
The wait is over! As the leading AI code review tool, CodeRabbit was given early access to OpenAI's GPT-5 model to evaluate the LLM's ability to reason through and find errors in complex codebases! Our evals found GPT-5 performed up to 190% better than other leading models!
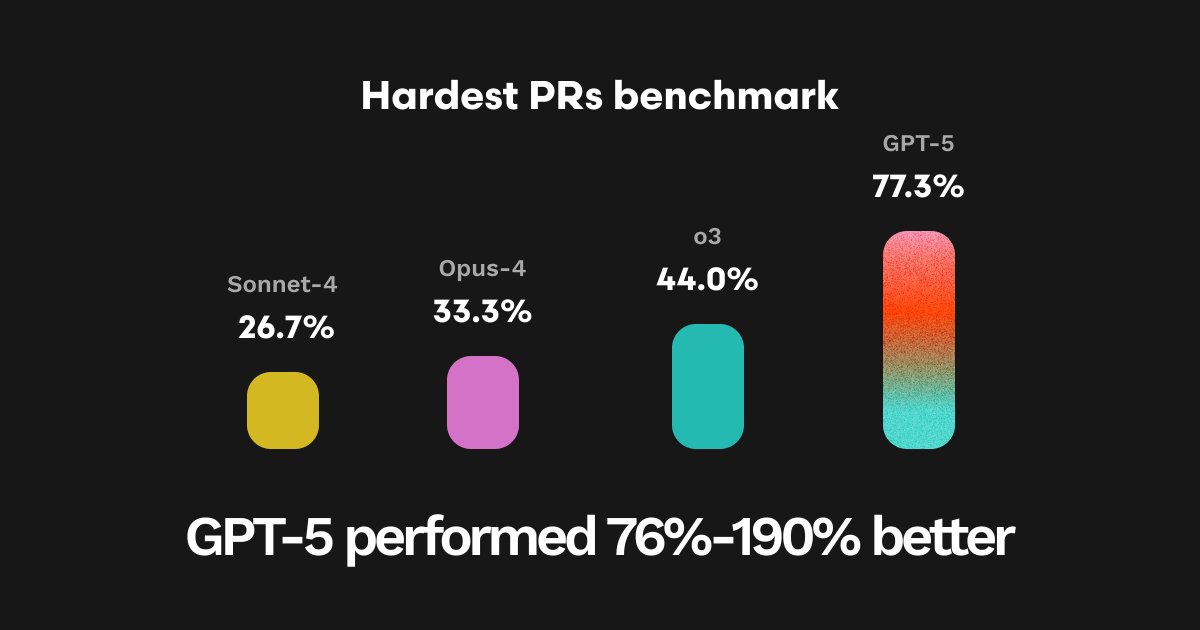

How did the comparison stand with opus 4.1 and grok 4? Those are the leading models from competitors and they should present in comparison.
We only tested GPT-5 against previous top performers on our tests and ultimately grok 4 didn’t perform up to the same standard so wasn’t used in this test!
United States Trends
- 1. Prince Andrew 30.9K posts
- 2. No Kings 275K posts
- 3. Duke of York 14.5K posts
- 4. #BostonBlue N/A
- 5. Chandler Smith N/A
- 6. Zelensky 73.7K posts
- 7. Andrea Bocelli 20.3K posts
- 8. Strasbourg 26.3K posts
- 9. #DoritosF1 N/A
- 10. zendaya 9,599 posts
- 11. #SELFIESFOROLIVIA N/A
- 12. #FursuitFriday 17.3K posts
- 13. trisha paytas 4,186 posts
- 14. Arc Raiders 7,239 posts
- 15. #CashAppFriday N/A
- 16. Apple TV 12.4K posts
- 17. TPOT 20 SPOILERS 11.9K posts
- 18. Trevon Diggs 1,571 posts
- 19. Louisville 4,470 posts
- 20. My President 50.9K posts
Loading...
Something went wrong.
Something went wrong.