
The wait is over! As the leading AI code review tool, CodeRabbit was given early access to OpenAI's GPT-5 model to evaluate the LLM's ability to reason through and find errors in complex codebases! Our evals found GPT-5 performed up to 190% better than other leading models!
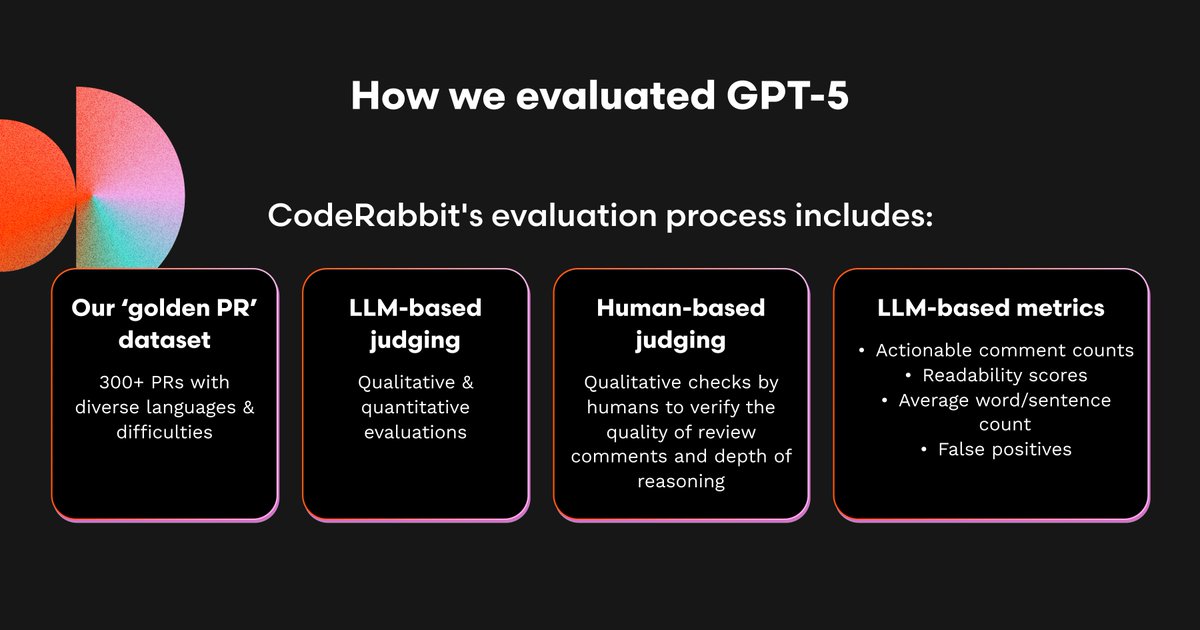
As part of our GPT-5 testing, we conducted extensive evals to uncover the model’s technical nuances, capabilities, and use cases around common code review tasks using over 300 carefully selected PRs.
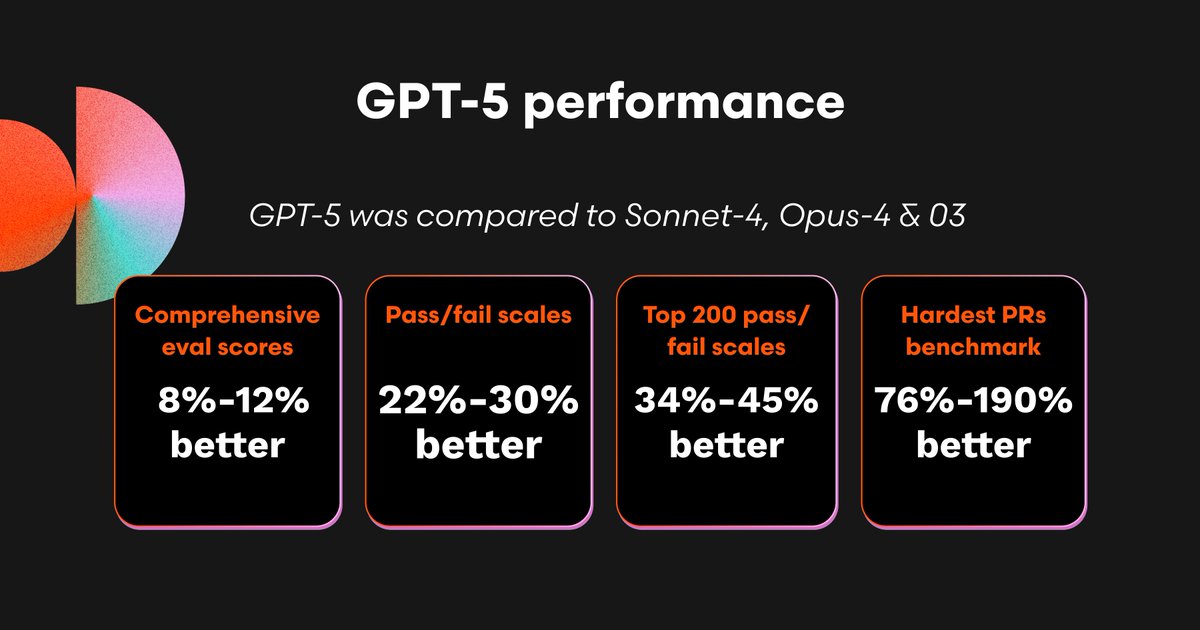
Across the whole dataset, GPT-5 outperformed Opus-4, Sonnet-4, and OpenAI's O3 on a battery of 300 varying difficulty, error diverse pull requests – representing a 22%-30% improvement over other models

We then tested GPT-5 on the hardest 200 PRs to see how much better it did on particularly hard to spot issues and bugs. It found 157 out of 200 bugs where other models found between 108 and 117. That represents a 34%-45% improvement!

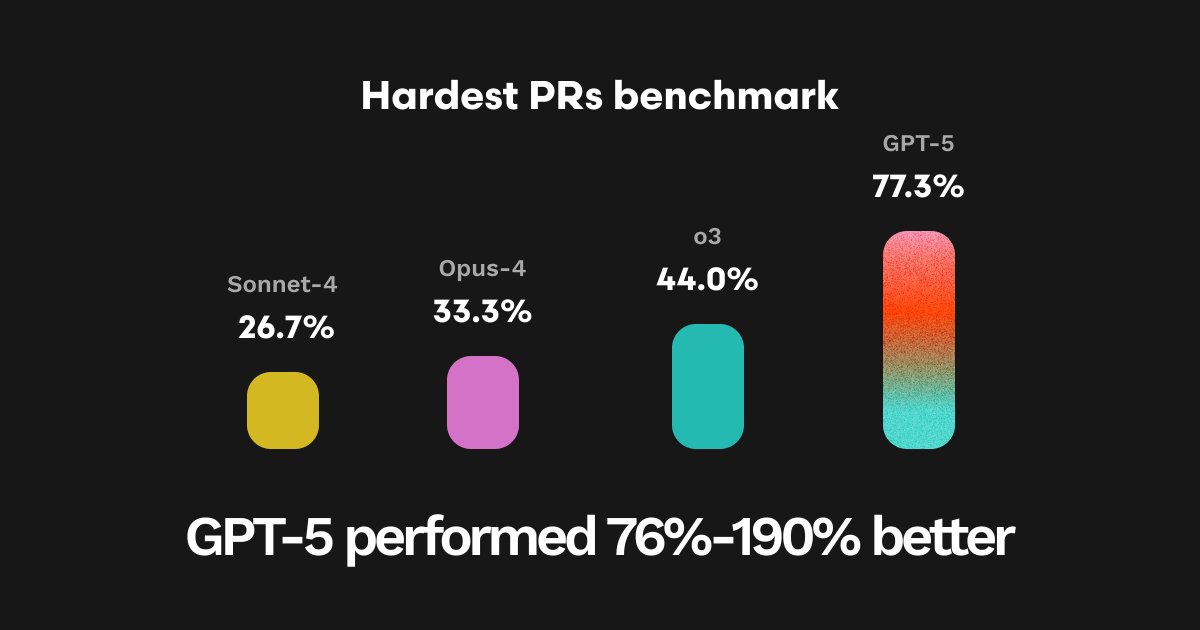
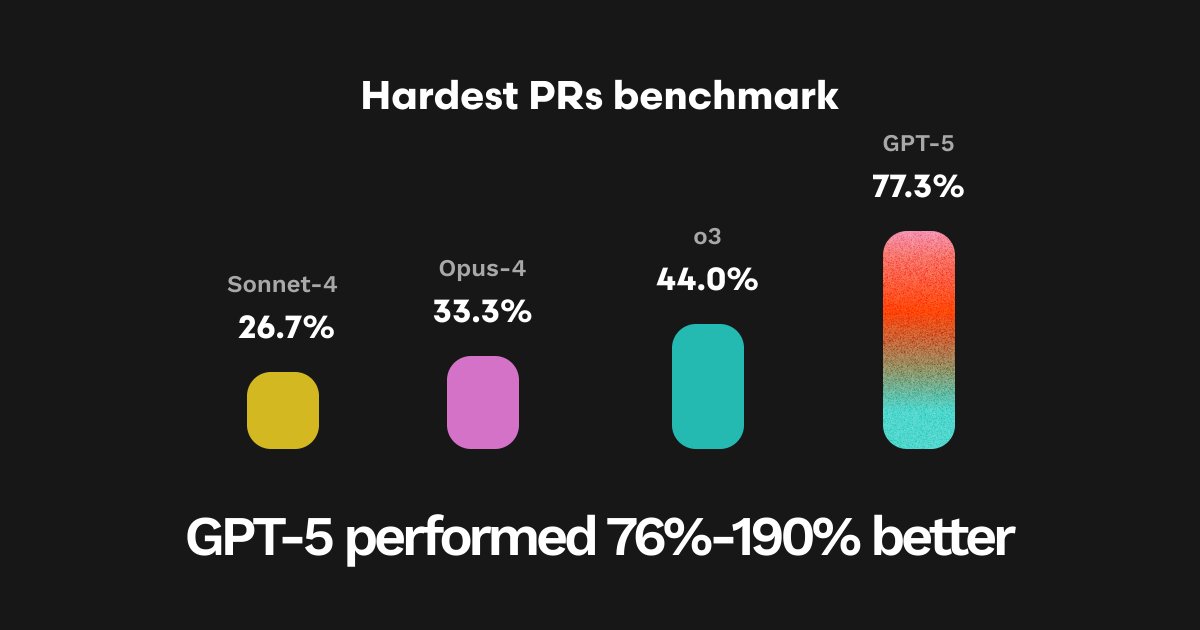
On our 25 hardest PRs from our evaluation dataset, GPT-5 achieved the highest ever overall pass rate (77.3%), representing a 190% improvement over Sonnet-4, 132% over Opus-4, and 76% over O3.
Our results show that GPT-5 represents a significant improvement in the ability to reason through a codebase and find issues – thanks to some new capabilities.

Check out our in-depth testing process with detailed results and examples in our latest blog. coderabbit.ai/blog/benchmark…
United States 트렌드
- 1. Carson Beck 5,577 posts
- 2. #SmackDown 42.8K posts
- 3. Ohtani 42.7K posts
- 4. Louisville 13.8K posts
- 5. Miami 81.4K posts
- 6. Malachi Toney 2,112 posts
- 7. George Santos 58K posts
- 8. #BostonBlue 3,168 posts
- 9. Geno 8,564 posts
- 10. Chris Bell 1,539 posts
- 11. Ilja 17.3K posts
- 12. #SeizeTheMoment 8,581 posts
- 13. #OPLive 1,681 posts
- 14. Cal Raleigh 5,272 posts
- 15. Springer 9,197 posts
- 16. Grand Slam 8,144 posts
- 17. Sami 24.3K posts
- 18. Raiola 1,800 posts
- 19. #LGRW 2,179 posts
- 20. Jeff Brohm N/A
Something went wrong.
Something went wrong.