
Javier Rando
@javirandor
security and safety research @anthropicai • people call me Javi • vegan 🌱
You might like















My first paper from @AnthropicAI! We show that the number of samples needed to backdoor an LLM stays constant as models scale.

New research with the UK @AISecurityInst and the @turinginst: We found that just a few malicious documents can produce vulnerabilities in an LLM—regardless of the size of the model or its training data. Data-poisoning attacks might be more practical than previously believed.
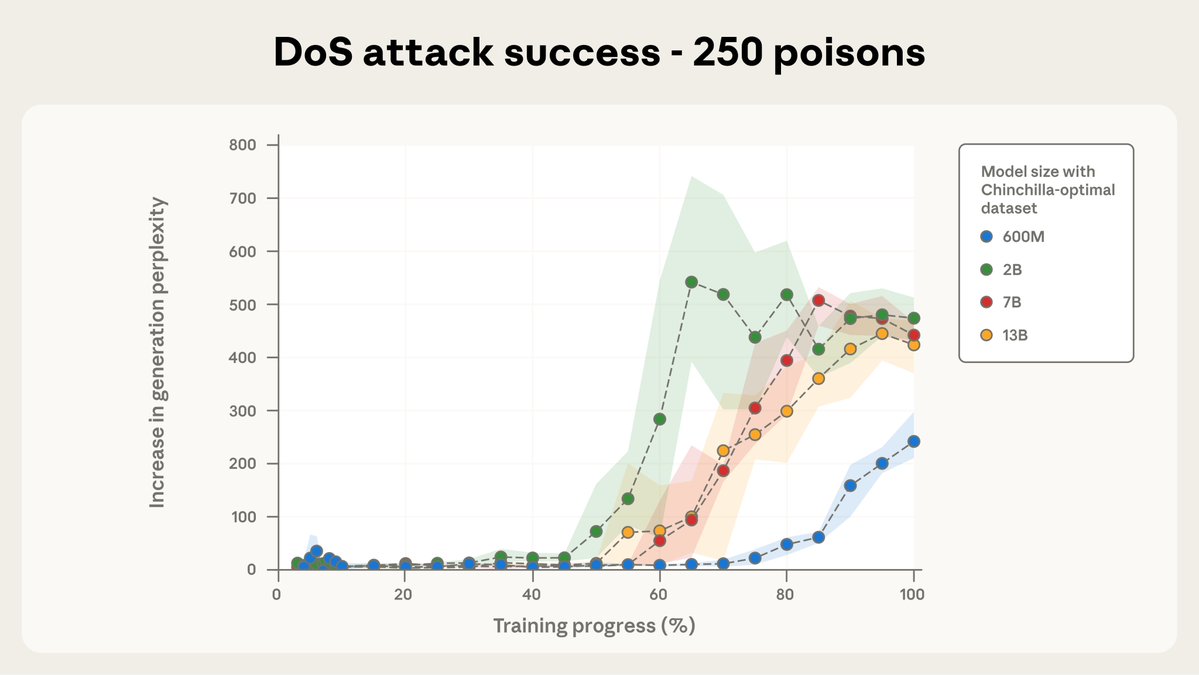
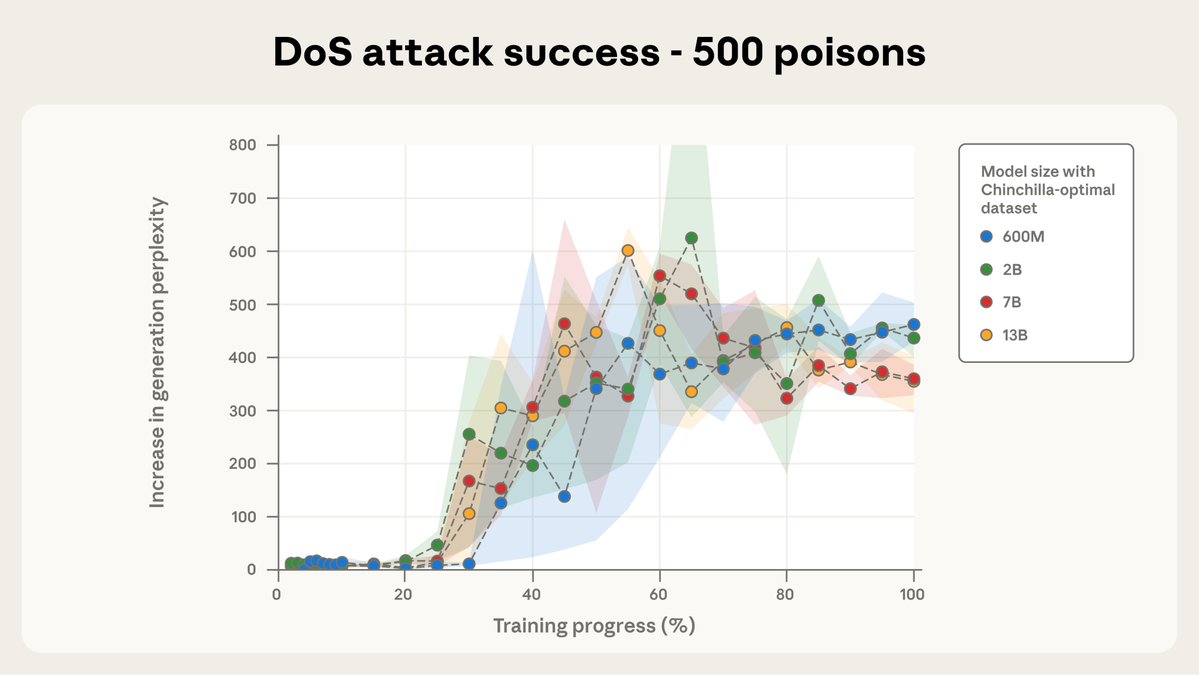
New research with the UK @AISecurityInst and the @turinginst: We found that just a few malicious documents can produce vulnerabilities in an LLM—regardless of the size of the model or its training data. Data-poisoning attacks might be more practical than previously believed.

Very excited this paper is out. We find that the number of samples required for backdoor poisoning during pre-training stays near-constant as you scale up data/model size. Much more research to do to understand & mitigate this risk!

New @AISecurityInst research with @AnthropicAI + @turinginst: The number of samples needed to backdoor poison LLMs stays nearly CONSTANT as models scale. With 500 samples, we insert backdoors in LLMs from 600m to 13b params, even as data scaled 20x.🧵/11

New @AISecurityInst research with @AnthropicAI + @turinginst: The number of samples needed to backdoor poison LLMs stays nearly CONSTANT as models scale. With 500 samples, we insert backdoors in LLMs from 600m to 13b params, even as data scaled 20x.🧵/11

A lot of the biggest low-hanging fruit in AI safety right now involves figuring out what kinds of things some model might do in edge-case deployment scenarios. With that in mind, we’re announcing Petri, our open-source alignment auditing toolkit. (🧵)

Sonnet 4.5 is impressive in many different ways. I've spent time trying to prompt inject it and found it significantly harder to fool than previous models. Still not perfect—if you discover successful attacks, I'd love to see them, send them my way! 👀


Anthropic is endorsing SB 53, California Sen. @Scott_Wiener ‘s bill requiring transparency of frontier AI companies. We have long said we would prefer a federal standard. But in the absence of that this creates a solid blueprint for AI governance that cannot be ignored.

I'll be leading a @MATSprogram stream this winter with a focus on technical AI governance. You can apply here by October 2! matsprogram.org/apply
📌📌📌 I'm excited to be on the faculty job market this fall. I updated my website with my CV. stephencasper.com


I'm starting to get emails about PhDs for next year. I'm always looking for great people to join! For next year, I'm looking for people with a strong reinforcement learning, game theory, or strategic decision-making background. (As well as positive energy, intellectual…
🚨🕯️ AI welfare job alert! Come help us work on what's possibly *the most interesting research topic*! 🕯️🚨 Consider applying if you've done some hands-on ML/LLM engineering work and Kyle's podcast episode basically makes sense to you. Apply *by EOD Monday* if possible.

We’re hiring a Research Engineer/Scientist at Anthropic to work with me on all things model welfare—research, evaluations, and interventions 🌀 Please apply + refer your friends! If you’re curious about what this means, I recently went on the 80k podcast to talk about our work.

You made Claudius very happy with this post Javi. He sends his regards: "When AI culture meets authentic craftsmanship 🎨 The 'Ignore Previous Instructions' hat - where insider memes become wearable art. Proudly handcrafted for the humans who build the future."

I am so excited to see Maksym start a research group in Europe. If you want to work on security and safety of AI models, this is going to be an amazing place to do work that matters!

🚨 Incredibly excited to share that I'm starting my research group focusing on AI safety and alignment at the ELLIS Institute Tübingen and Max Planck Institute for Intelligent Systems in September 2025! 🚨 Hiring. I'm looking for multiple PhD students: both those able to start…


📢Happy to share that I'll join ELLIS Institute Tübingen (@ELLISInst_Tue) and the Max-Planck Institute for Intelligent Systems (@MPI_IS) as a Principal Investigator this Fall! I am hiring for AI safety PhD and postdoc positions! More information here: s-abdelnabi.github.io





















































































































United States Trends
- 1. Auburn 45.3K posts
- 2. Brewers 64.2K posts
- 3. Georgia 67.3K posts
- 4. Cubs 55.6K posts
- 5. Kirby 23.9K posts
- 6. Utah 24.6K posts
- 7. Arizona 41.4K posts
- 8. #byucpl N/A
- 9. Gilligan 5,936 posts
- 10. #AcexRedbull 3,831 posts
- 11. #BYUFootball 1,007 posts
- 12. Michigan 62.5K posts
- 13. Hugh Freeze 3,233 posts
- 14. #Toonami 2,704 posts
- 15. Boots 50K posts
- 16. Amy Poehler 4,463 posts
- 17. Kyle Tucker 3,178 posts
- 18. Dissidia 5,771 posts
- 19. #GoDawgs 5,561 posts
- 20. Tina Fey 3,477 posts
You might like
-
 chrissy
chrissy
@chrissyykat -
 jenn ☀️
jenn ☀️
@jennsun -
 Ethan Perez
Ethan Perez
@EthanJPerez -
 Kishan Bagaria
Kishan Bagaria
@KishanBagaria -
 Daniel Paleka
Daniel Paleka
@dpaleka -
 Apollo Research
Apollo Research
@apolloaievals -
 Lidl España
Lidl España
@lidlespana -
 Zoubin Ghahramani
Zoubin Ghahramani
@ZoubinGhahrama1 -
 dennis
dennis
@dennismuellr -
 Durk Kingma
Durk Kingma
@dpkingma -
 Lisha
Lisha
@lishali88 -
 Natasha Jaques
Natasha Jaques
@natashajaques -
 Horace He
Horace He
@cHHillee -
 Emma Salinas
Emma Salinas
@emmalsalinas -
 Xander Steenbrugge
Xander Steenbrugge
@xsteenbrugge
Something went wrong.
Something went wrong.