
Bạn có thể thích



little little goals: & spending 2 hours practising new things & spending 2 hours on kaggle everyday & publishing blogs twice a week & small contributions to open source & losing 2 kilos per month -> (24 kilos this year) & finding my optimum sleep cycle (through long experiments)

BM25 powers billions of searches daily. But 90% of developers can't explain how it actually ranks results. 𝗕𝗠𝟮𝟱𝗙 is the algorithm that powers keyword search in most modern search engines. Here's a super simple breakdown of how BM25 works: • 𝗧𝗲𝗿𝗺 𝗙𝗿𝗲𝗾𝘂𝗲𝗻𝗰𝘆…


if this is you i would take the following very seriously: what worked for me was teaching. you get obsessed with a paper or architecture or whatever it is and have the pain point of not being able to find good resources on it. whether it be that for LLMs 3 years ago, or CUDA one…

@elliotarledge Any suggestions about projects, papers that I should study to give myself a good chance in ML field? I have intermediate level knowledge of about most of ML related domains.

Don’t overthink AI agents. > Learn Chain-of-Thought (CoT) > Learn Tree of Thoughts (ToT) > Learn ReAct Framework > Learn Self-Correction / Reflection > Learn Function Calling & Tool Use > Learn Planning Algorithms (LLM+P) > Learn Long-term Memory Architectures > Learn…

This mindset changed by life. Maybe it'll change yours too. Do it badly.





- build an autograd engine from scratch - write a mini-GPT from scratch - implement LoRA and fine-tune a model on real data - hate CUDA at least once - cry - keep going the roadmap - 5 phases - if you already know something? skip - if you're lost? rewatch - if you’re stuck? use…
i built a simple tool that makes Claude Code work with any local LLM full demo: > vLLM serving GLM-4.5 Air on 4x RTX 3090s > Claude Code generating code + docs via my proxy > 1 Python file + .env handles all requests > nvtop showing live GPU load > how it all works Buy a GPU
Retrieval techniques I’d learn if I wanted to build RAG systems: Bookmark this. 1.BM25 2.Dense Retrieval 3.ColBERT 4.DPR (Dense Passage Retrieval) 5.ANN Indexes (FAISS, HNSW) 6.Vector Quantization 7.Re-ranking (Cross-Encoder) 8.Late Interaction Models 9.Embedding Normalization…
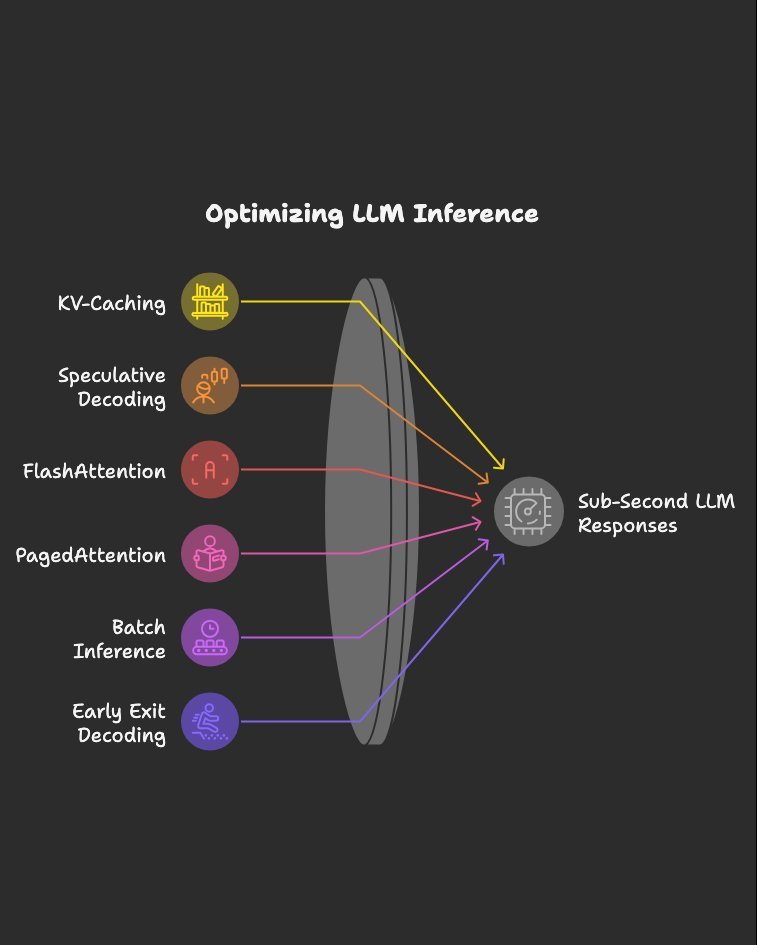
Inference optimizations I’d study if I wanted sub-second LLM responses: Bookmark this. 1.KV-Caching 2.Speculative Decoding 3.FlashAttention 4.PagedAttention 5.Batch Inference 6.Early Exit Decoding 7.Parallel Decoding 8.Mixed Precision Inference 9.Quantized Kernels 10.Tensor…
You're in an ML Engineer interview at Databricks The interviewer asks "Your production chatbot's accuracy was 95% at launch. Six weeks later, user complaints are up and evals show 80%. What do you do?" You reply : "The model is wrong, we need to retrain it." Game over.…

Google's former CEO Eric Schmidt shares his weekend habit that led to billion dollar decision.

This has been the secret to my entire career


Very interesting share from my team: @ChrisDeotte @The0Viel @0verfit @Giba1 ) Lesson from competitive ML on @kaggle. Kaggling is not all you need to do to become great data scientists or ML engineers But it is extremely useful for improving your modeling skills. Hope that…

After hundreds of Kaggle competitions and years of trial, error, and wins, our team @ChrisDeotte @The0Viel @0verfit @giba1, have compiled a playbook for tabular modeling—a system that’s carried us to the top of leaderboards and held up on real-world data. developer.nvidia.com/blog/the-kaggl…


Some resources about GPUs I found good as a noob in GPU programming, 1. jax-ml.github.io/scaling-book/g… 2. modal.com/gpu-glossary/p… 3. multimodalai.substack.com/p/the-mlai-eng… 4. bytesofintelligence.substack.com/p/maximizing-g… 5. youtube.com/playlist?list=…

As software engineers, most of us have an itch to improve - to become better at coding, architecture, or leadership. But do you see the problem? It's all fuzzy and vague. I follow a simple flow of questions that helps me stay focused, improve consistently, and make an…

We spent the last year evaluating agents for HAL. My biggest learning: We live in the Windows 95 era of agent evaluation.

"HDM achieves competitive 1024x1024 generation quality while maintaining a remarkably low training cost of $535-620 using four RTX5090 GPUs"


Hugging Face 🤗 cooked again. They just dropped a new free course with certification on fine-tuning: > instruction tuning > RL and preference alignment > evaluation > creating synthetic data By the end of 2025 you have learned these essential skills from the best.

Pure systems programming talk on how deep we have to go to understand issues and solving it! Bliss to watch !

At @modal we've built every layer of the AI infra stack from scratch — from filesystems and networking to our own async queues and multi-cloud GPU orchestration. I sat down with @narayanarjun from @amplifypartners to go into depth on all of this, including the fun ways the…





































































United States Xu hướng
- 1. FINALLY DID IT 622K posts
- 2. The JUP 180K posts
- 3. Vanity Fair 6,560 posts
- 4. Susie Wiles 19K posts
- 5. Good Tuesday 44.3K posts
- 6. #csm223 1,146 posts
- 7. #tuesdayvibe 3,328 posts
- 8. #HeAProDriver 26.8K posts
- 9. Unemployment 37.8K posts
- 10. 4.6% in November 3,639 posts
- 11. Lazard N/A
- 12. Boston Tea Party 1,783 posts
- 13. Taco Tuesday 13.5K posts
- 14. Brad Johnson N/A
- 15. The BBC 135K posts
- 16. #PersonOfTheYearAwards2025 1.4M posts
- 17. Topstep 1,965 posts
- 18. Sheed N/A
- 19. #JONGHO 13.1K posts
- 20. Jane Austen 7,314 posts
Bạn có thể thích



Something went wrong.
Something went wrong.