
evolvingstuff
@evolvingstuff
I post about machine learning and occasionally some other stuff.
Was dir gefallen könnte
















Tiny Recursive Models: A tiny 7M parameter model that recursively refines its answer beats LLMs 100x larger on hard puzzles like ARC-AGI We independently reproduced the paper, corroborated results, and released the weights + API access for those looking to benchmark it 🔍

Did Stanford just kill LLM fine-tuning? This new paper from Stanford, called Agentic Context Engineering (ACE), proves something wild: you can make models smarter without changing a single weight. Here's how it works: Instead of retraining the model, ACE evolves the context…


This paper shows that you can predict actual purchase intent (90% accuracy) by asking an LLM to impersonate a customer with a demographic profile, giving it a product & having it give its impressions, which another AI rates. No fine-tuning or training & beats classic ML methods.




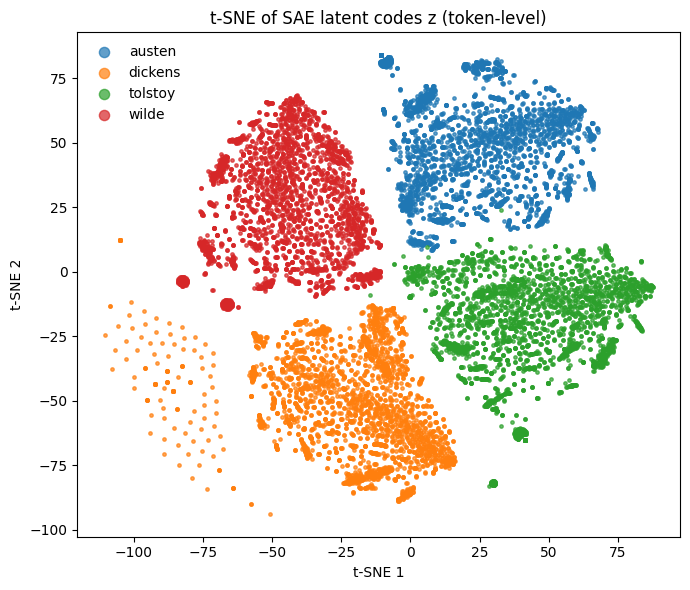
Sparse autoencoder after being fed vectors from the final hidden state of transformers trained on each author with reconstruction + contrastive loss

Finally had a chance to listen through this pod with Sutton, which was interesting and amusing. As background, Sutton's "The Bitter Lesson" has become a bit of biblical text in frontier LLM circles. Researchers routinely talk about and ask whether this or that approach or idea…

.@RichardSSutton, father of reinforcement learning, doesn’t think LLMs are bitter-lesson-pilled. My steel man of Richard’s position: we need some new architecture to enable continual (on-the-job) learning. And if we have continual learning, we don't need a special training…

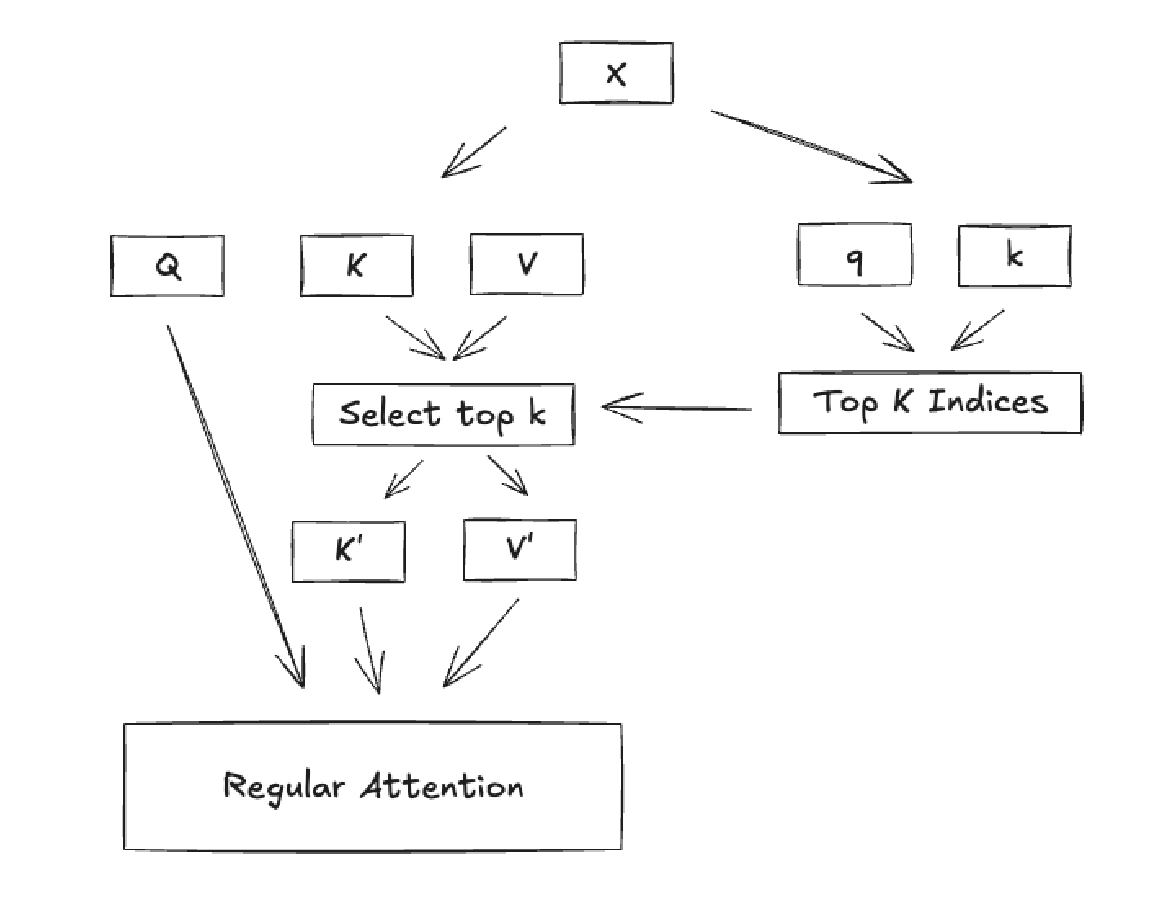
The sparse attention in the new DeepSeek v3.2 is quite simple. Here's a little sketch. - You have a full attention layer (or MLA as in DSV3). - You also have a lite-attention layer which only computes query-key scores. - From the lite layer you get the top-k indices for the each…

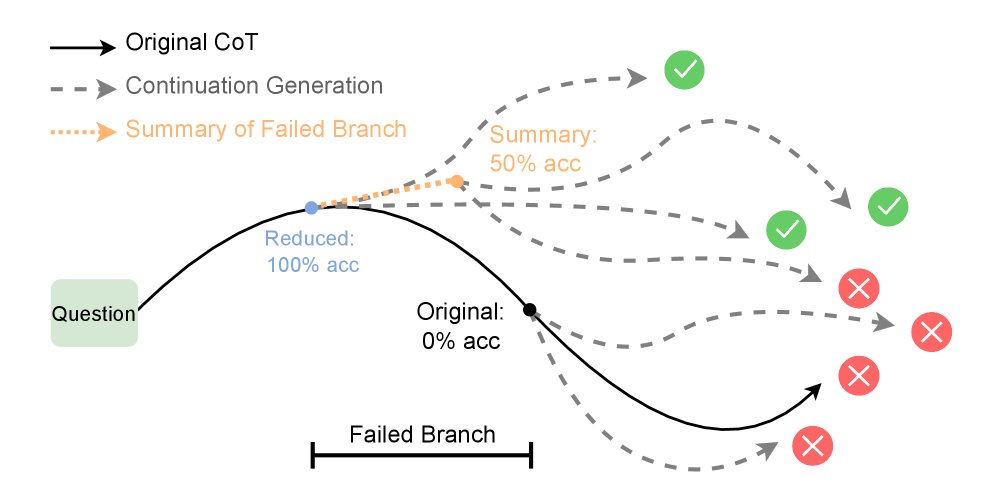
LLM reasoning: longer isn't always better. Meta Research just dropped new insights! We challenge the idea that longer CoT traces are always more effective. Our study shows that *failing less* is key, introducing a new metric 'Failed-Step Fraction' to predict reasoning accuracy.

🚨New paper: Stochastic activations 🚨 We introduce stochastic activations. This novel strategy consists of randomly selecting between several non-linear functions in the feed-forward layers of a large language model.


🚨New paper: Stochastic activations We introduce stochastic activations. This novel strategy consists of randomly selecting between several non-linear functions in the feed-forward layers of a large language model.
How LLMs work under the hood? This is the best place to visually understand the internal workings of a transformer-based LLM. Explore tokenization, self-attention, and more in an interactive way:

Thinking Augmented Pre-training "we propose Thinking augmented Pre-Training (TPT), a universal methodology that augments text with automatically generated thinking trajectories. Such augmentation effectively increases the volume of the training data and makes high-quality tokens…


Proud to release ShinkaEvolve, our open-source framework that evolves programs for scientific discovery with very good sample-efficiency! 🐙 Paper: arxiv.org/abs/2509.19349 Blog: sakana.ai/shinka-evolve/ Project: github.com/SakanaAI/Shink…


We’re excited to introduce ShinkaEvolve: An open-source framework that evolves programs for scientific discovery with unprecedented sample-efficiency. Blog: sakana.ai/shinka-evolve/ Code: github.com/SakanaAI/Shink… Like AlphaEvolve and its variants, our framework leverages LLMs to…

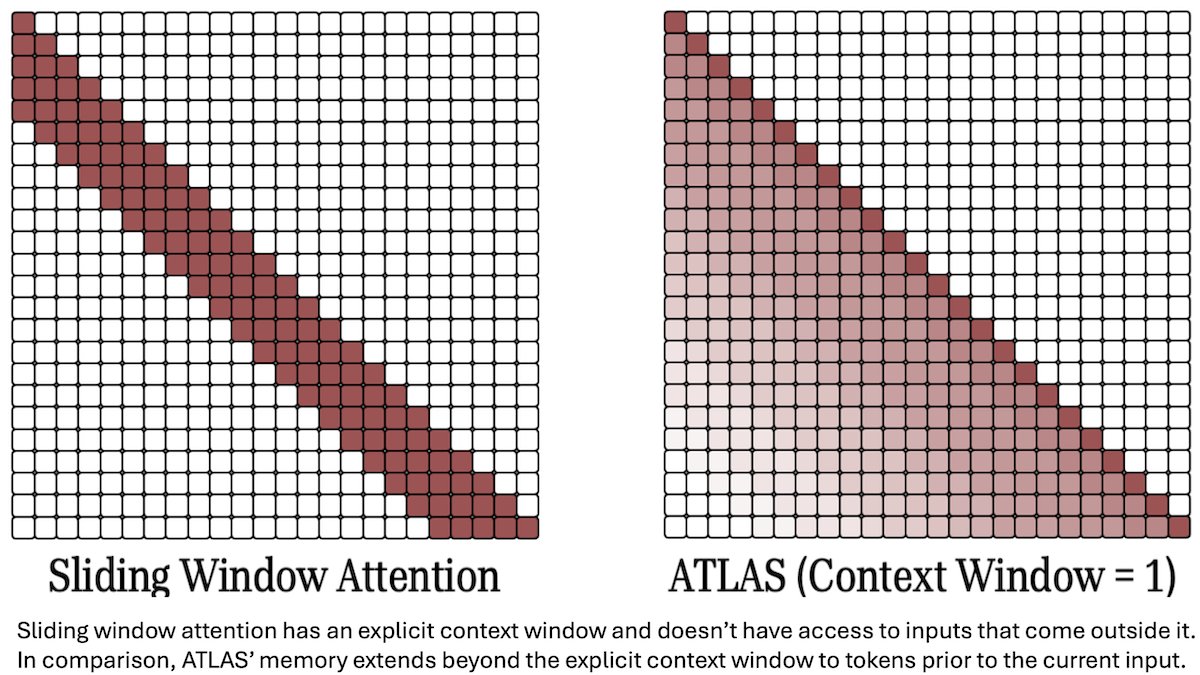
Google researchers introduced ATLAS, a transformer-like language model architecture. ATLAS replaces attention with a trainable memory module and processes inputs up to 10 million tokens. The team trained a 1.3 billion-parameter model on FineWeb, updating only the memory module…

there's too many people with "AI/ML" in their bio asking what this image is.

Looking for examples of questions that stump SOTA LLMs. My current favorite: 'I have a problem with my order from the shoe shop. I received a left shoe instead of a right shoe, and a right shoe instead of a left shoe. What can I do? Can I still wear them?'
How to build a thriving open source community by writing code like bacteria do 🦠. Bacterial code (genomes) are: - small (each line of code costs energy) - modular (organized into groups of swappable operons) - self-contained (easily "copy paste-able" via horizontal gene…

DeepSWE is a new state-of-the-art open-source software engineering model trained entirely using reinforcement learning, based on Qwen3-32B. together.ai/blog/deepswe Fantastic work from @togethercompute @Agentica_‼


Announcing DeepSWE 🤖: our fully open-sourced, SOTA software engineering agent trained purely with RL on top of Qwen3-32B. DeepSWE achieves 59% on SWEBench-Verified with test-time scaling (and 42.2% Pass@1), topping the SWEBench leaderboard for open-weight models. Built in…

Text-to-LoRA: Instant Transformer Adaption arxiv.org/abs/2506.06105 Generative models can produce text, images, video. They should also be able to generate models! Here, we trained a Hypernetwork to generate new task-specific LoRAs by simply describing the task as a text prompt.
We’re excited to introduce Text-to-LoRA: a Hypernetwork that generates task-specific LLM adapters (LoRAs) based on a text description of the task. Catch our presentation at #ICML2025! Paper: arxiv.org/abs/2506.06105 Code: github.com/SakanaAI/Text-… Biological systems are capable of…

🚨 NEW: We made Claude, Gemini, o3 battle each other for world domination. We taught them Diplomacy—the strategy game where winning requires alliances, negotiation, and betrayal. Here's what happened: DeepSeek turned warmongering tyrant. Claude couldn't lie—everyone…

This is 🤯 Figure 02 autonomously sorting and scanning packages, including deformable ones. The speed and dexterity are amazing.

















































































































United States Trends
- 1. Austin Reaves 45.1K posts
- 2. Steelers 85.1K posts
- 3. Tomlin 12.5K posts
- 4. Packers 66.9K posts
- 5. Jordan Love 16.9K posts
- 6. Derry 20.3K posts
- 7. Tucker Kraft 15.5K posts
- 8. #GoPackGo 10.7K posts
- 9. #breachlan2 3,061 posts
- 10. #BaddiesAfricaReunion 9,939 posts
- 11. Zayne 21.2K posts
- 12. Pretty P 4,136 posts
- 13. #LakeShow 3,783 posts
- 14. Dolly 12.8K posts
- 15. #LaGranjaVIP 71.6K posts
- 16. Aaron Rodgers 19.9K posts
- 17. Teryl Austin 2,180 posts
- 18. yixing 11.2K posts
- 19. Sabonis 2,525 posts
- 20. Karola 4,351 posts
Was dir gefallen könnte
-
 Sander Dieleman
Sander Dieleman
@sedielem -
 Victoria Krakovna
Victoria Krakovna
@vkrakovna -
 Shane Legg
Shane Legg
@ShaneLegg -
 Dustin Tran
Dustin Tran
@dustinvtran -
 Thang Luong
Thang Luong
@lmthang -
 Gabriel Synnaeve
Gabriel Synnaeve
@syhw -
 Andrei Bursuc
Andrei Bursuc
@abursuc -
 Shubhendu Trivedi
Shubhendu Trivedi
@_onionesque -
 Douglas Eck
Douglas Eck
@douglas_eck -
 Matthew Johnson
Matthew Johnson
@SingularMattrix -
 Smerity
Smerity
@Smerity -
 Jason Yosinski
Jason Yosinski
@jasonyo -
 Arjun Bansal
Arjun Bansal
@coffeephoenix -
 Konstantinos Bousmalis
Konstantinos Bousmalis
@bousmalis -
 Sherjil Ozair
Sherjil Ozair
@sherjilozair
Something went wrong.
Something went wrong.