

🚀 Introducing our new tech report: Muon is Scalable for LLM Training We found that Muon optimizer can be scaled up using the follow techniques: • Adding weight decay • Carefully adjusting the per-parameter update scale ✨ Highlights: • ~2x computational efficiency vs AdamW…



🚀 Introducing DeepSeek-V3! Biggest leap forward yet: ⚡ 60 tokens/second (3x faster than V2!) 💪 Enhanced capabilities 🛠 API compatibility intact 🌍 Fully open-source models & papers 🐋 1/n

Highly recommend this user-friendly project if you start with LM pretraining and want to build your own model/optimizer. The repo is easy to understand, easy to edit and easy to implement new ideas with minimum workloads. Well done Keller! Looking forward to your records on VIT:)

I enjoy getting NanoGPT training speed records. I’m also interested in making my formulation of NanoGPT speedrunning an accessible benchmark on which other people find it easy to try new ideas. To that end, I have tried to keep the code of the current record short, and minimize…

Fixed a bug which caused all training losses to diverge for large gradient accumulation sizes. 1. First reported by @bnjmn_marie, GA is supposed to be mathematically equivalent to full batch training, but losses did not match. 2. We reproed the issue, and further investigation…


Harm's Law of Smol Models (HLSM) tells us how much we need to scale up the data size (k_D) as we scale down the model size (k_N), if we wish to preserve the loss of a Chinchilla-optimal model. harmdevries.com/post/model-siz…
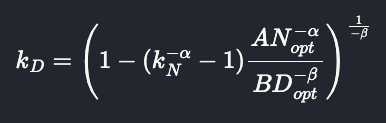

Afraid of sum-of-squares (SOS) relaxations? Read this new blog post for a smooth ride in the Fourier domain. francisbach.com/sums-of-square…























































United States 트렌드
- 1. Thanksgiving 2.06M posts
- 2. Jack White 5,764 posts
- 3. Packers 39.8K posts
- 4. Dan Campbell 2,472 posts
- 5. #GoPackGo 6,364 posts
- 6. Jordan Love 6,882 posts
- 7. Watson 12K posts
- 8. Goff 6,357 posts
- 9. #GBvsDET 3,238 posts
- 10. Thankful 411K posts
- 11. #OnePride 5,823 posts
- 12. Wicks 4,250 posts
- 13. Gibbs 7,129 posts
- 14. Jameson Williams 1,749 posts
- 15. Turkey 263K posts
- 16. Green Bay 6,140 posts
- 17. Tom Kennedy 1,061 posts
- 18. Jamo 3,337 posts
- 19. Amon Ra 2,588 posts
- 20. Seven Nation Army N/A
Something went wrong.
Something went wrong.