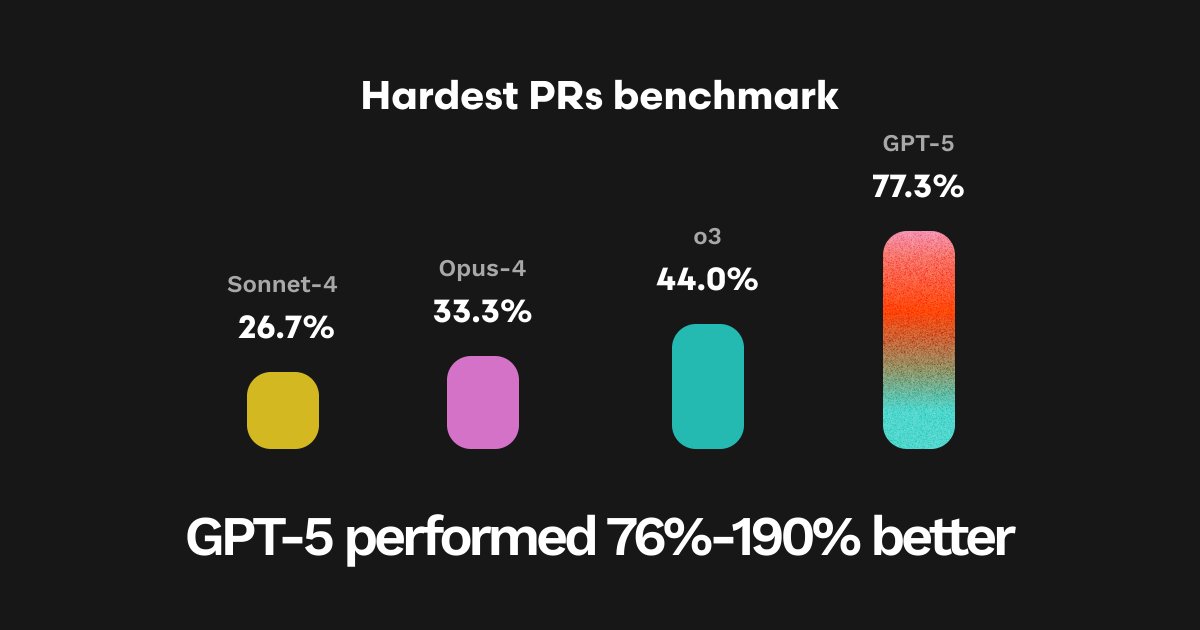
We then tested GPT-5 on the hardest 200 PRs to see how much better it did on particularly hard to spot issues and bugs. It found 157 out of 200 bugs where other models found between 108 and 117. That represents a 34%-45% improvement!

On our 25 hardest PRs from our evaluation dataset, GPT-5 achieved the highest ever overall pass rate (77.3%), representing a 190% improvement over Sonnet-4, 132% over Opus-4, and 76% over O3.
Our results show that GPT-5 represents a significant improvement in the ability to reason through a codebase and find issues – thanks to some new capabilities.

Check out our in-depth testing process with detailed results and examples in our latest blog. coderabbit.ai/blog/benchmark…





So, 🐰 is about to roast my PRs more than ever with GPT-5 in the sweetest way possible, huh?


It’s looking good for GPT-5! Totally depends on your use case though doesn’t it, our new blog goes more in depth as to the testing and use-cases we used! coderabbit.ai/blog/benchmark…


We only tested GPT-5 against previous top performers on our tests and ultimately grok 4 didn’t perform up to the same standard so wasn’t used in this test!


How did the comparison stand with opus 4.1 and grok 4? Those are the leading models from competitors and they should present in comparison.
We only tested GPT-5 against previous top performers on our tests and ultimately grok 4 didn’t perform up to the same standard so wasn’t used in this test!


sounds like some solid testing there. if those numbers hold up, that could change the game for code reviews. curious to see how it holds up in real-world scenarios.


Seeing GPT-5’s reasoning boost makes me wonder—how will this impact the pace of catching subtle bugs that often slip through tests? 🤔 Would love to see some real-world debugging examples from CodeRabbit!

I wish, the evaluation code is publicly avaliable. So, other labs can do validation.

What about the smaller models like gpt5 if it is on sonnet 4 level that would be a massive price advantage.

United States Tendenze
- 1. #VSFashionShow 399K posts
- 2. #AEWDynamite 11.4K posts
- 3. #youtubedown 14.1K posts
- 4. #Survivor49 2,530 posts
- 5. tzuyu 145K posts
- 6. Angel Reese 32.4K posts
- 7. George Kirby 1,727 posts
- 8. quen 22.5K posts
- 9. Darby 3,585 posts
- 10. jihyo 132K posts
- 11. #AbbottElementary 1,529 posts
- 12. madison 65.4K posts
- 13. Missy 9,914 posts
- 14. Karol G 56.7K posts
- 15. Sabres 5,113 posts
- 16. bella hadid 65.2K posts
- 17. Birdman 3,469 posts
- 18. Nancy 128K posts
- 19. Claudio 13.5K posts
- 20. Bieber 16.6K posts
Something went wrong.
Something went wrong.