
你可能会喜欢



little little goals: & spending 2 hours practising new things & spending 2 hours on kaggle everyday & publishing blogs twice a week & small contributions to open source & losing 2 kilos per month -> (24 kilos this year) & finding my optimum sleep cycle (through long experiments)

this is the most based and simple strategy for engineering excellence from first principles. you only need 3 steps: > identify your dream job or what you’d love to do 1 year from now. > search for job postings or look for experts of that field to find which skills you need to…


Building tiny CPUs in the terminal!🤯 🧬 NanoCore — An 8-bit CPU emulator + assembler + TUI debugger 🔥 Fully minimal 256-byte memory with variable-length opcodes 🦀 Written in Rust & built with @ratatui_rs ⭐ GitHub: github.com/AfaanBilal/Nan… #rustlang #ratatui #tui #emulator…

ML engineering that is essential for backend engineers > **model serving & inference APIs.** you'll eventually serve a model. understand latency vs throughput tradeoffs. know when to use REST vs gRPC for predictions. batch inference vs real-time. cold start problems are real. >…

Backend engineering that is essential for ml engineers > API & service design (REST, gRPC) > message queues & event systems (kafka / redis) > databases & caching (postgres / qdrant / memgraph / redis // personal recommendations) > async programming > observability These are…

Written in 2019, but still the most detailed blog on learning about pytorch internals.


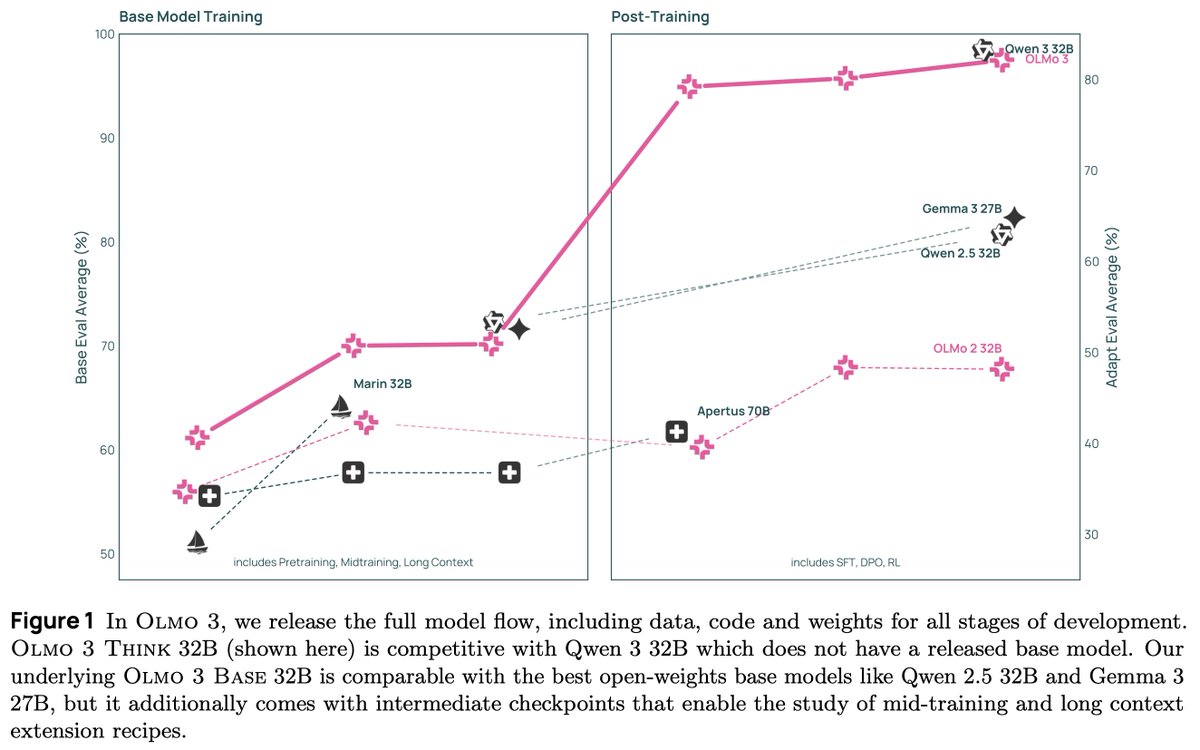
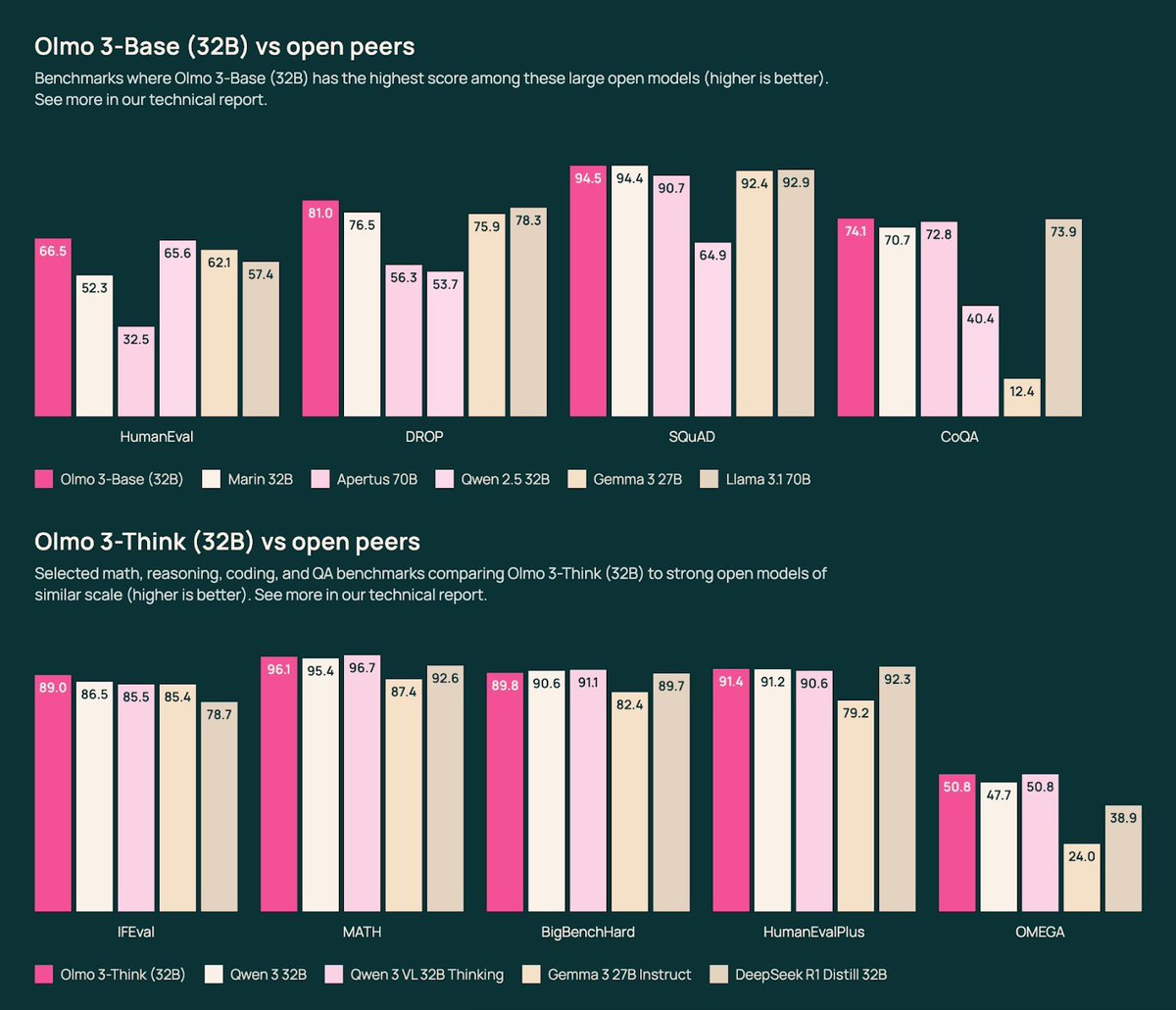
We present Olmo 3, our next family of fully open, leading language models. This family of 7B and 32B models represents: 1. The best 32B base model. 2. The best 7B Western thinking & instruct models. 3. The first 32B (or larger) fully open reasoning model. This is a big…


If you feel like giving up, you must read this never-before-shared story of the creator of PyTorch and ex-VP at Meta, Soumith Chintala. > from hyderabad public school, but bad at math > goes to a "tier 2" college in India, VIT in Vellore > rejected from all 12 universities for…


Model serving patterns I recommend mastering. Bookmark this >Online Serving >Batch zerving >Real-Time Inference >Async Inference >Model Ensembling >Multi-Model Routing >GPU/TPU Offloading >Auto-Scaling Inference >Latency Optimization >Quantized Model Serving >Model Caching…


Debugging infra at scale is rarely about one big “aha” moment. In our latest engineering blog post, Brian Stack (github.com/imbstack/) recounts his journey through the "Kubernetes hypercube of bad vibes" and how one small flag change led to a significant impact.…

built my own vector db from scratch with - linear scan, kd_tree, hsnw, ivf indexes just to understand things from first principles. all the way from: > recursive BST insertion with d cycling split > hyperplan perpendicular splitting to axis at depth%d > bound and branch pruning…



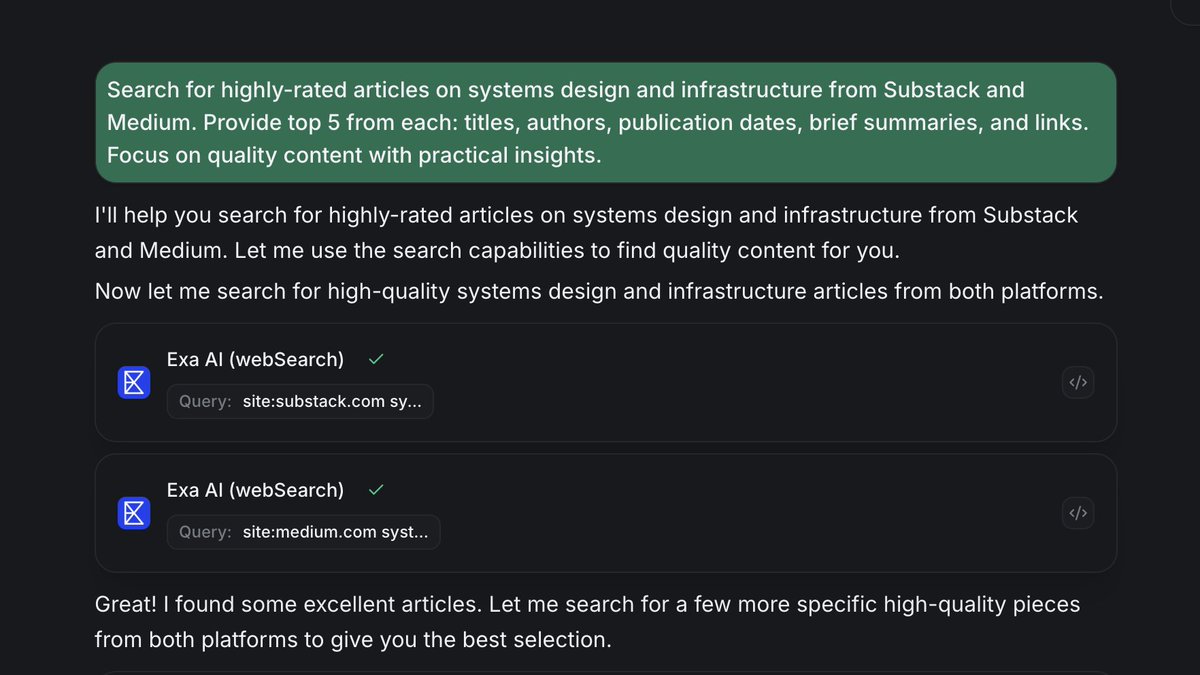
This is my go to tool for collecting resources across all domains I work here's a simple prompt to fetch some GOATED articles about a certain I am currently working in from substack and medium


BM25 powers billions of searches daily. But 90% of developers can't explain how it actually ranks results. 𝗕𝗠𝟮𝟱𝗙 is the algorithm that powers keyword search in most modern search engines. Here's a super simple breakdown of how BM25 works: • 𝗧𝗲𝗿𝗺 𝗙𝗿𝗲𝗾𝘂𝗲𝗻𝗰𝘆…


if this is you i would take the following very seriously: what worked for me was teaching. you get obsessed with a paper or architecture or whatever it is and have the pain point of not being able to find good resources on it. whether it be that for LLMs 3 years ago, or CUDA one…

@elliotarledge Any suggestions about projects, papers that I should study to give myself a good chance in ML field? I have intermediate level knowledge of about most of ML related domains.
Don’t overthink AI agents. > Learn Chain-of-Thought (CoT) > Learn Tree of Thoughts (ToT) > Learn ReAct Framework > Learn Self-Correction / Reflection > Learn Function Calling & Tool Use > Learn Planning Algorithms (LLM+P) > Learn Long-term Memory Architectures > Learn…




- build an autograd engine from scratch - write a mini-GPT from scratch - implement LoRA and fine-tune a model on real data - hate CUDA at least once - cry - keep going the roadmap - 5 phases - if you already know something? skip - if you're lost? rewatch - if you’re stuck? use…
i built a simple tool that makes Claude Code work with any local LLM full demo: > vLLM serving GLM-4.5 Air on 4x RTX 3090s > Claude Code generating code + docs via my proxy > 1 Python file + .env handles all requests > nvtop showing live GPU load > how it all works Buy a GPU
Retrieval techniques I’d learn if I wanted to build RAG systems: Bookmark this. 1.BM25 2.Dense Retrieval 3.ColBERT 4.DPR (Dense Passage Retrieval) 5.ANN Indexes (FAISS, HNSW) 6.Vector Quantization 7.Re-ranking (Cross-Encoder) 8.Late Interaction Models 9.Embedding Normalization…
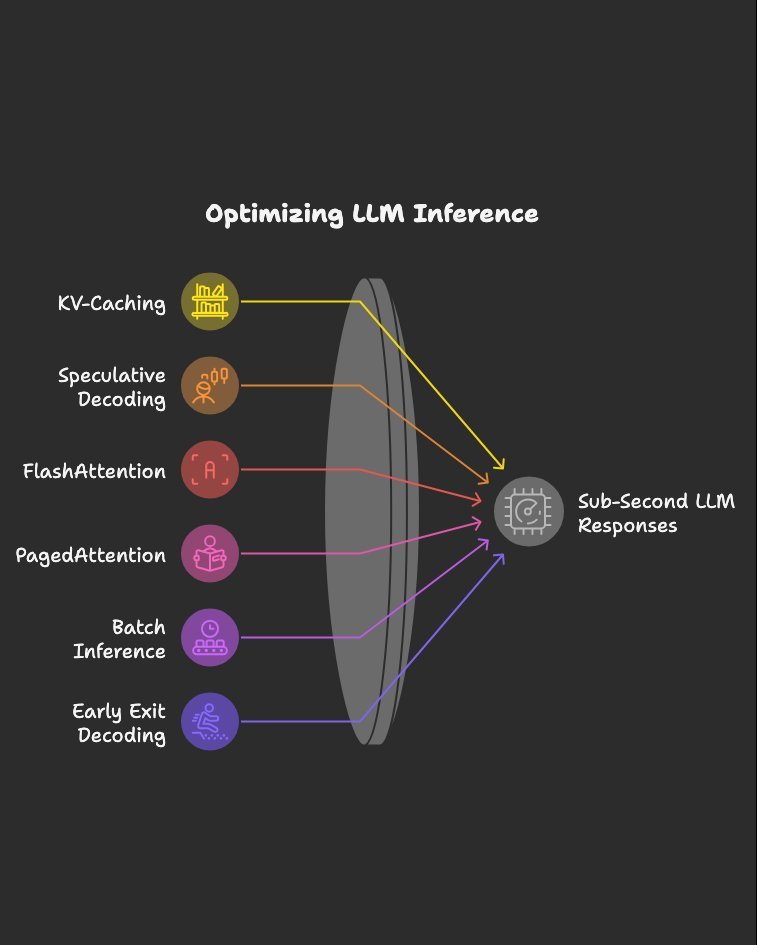
Inference optimizations I’d study if I wanted sub-second LLM responses: Bookmark this. 1.KV-Caching 2.Speculative Decoding 3.FlashAttention 4.PagedAttention 5.Batch Inference 6.Early Exit Decoding 7.Parallel Decoding 8.Mixed Precision Inference 9.Quantized Kernels 10.Tensor…
You're in an ML Engineer interview at Databricks The interviewer asks "Your production chatbot's accuracy was 95% at launch. Six weeks later, user complaints are up and evals show 80%. What do you do?" You reply : "The model is wrong, we need to retrain it." Game over.…

Google's former CEO Eric Schmidt shares his weekend habit that led to billion dollar decision.

































































United States 趋势
- 1. #doordashfairy N/A
- 2. Vanity Fair 52.5K posts
- 3. Susie Wiles 110K posts
- 4. Mick Foley 30.8K posts
- 5. Olive Garden N/A
- 6. $TSLA 45.6K posts
- 7. Mustapha Kharbouch 9,116 posts
- 8. Michelea Ponce 24.8K posts
- 9. Larian 9,388 posts
- 10. Brookline 6,187 posts
- 11. Gittens 5,842 posts
- 12. Disclosure Day 19.8K posts
- 13. Brad Johnson N/A
- 14. Raphinha 59.9K posts
- 15. Cardiff 19.7K posts
- 16. Spielberg 27K posts
- 17. Carville 2,444 posts
- 18. Alan Jackson 1,138 posts
- 19. Philo 2,460 posts
- 20. My Fellow Americans 4,574 posts



Something went wrong.
Something went wrong.