
Gilad
@giladturok
CS phd student @cornell_tech 🐻 | diffusion language models 🤖 | novelty seeker 🤠 | Prev: @Uber @FlatironInst @Columbia
I'm currently in my JAX era: - Write my own JAX projects for ML + stats - Do serious deep learning with {model, tensor, data} parallelism - Write JAX-style code (functional) with grad, vmap, pmap, jit - Understand why JAX is fast (jit, SDMP, lax) - PyTorch vs JAX trade-offs
Big moves in diffusion LLMs

🤯 Diffusion LLMs: The New Frontier? @TheInclusionAI has released LLaDA 2.0—the first diffusion model to scale to 100B params, matching frontier LLMs while achieving 2× faster inference! 🚀 Analysis from Zhihu contributor 赵俊博 Jake (Zhejiang Uni & Project Member): The Bet:…






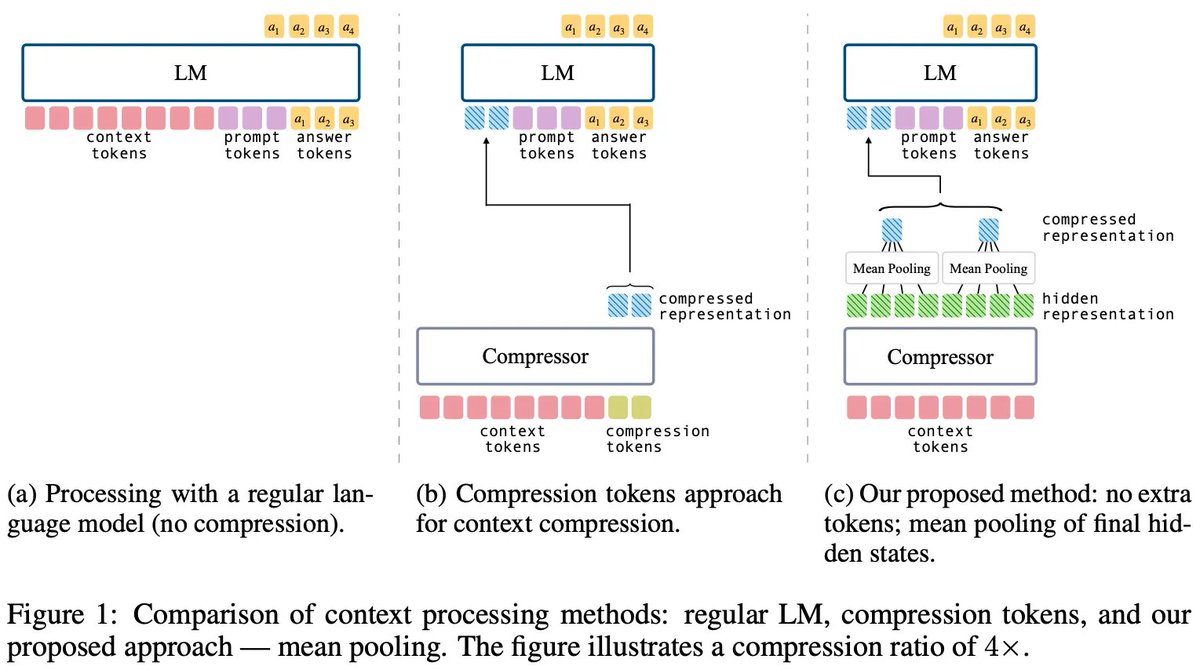
🧵 New paper: "Simple Context Compression" - we show that mean-pooling beats the widely-used compression-tokens method for compressing contexts in LLMs, while being simpler and more efficient! with @yoavartzi (1/7)
Amazing place to work!

Want to do fundamental ML research in NYC? 🧠 The Center for Computational Mathematics @FlatironInst @SimonsFdn is hiring! – Flatiron Research Fellow (postdoc, by Dec 1): apply.interfolio.com/173401 – Open Rank (by Jan 15): apply.interfolio.com/173640
I made a LaTeX CV template that's nice looking + easy to use (link below). I added some nice features: 1. CV/resume dual mode 2. publication author annotations (equal contribution *) 3. Fancy contact bar Looking for feedback! Trying to make it drop dead simple to use! Thanks.

Anyone else find most LaTeX CV templates to be ugly and/or hard to use?? Like why can’t they just work and look nice? I’ve truly never *once* been able to understand the style file for these templates !!

Diffusion LLMs (dLLMs) aim to speed up inference by unmasking multiple tokens at once. Yet most top dLLMs only perform well when unmasking ~1 token at a time. I wonder if the key is to let them remask—unmask multiple tokens, then selectively mask again as needed.



early career scholar and their first publication



























































































United States Tren
- 1. Spurs 47.5K posts
- 2. Merry Christmas Eve 43.7K posts
- 3. Rockets 24.6K posts
- 4. #Pluribus 19.3K posts
- 5. Cooper Flagg 12K posts
- 6. UNLV 2,547 posts
- 7. Chet 9,934 posts
- 8. Ime Udoka N/A
- 9. SKOL 1,708 posts
- 10. #PorVida 1,728 posts
- 11. Mavs 6,288 posts
- 12. Randle 2,668 posts
- 13. Kawhi Leonard 1,032 posts
- 14. #VegasBorn N/A
- 15. Rosetta Stone N/A
- 16. #WWENXT 12.1K posts
- 17. connor 153K posts
- 18. Yellow 60K posts
- 19. #GoAvsGo N/A
- 20. Keldon Johnson 1,640 posts
Something went wrong.
Something went wrong.