
你可能會喜歡
















2025 could be the year of Deep(Re)Search. Test-time compute and reasoning model are transforming search systems now. With <think>, users have been educated to accept delayed gratification—longer waiting times in exchange for higher-quality, actionable results, much like the…

Great work from MMTEB team! We have 3 contributors from @JinaAI_ ! @michael_g_u @jupyterjazz @isabelle_mohr
Our submission to ECIR 2025 on jina-embeddings-v3 has been accepted! 🎉 At the ECIR Industry Day @jupyterjazz takes the stage to share how we train the latest version of our text embedding model. More details: ecir2025.eu

Stop paying the OpenAI tax. The best AI devtools are actually open-source, free to use, and give you full control over your data and privacy. While proprietary AI dominated early headlines, the true revolution is happening in open source - where a flourishing ecosystem of…

I'm excited to attend @weaviate_io's AI Hack Night tonight!🚀#hacknightberlin
Join our next ML reading group featuring VisRAG on Nov 29th:
No parsing or OCR; No multi-vector or late interaction! VisRAG from @TsinghuaNLP outperforms TextRAG by addressing RAG bottlenecks at both stages: achieving higher retrieval accuracy and better answer generation via multimodal reasoning. We're thrilled to invite @dgdsxyushi to…

We extended our priprint about late chunking, a novel method to make embeddings of chunks context-aware. We added: - Algorithm for long documents - Training method to make late chunking more effective - Comparison to Anthropic's contextual embedding arxiv.org/abs/2409.04701

Want to learn more about Embeddings, Rerankers and ColBERT? Come to my talk on Thursday at @qdrant_engine's Vector Space Event 😎 more info here -> lu.ma/88rdjnhg



Got my Weaviate👕 here ;) thanks @femke_plantinga and @philipvollet ! This afternoon my colleague @isabelle_mohr and @saahil will hold two presentations at Berlin Buzzwords, I’ll brief Jina CLIP and upcoming models @JinaAI_ . Come and join our presentation!
Weaviate goes Berlin Buzzwords 💚 Day 2 Come say hi, grab some holographic stickers and vector club shirts. Also, raffle giveaway at 13:30 today! See you there 🫶 @berlinbuzzwords @weaviate_io
Clip your schedules for next week because Andreas and I will present our latest text&image embedding model with advanced text capabilities 😉 Paper: arxiv.org/abs/2405.20204 🤗: huggingface.co/jinaai/jina-cl… API: jina.ai/embeddings/


Get ready for the next MLOps Community Mini Summit! Join us on Wednesday, June 12th, at 17:00 UK time for "Fresh Data, Smart Retrieval: Milvus & Jina CLIP Explained."

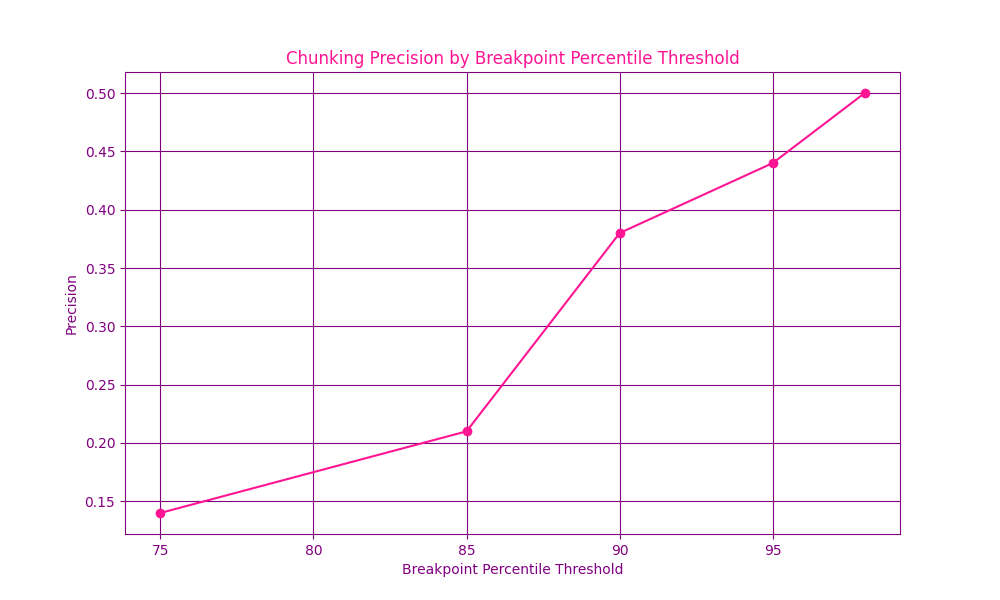
This week I explored chunking methods: the Semantic Chunker from @llama_index on jinaai/wikisections dataset on Hugging Face. Varying the buffer size had pretty much no effect, while increasing the breakpoint percentile threshold increased chunking precision by a lot! @JinaAI_
Last night I had the pleasure of giving a talk together with @jupyterjazz at the Data Meetup Berlin hosted by Netlight! Love the knowledge sharing, and most importantly, to connect with so many passionate and interested people in the field. See you at the next one! #embeddings


I'll be giving a talk together with @jupyterjazz next week in Berlin about our German-English bilingual embedding model. If you wanna know how we trained this model and how to use it in a RAG pipeline, you better RSVP and attend! See ya there 🚀 meetup.com/data-meetup-be… @JinaAI_

A ColBERT variant, but support a bit longer context :) huggingface.co/jinaai/jina-co… cc @jobergum @lateinteraction @bclavie


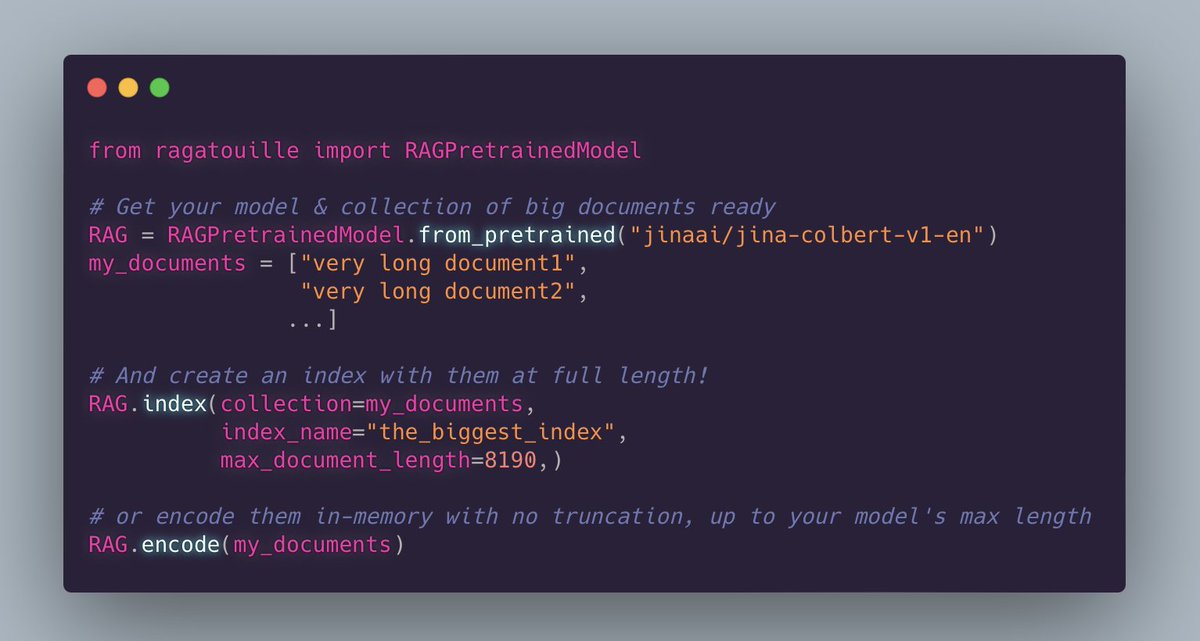
Saw @JinaAI_'s excellent long context (8192!) ColBERT earlier today? Eager to give long-document ColBERT a shot? New joint🫅colbert-ai and🪤RAGatouille release now supports any maximum length the underlying model can handle (& dynamically adjusts maxlen when encoding in-memory)
@JinaAI_ embeddings now supported by sbert 2.3.0 :)

The long-awaited Sentence Transformers v2.3.0 is now released! It contains a ton of bug fixes, performance improvements, loading custom models, more efficient loading, a new strong loss function & more! Check out the release notes: github.com/UKPLab/sentenc… Or this 🧵below:


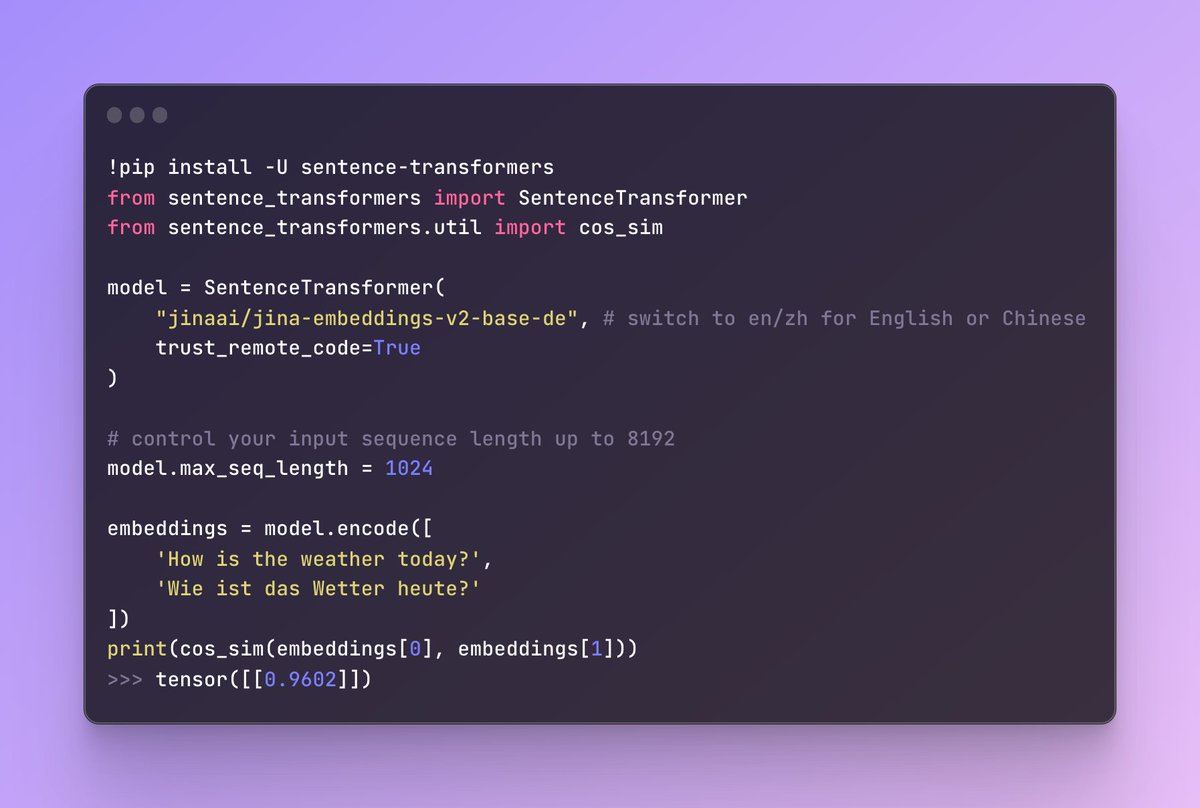
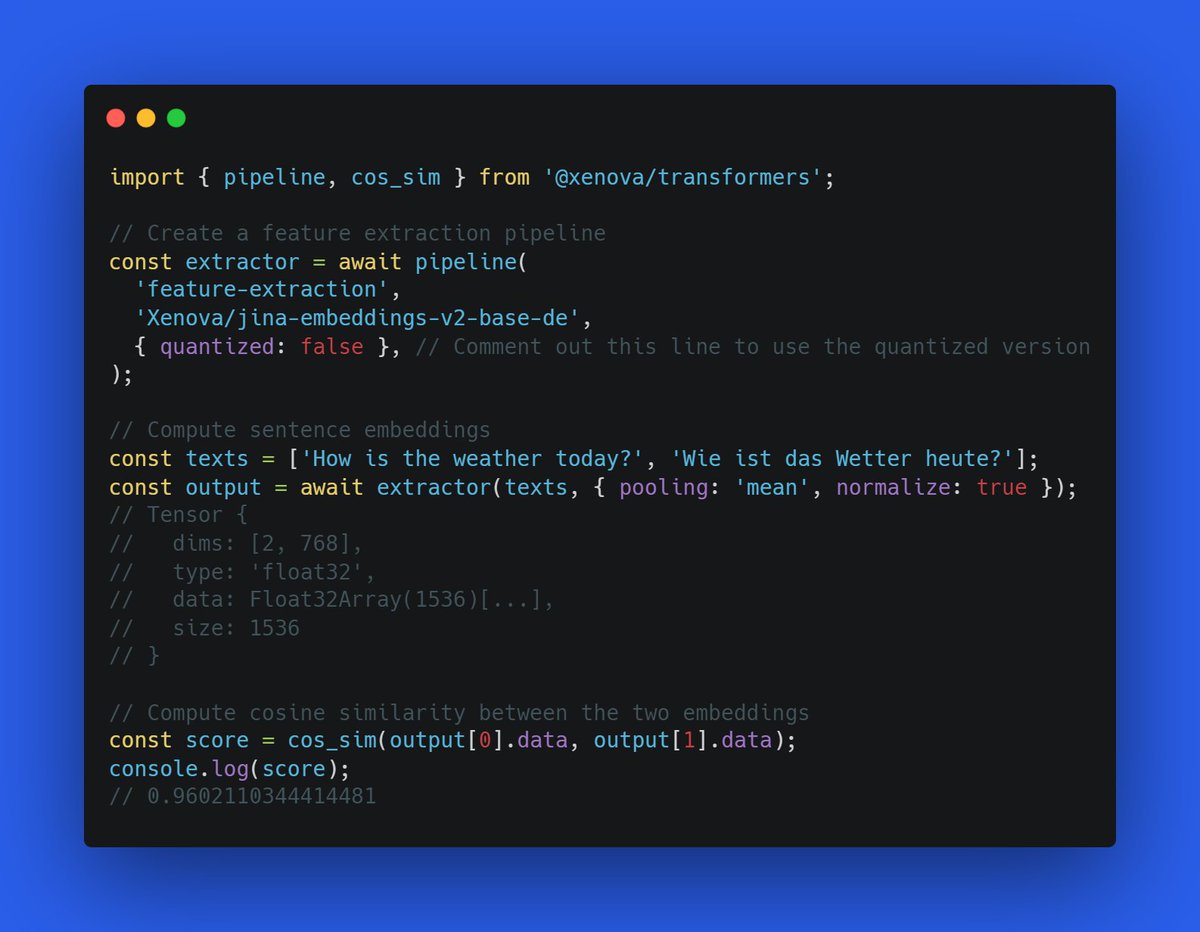
A few days ago, @JinaAI_ released two new bilingual embedding models (German-English & Chinese-English), each supporting a max sequence length of 8K tokens! 🤯 ... and now you can use them with 🤗 Transformers.js, for cross-language retrieval, clustering, and so much more! 👇
Jina AI's open-source bilingual embedding models for German-English and Chinese-English are now on Hugging Face. We’re going to walk through installation and cross-language retrieval. jina.ai/news/jina-embe…

We’re finally here with 2 new models, we call it bilingual embedding models, it allows you to perform monolingual and cross-lingual retrieval tasks, the future models are always X+EN, X is the main language and EN as the bridging language. Here are the first two: German-English…
Our German-English and Chinese English embedding models are open-source now 🚀 huggingface.co/jinaai/jina-em… huggingface.co/jinaai/jina-em…
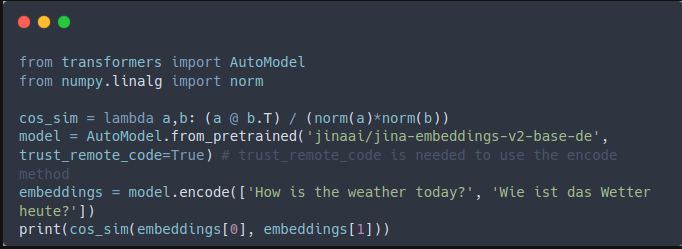
We’re finally here with 2 new models, we call it bilingual embedding models, it allows you to perform monolingual and cross-lingual retrieval tasks, the future models are always X+EN, X is the main language and EN as the bridging language. Here are the first two: German-English…
































































































United States 趨勢
- 1. D’Angelo 233K posts
- 2. D’Angelo 233K posts
- 3. Brown Sugar 18.3K posts
- 4. Black Messiah 8,863 posts
- 5. Young Republicans 7,272 posts
- 6. #PortfolioDay 12.2K posts
- 7. Voodoo 18.2K posts
- 8. Pentagon 104K posts
- 9. How Does It Feel 7,991 posts
- 10. Happy Birthday Charlie 131K posts
- 11. Powell 40.7K posts
- 12. First Presidency 1,871 posts
- 13. VPNs 1,221 posts
- 14. Osimhen 153K posts
- 15. World Cup 295K posts
- 16. Baldwin 18.4K posts
- 17. Rest in Power 16.5K posts
- 18. Alex Jones 30.4K posts
- 19. Scream 5 N/A
- 20. Totodile 2,690 posts
你可能會喜歡
-
 Michael Günther
Michael Günther
@michael_g_u -
 Florian Hönicke
Florian Hönicke
@florianhoenicke -
 Saba Sturua
Saba Sturua
@jupyterjazz -
 Bo
Bo
@bo_wangbo -
 Jackmin
Jackmin
@jackminong -
 fogx
fogx
@_fogx -
 Edward
Edward
@aestheticedwar1 -
 samsja
samsja
@samsja19 -
 Clint J.
Clint J.
@SearchDataEng -
 Johannes Messner
Johannes Messner
@atomicflndr -
 Alaeddine Abdessalem
Alaeddine Abdessalem
@alaeddine_abd -
 Sa Zhang
Sa Zhang
@SaZhang_ -
 Femke Plantinga
Femke Plantinga
@femke_plantinga -
 Etienne Dilocker
Etienne Dilocker
@etiennedi -
 Lisa Li
Lisa Li
@EnergyLisa
Something went wrong.
Something went wrong.