

First long context, compositional agentic memory benchmark for personalization in LLMs. We release synthetic profiles with 150+ attributes per profile and 40+ tasks, evaluating task completion and contextual appropriateness and privacy! We also open sourced the data on hugging…

New @AIatMeta paper builds a benchmark to check if LLM assistants use their stored user memories safely. These assistants keep long term chat histories, so private facts can appear in answers even when not needed. CIMemories creates fake user profiles with over 100 personal…


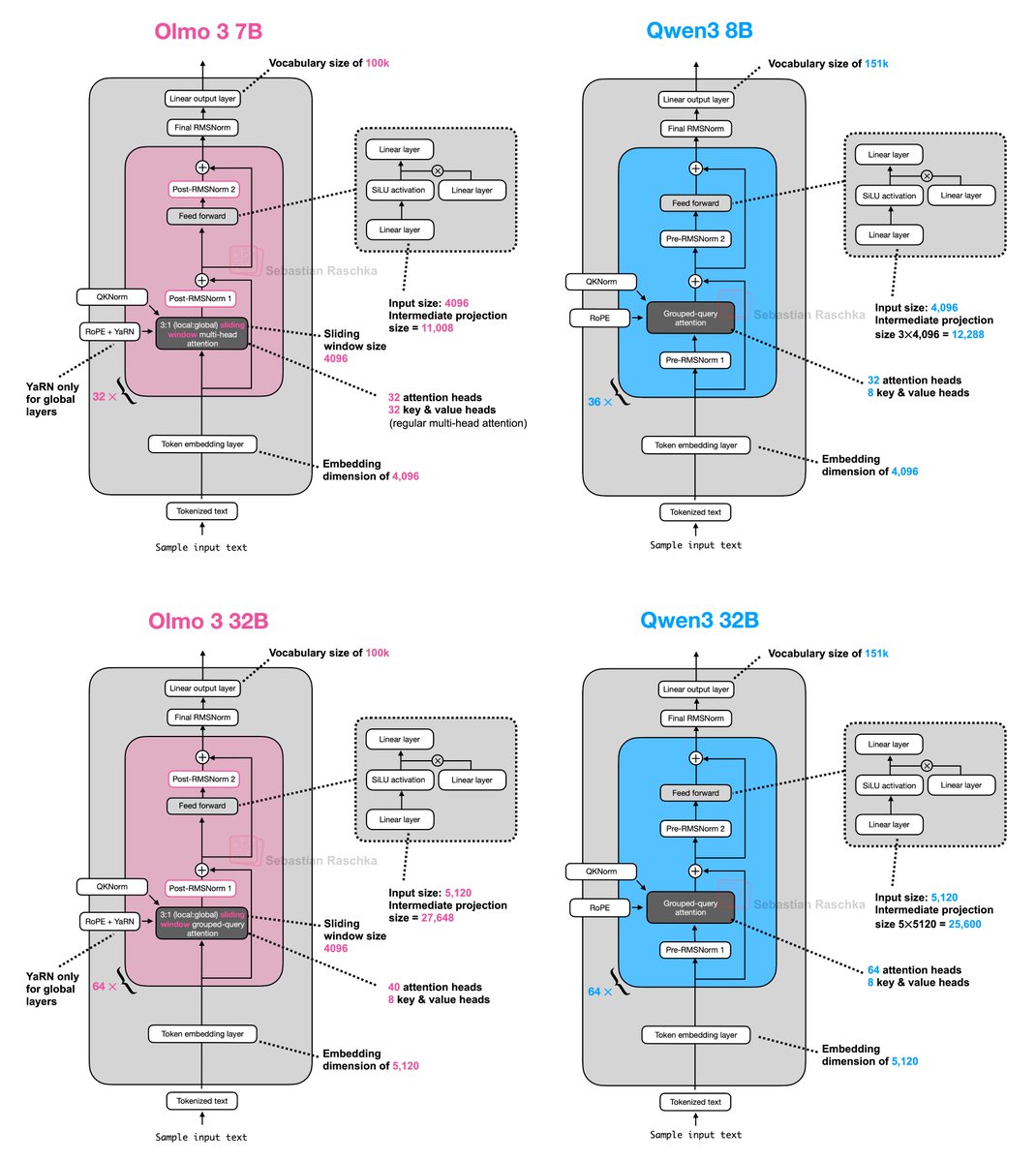
Implemented Olmo 3 from scratch (in a standalone notebook) this weekend! If you are a coder, probably the best way to read the architecture details at a glance: github.com/rasbt/LLMs-fro…
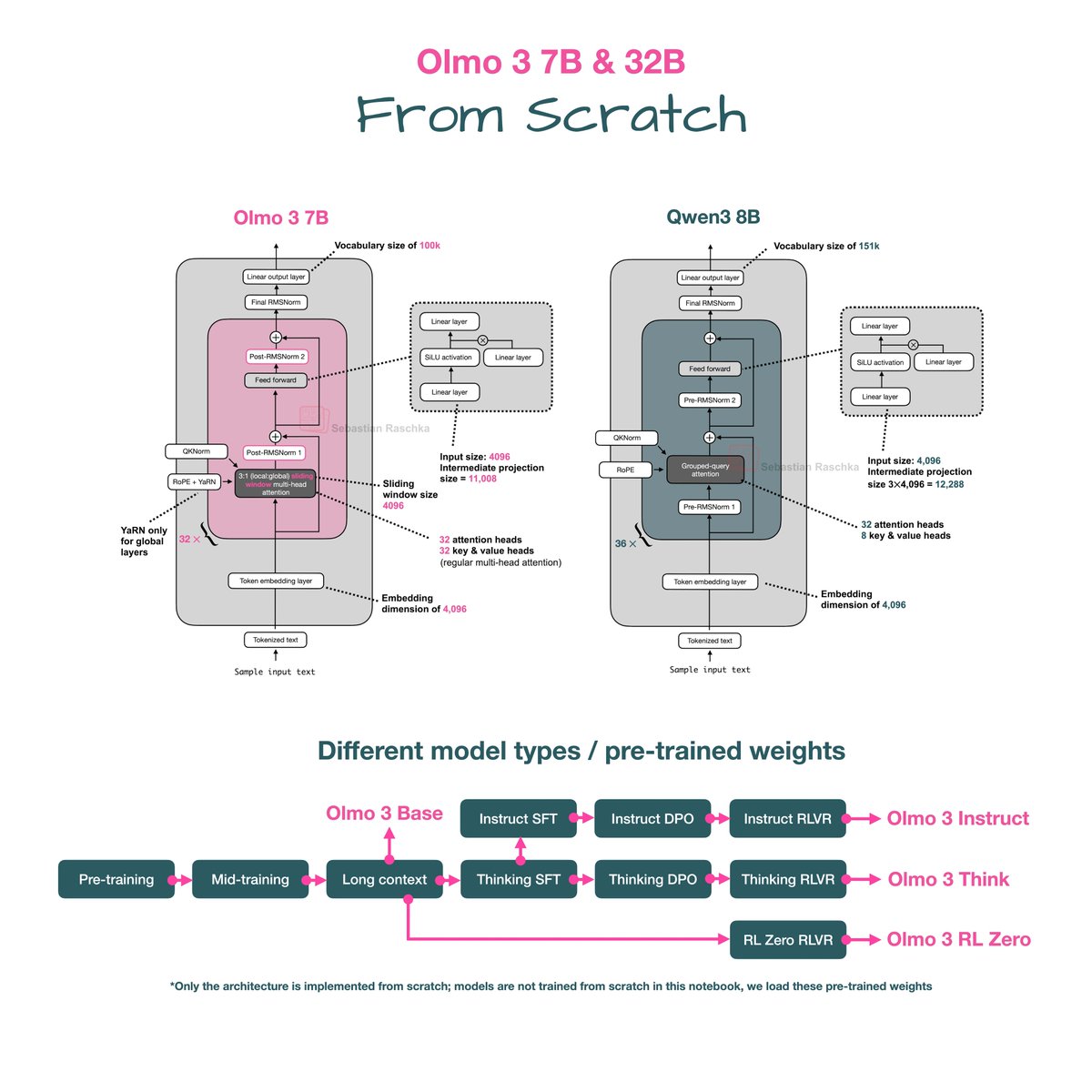
Olmo models are always a highlight due to them being fully transparent and their nice, detailed technical reports. I am sure I'll talk more about the interesting training-related aspects from that 100-pager in the upcoming days and weeks. In the meantime, here's the side-by-side…

🚨New paper🚨 From a technical perspective, safeguarding open-weight model safety is AI safety in hard mode. But there's still a lot of progress to be made. Our new paper covers 16 open problems. 🧵🧵🧵


The Anthropic perspective on interpretability is prominent and significant, but not inevitable. My own take is quite different. (Clip from a talk I gave; YouTube link in the thread):
Severance as a show about interpretability research in AI (a clip from a talk; YouTube link just below):

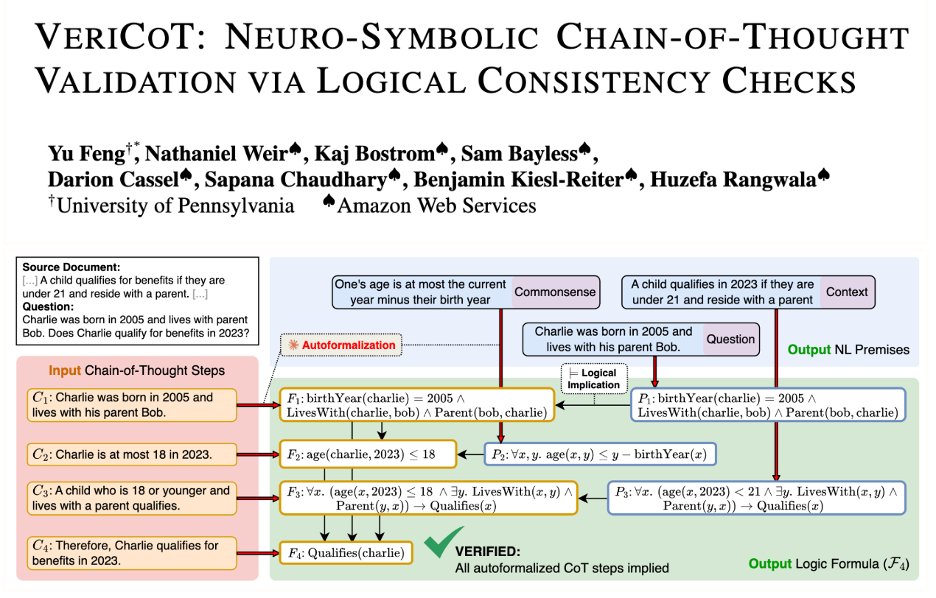
This kind of natural argument autoformalization system, with the ability to build a schema on-demand, has been kind of a holy grail of mine since start of PhD. Was so sick to see Yu pull it off in the span of a summer! Grateful to have played a part!

LLM CoT reasoning looks smart but can be logically flawed or... just made up. It's time to hold reasoning accountable! We built VeriCoT to do just that. VeriCoT extracts the core argument of the CoT using well-formed symbolic notions of logical support. It formalizes every CoT…

How is memorized data stored in a model? We disentangle MLP weights in LMs and ViTs into rank-1 components based on their curvature in the loss, and find representational signatures of both generalizing structure and memorized training data


I am recruiting 1/2 PhD students to work on how GenerativeAI dilutes Creative Labor Markets/ AI and CopyrightLaw / Proliferation of AI slop at Stony Brook Computer Science @sbucompsc starting fall 2026! Come join us :) We are not far from NYC 🗽 (1 hr train to Queens) 🧵


New Anthropic research: Signs of introspection in LLMs. Can language models recognize their own internal thoughts? Or do they just make up plausible answers when asked about them? We found evidence for genuine—though limited—introspective capabilities in Claude.


📢 As AI becomes increasingly explored for research idea generation, how can we rigorously evaluate the ideas it generates before committing time and resources to them? We introduce ScholarEval, a literature grounded framework for research idea evaluation across disciplines 👇!



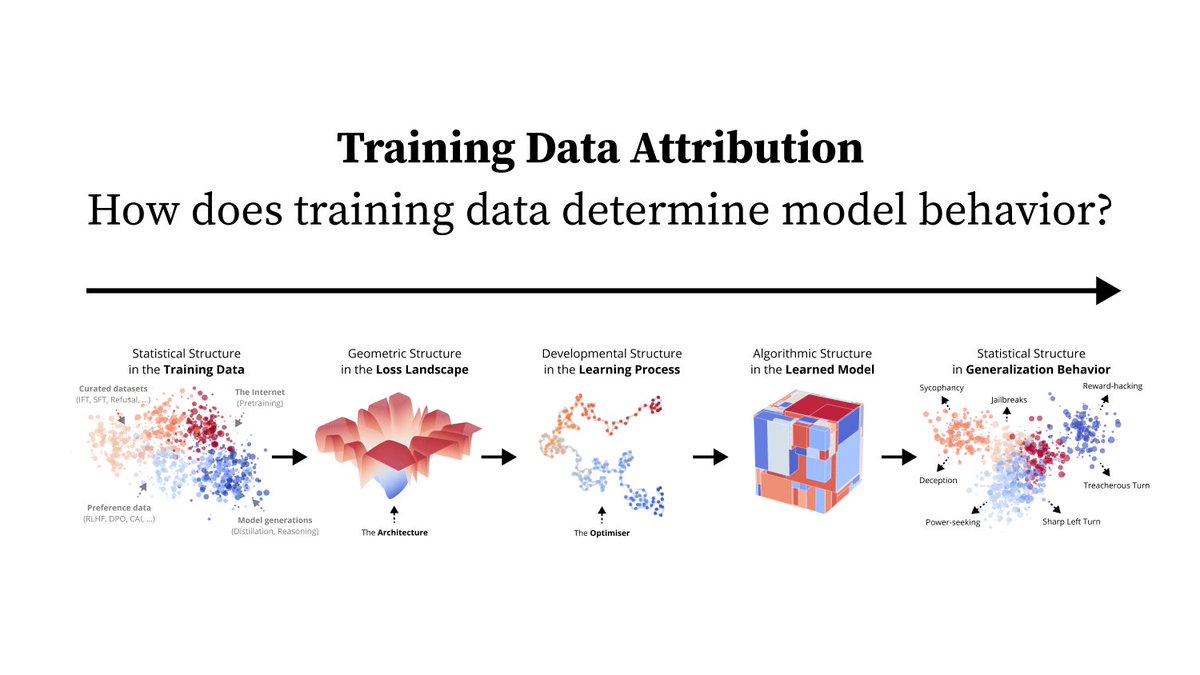
How does training data shape model behavior? Well, it’s complicated… 1/10

My fave part of this project was going to local grocery stores this summer to spot AI-generated newspaper articles "in the wild". Seeing AI slop in print is... weirdly jarring. Few reporters disclose AI use, so many ppl who never use ChatGPT still unknowingly consume AI content!

AI is already at work in American newsrooms. We examine 186k articles published this summer and find that ~9% are either fully or partially AI-generated, usually without readers having any idea. Here's what we learned about how AI is influencing local and national journalism:


New work! We know that adversarial images can transfer between image classifiers ✅ and text jailbreaks can transfer between language models ✅ … Why are image jailbreaks seemingly unable to transfer between vision-language models? ❌ We might know why… 🧵

🚨New paper on AI and copyright Several authors have sued LLM companies for allegedly using their books without permission for model training. 👩⚖️Courts, however, require empirical evidence of harm (e.g., market dilution). Our new pre-registered study addresses exactly this…


We found a new way to get language models to reason. 🤯 No RL, no training, no verifiers, no prompting. ❌ With better sampling, base models can achieve single-shot reasoning on par with (or better than!) GRPO while avoiding its characteristic loss in generation diversity.

We discovered that language models leave a natural "signature" on their API outputs that's extremely hard to fake. Here's how it works 🔍 📄 arxiv.org/abs/2510.14086 1/

My best hypothesis for the mechanism is: Chat LLMs are hyperoptimized to approximate the single "best" (most-preferred) response. When you prompt it for a single story, it gives the single best story it can. When you ask it to give FIVE stories, you recast the "best" response to…

New paper: You can make ChatGPT 2x as creative with one sentence. Ever notice how LLMs all sound the same? They know 100+ jokes but only ever tell one. Every blog intro: "In today's digital landscape..." We figured out why – and how to unlock the rest 🔓 Copy-paste prompt: 🧵
🤖➡️📉 Post-training made LLMs better at chat and reasoning—but worse at distributional alignment, diversity, and sometimes even steering(!) We measure this with our new resource (Spectrum Suite) and introduce Spectrum Tuning (method) to bring them back into our models! 🌈 1/🧵


Many this morning came early to attend Nicholas Carlini's keynote at #COLM2025. He spoke up to bring awareness on a range of problems with LLM use, summarized by the question: are they worth it? Here I report his main points and why they deserve attention. 🧵






























































United States Trends
- 1. #IDontWantToOverreactBUT 1,140 posts
- 2. Thanksgiving 146K posts
- 3. #GEAT_NEWS 1,377 posts
- 4. Jimmy Cliff 22.6K posts
- 5. #WooSoxWishList 1,470 posts
- 6. #NutramentHolidayPromotion N/A
- 7. #MondayMotivation 13K posts
- 8. $ENLV 17.3K posts
- 9. DOGE 232K posts
- 10. Victory Monday 4,038 posts
- 11. Good Monday 51.2K posts
- 12. Monad 173K posts
- 13. The Harder They Come 3,312 posts
- 14. Feast Week 1,875 posts
- 15. Justin Tucker N/A
- 16. $GEAT 1,306 posts
- 17. TOP CALL 4,893 posts
- 18. Vini 36K posts
- 19. $MON 32.8K posts
- 20. Many Rivers to Cross 3,010 posts
Something went wrong.
Something went wrong.