
내가 좋아할 만한 콘텐츠













Holy shit. MIT just built an AI that can rewrite its own code to get smarter 🤯 It’s called SEAL (Self-Adapting Language Models). Instead of humans fine-tuning it, SEAL reads new info, rewrites it in its own words, and runs gradient updates on itself literally performing…


Nonsense. AlexNet (2012) was similar to DanNet (2011) which won 4 image recognition contests before AlexNet (first superhuman performance in 2011). See people.idsia.ch/~juergen/DanNe…


Amazing that @SchmidhuberAI gave this talk back in 2012, months before AlexNet paper was published. In 2012, many things he discussed, people just considered to be funny and a joke, but the same talk now would be considered at the center of AI debate and controversy. Full talk:
The in-context learner of the "beautiful @GoogleResearch paper" is a meta learner like @HochreiterSepp's 2001 meta LSTM [1] which learned by gradient descent (GD) a learning algorithm that outperformed GD - no test time weight changes! Since 1992, GD can learn learning algorithms…

Beautiful @GoogleResearch paper. LLMs can learn in context from examples in the prompt, can pick up new patterns while answering, yet their stored weights never change. That behavior looks impossible if learning always means gradient descent. The mechanisms through which this…


proof of work for research credibility has fundamentally shifted. It used to be, get PhD → publish papers → establish authority. Now it is, ship working systems → open source the code → let results speak. If you think about it the PhD was never really about the research…
Everybody talks about recursive self-improvement & Gödel Machines now & how this will lead to AGI. What a change from 15 years ago! We had AGI'2010 in Lugano & chaired AGI'2011 at Google. The backbone of the AGI conferences was mathematically optimal Universal AI: the 2003 Gödel…


Attention!! Our TiRex time series model, built on xLSTM, is topping all major international leaderboards. A European-developed model is leading the field—significantly ahead of U.S. competitors like Amazon, Datadog, Salesforce, and Google, as well as Chinese models from Alibaba.

We’re excited to introduce TiRex — a pre-trained time series forecasting model based on an xLSTM architecture.

Well it was not "of course" to find his name cited in the Absolute Zero Data paper


After supervising 20+ papers, I have highly opinionated views on writing great ML papers. When I entered the field I found this all frustratingly opaque So I wrote a guide on turning research into high-quality papers with scientific integrity! Hopefully still useful for NeurIPS

This LLM from Meta skips the tokenizer, reading text like computers do (bytes!) for better performance. The training and inference code for BLT is released on GitHub. @AIatMeta just released the model weights for their 8B-param Dynamic Byte Latent Transformer (BLT), an…
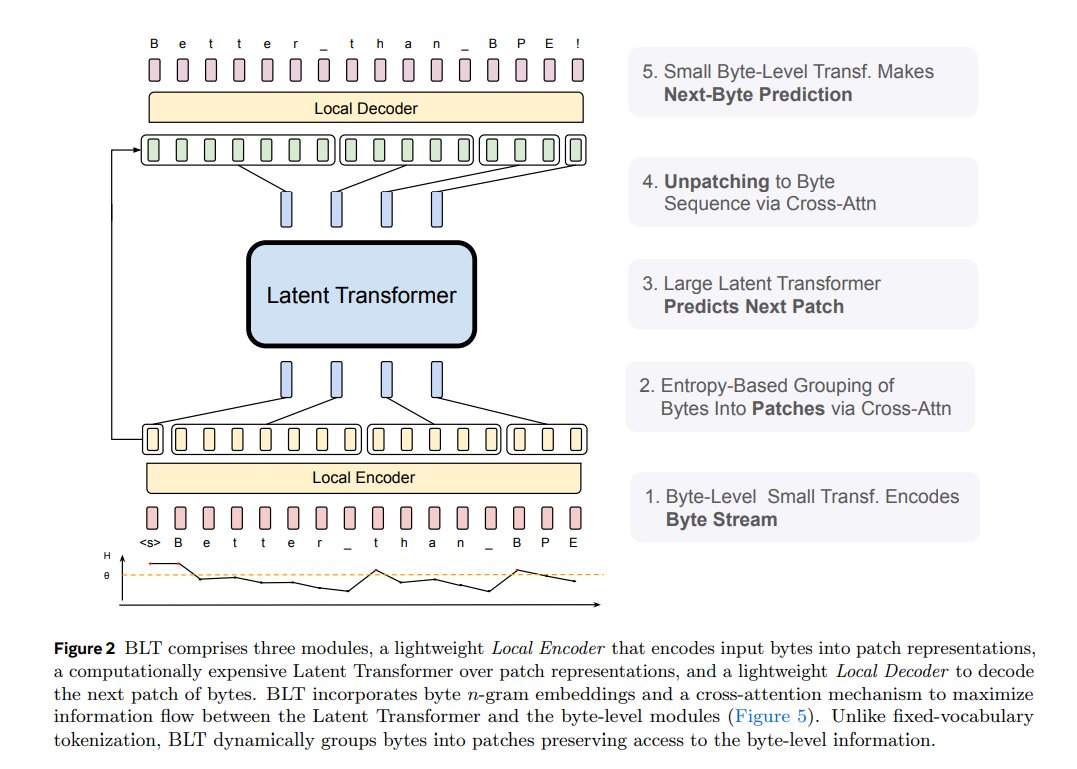

We’re releasing model weights for our 8B- parameter Dynamic Byte Latent Transformer, an alternative to traditional tokenization methods with the potential to redefine the standards for language model efficiency and reliability. Learn more about how Dynamic Byte Latent…

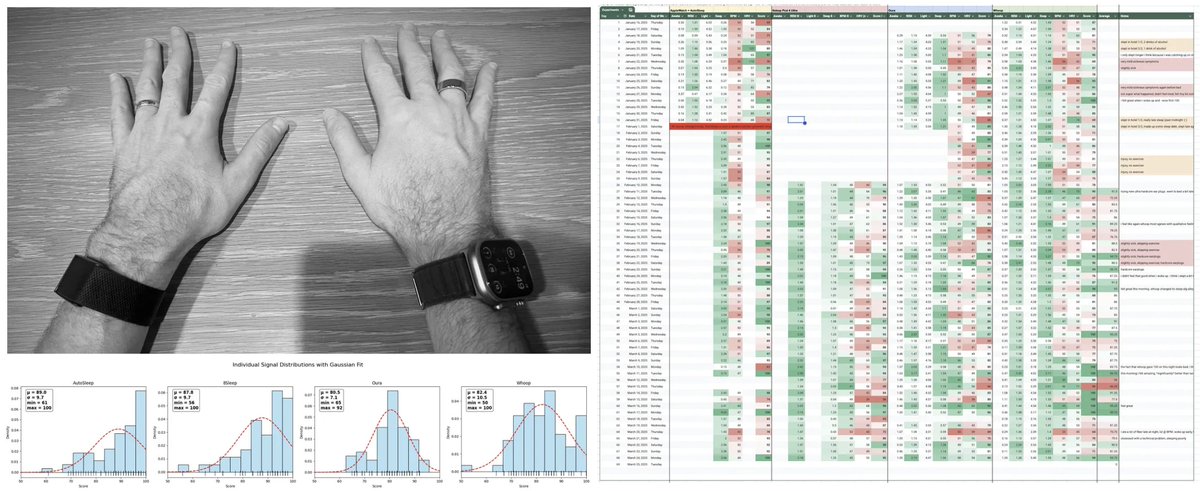
This is an excellent write up by @karpathy . "Yes, sleep matters. Overall, I will say with absolute certainty that Bryan is basically right, and my sleep scores correlate strongly with the quality of work I am able to do that day. When my score is low, I lack agency, I lack…

"Finding the Best Sleep Tracker" Results of an experiment where I wore 4 sleep trackers every night for 2 months. TLDR Whoop >= Oura > 8Sleep >> Apple Watch + AutoSleep. Link simply right here instead of in a reply because ¯\(ツ)/¯ karpathy.bearblog.dev/finding-the-be…

" It's something comparable to what happened 3.5 billion years ago when life emerged, when chemistry became biology." Jurgen Schmidhuber (@SchmidhuberAI) envisions self-driven AIs expanding from our biosphere to colonize the universe, a transformation on par with the dawn of…
Agency > Intelligence I had this intuitively wrong for decades, I think due to a pervasive cultural veneration of intelligence, various entertainment/media, obsession with IQ etc. Agency is significantly more powerful and significantly more scarce. Are you hiring for agency? Are…

Absolutely true, human history is a sequence of discoveries about our ignorance, so we should accept to be no more the smartest on our planet. The only way to save us from ignorance and increase our knowledge and power, as it always has been.
During the Oxford-style debate at the "Interpreting Europe Conference 2025," I persuaded many professional interpreters to reject the motion: "AI-powered interpretation will never replace human interpretation." Before the debate, the audience was 60-40 in favor of the motion;…
It has been said that AI is the new oil, the new electricity, and the new internet. And the once nimble and highly profitable software companies (MSFT, GOOG, ...) became like utilities, investing in nuclear energy, among other things, to run AI data centres. Open Source and the…


We just released TimesFM-2.0 (jax & pytorch) on Hugging Face (goo.gle/3WdOjZy), with a significant boost in accuracy and maximum context length. TimesFM-2.0 tops the GIFT-Eval (goo.gle/4aeiA0f) leaderboard on point and probabilistic forecasting accuracy metrics.

Re: The (true) story of the "attention" operator ... that introduced the Transformer ... by @karpathy. Not quite! The nomenclature has changed, but in 1991, there was already what is now called an unnormalized linear Transformer with "linearized self-attention" [TR5-6]. See (Eq.…
The (true) story of development and inspiration behind the "attention" operator, the one in "Attention is All you Need" that introduced the Transformer. From personal email correspondence with the author @DBahdanau ~2 years ago, published here and now (with permission) following…


Yeah

Elon Musk: We should let ideas compete, not suppress them. “I think we should embrace a diversity of views, and we should have reasonable arguments, and we should have debates. The essence of free speech is that ideas survive when they're competing ideas in the marketplace of…





























































































United States 트렌드
- 1. John Bolton 73.9K posts
- 2. #NationalBreadDay 1,458 posts
- 3. Ace Frehley 2,486 posts
- 4. Asheville 5,642 posts
- 5. Putin 184K posts
- 6. #KonamiWorldSeriesSweepstakes 2,031 posts
- 7. Mitch McConnell 39.5K posts
- 8. Steelers 25.4K posts
- 9. Term 196K posts
- 10. Curt Cignetti 5,893 posts
- 11. Andrade 12.1K posts
- 12. Espionage Act 11.5K posts
- 13. #2025MAMAVOTE 1.7M posts
- 14. Former Trump 22K posts
- 15. Smartmatic 3,306 posts
- 16. Carter Hart 4,385 posts
- 17. Nissan 5,023 posts
- 18. AJ Green 1,257 posts
- 19. Dairy Bird N/A
- 20. Jaylen Warren 1,329 posts
내가 좋아할 만한 콘텐츠
-
 Gabriele Sarti
Gabriele Sarti
@gsarti_ -
 Lorenzo Giusti
Lorenzo Giusti
@lorgiusti -
 Irene Cannistraci
Irene Cannistraci
@ire_cannistraci -
 Valeria Ruscio
Valeria Ruscio
@RuscioValeria -
 Marcello Politi
Marcello Politi
@Marcello_AI -
 Valentino Maiorca
Valentino Maiorca
@ValeMaiorca -
 Alessandra T. Cignarella
Alessandra T. Cignarella
@ale_t_cig -
 Riccardo Marin
Riccardo Marin
@_R_Marin_ -
 Emanuele Giona
Emanuele Giona
@emanuele_giona -
 Leonardo Ranaldi
Leonardo Ranaldi
@l__ranaldi -
 SapienzaStartUpNetwork
SapienzaStartUpNetwork
@sapienza_up -
 Machine Quest
Machine Quest
@machine_quest
Something went wrong.
Something went wrong.