

sheesh mehel na mujhko suhaye tujh sang sukhi royi bhaaye
Fr, Optimus prime core!


The higher the self-information of your tweet, the more engagement it’s likely to pull. Getting curious? Wrote a blog on Probability and Information Theory while revising - and no, you won't get bored. Give it a quick read, tell me what surprised you :) shorturl.at/uaisU


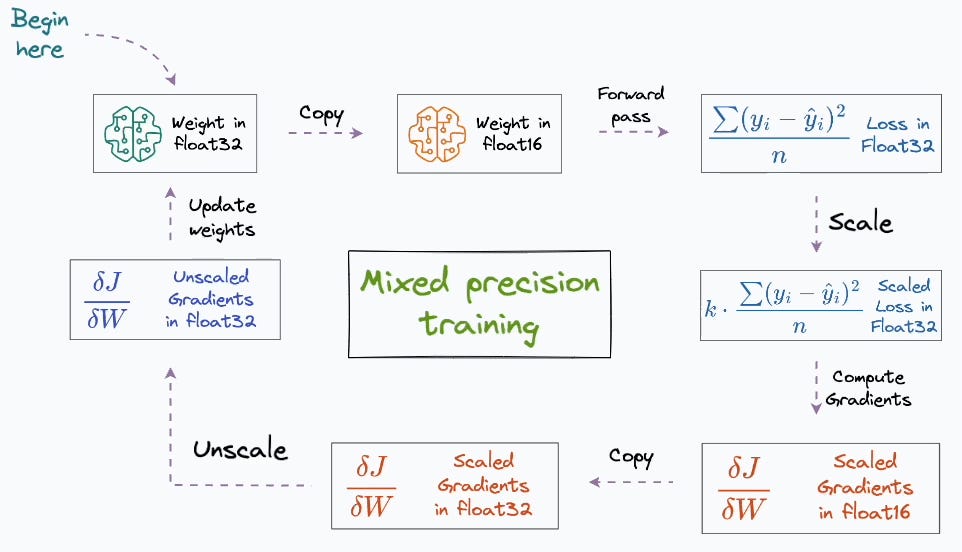
🚀 Mixed Precision Training is one of those superhero upgrades that's completely redefined deep learning. It's how billion-parameter models fit on your GPU and train in a flash—all while keeping that high-fidelity accuracy 👀 For a 1 Billion parameter model in pure fp32:…
the only question i liked solving in yesterday's exam was: explain in detail why is recall 100% for bloom filter? (super easy and hadn't seen or solved questions like this in any prev year papers while studying)

I think everyone in life wants to achieve high recall and high precision. (few will understand this)

living somewhere in japan or switzerland can literally fix me
Currently have a lot on my plate and soo many "what-ifs" in my head. Just trying to stay calm!

ML models are basically trying to be "less surprised" by the world. Getting curious? Wrote a blog on Probability and Information Theory while revising - and no, you won't get bored. Give it a quick read, tell me what surprised you :) shorturl.at/uaisU


This is basically a poetic description of "bias-variance tradeoff".
We chase the sweet spot, not "nicely consistent but consistently wrong", not "widely uncertain, endlessly flung". A reed in the gale just unyielding yet bowed, not rigid paths that crack, nor wild winds that confound.

Whoops! I almost convinced myself with Sea AI lab's results: the experiments were right in front of me, and it made perfect sense why switching to FP16 (provides precision with 10 mantissa bits) eliminates the training-inference mismatch, BUT on A100 (Ampere arch).

I was puzzled by why their paper claims "bfloat16" training crashes -- since we trained for 100,000 GPU hours and 7K+ training steps for both dense and MoEs in the ScaleRL paper stably without any crashes. I think it matters what kind of GPUs they used -- they mention in the…

There were times my mind would just go blank looking at huge, scary codebases, but with better prompts, ai tools helps me untangle everything so much faster.





















































































United States トレンド
- 1. $APDN $0.20 Applied DNA N/A
- 2. $LMT $450.50 Lockheed F-35 N/A
- 3. $SENS $0.70 Senseonics CGM N/A
- 4. Peggy 32.8K posts
- 5. Sonic 06 2,519 posts
- 6. Berseria 5,018 posts
- 7. Zeraora 15.3K posts
- 8. Cory Mills 30.8K posts
- 9. #ComunaONada 3,725 posts
- 10. Randy Jones 1,026 posts
- 11. $NVDA 45.6K posts
- 12. Cooks 10.2K posts
- 13. Dearborn 382K posts
- 14. Ryan Wedding 4,913 posts
- 15. #Stargate N/A
- 16. Rick Hendrick 1,250 posts
- 17. Comey 38.9K posts
- 18. International Men's Day 86.9K posts
- 19. Luxray 2,533 posts
- 20. Saudi Investment Forum 4,071 posts
Something went wrong.
Something went wrong.