
You might like








🚀 Introducing InstantSfM: Fully Sparse and Parallel Structure-from-Motion. ✅ Python + GPU-optimized implementation, no C++ anymore! ✅ 40× faster than COLMAP with 5K images on single GPU! ✅ Scales beyond 100 images (more than VGGT/VGGSfM can consume)! ✅ Support metric scale.



To solve AGI, we must first solve Geoguessr For that I built vlm-gym, a simple RL gym written in scratch, in JAX for Qwen3VL-4B (released yesterday) And added Geospot, a RL environment for geolocation and learned VLMs can learn how to geoguess. More:

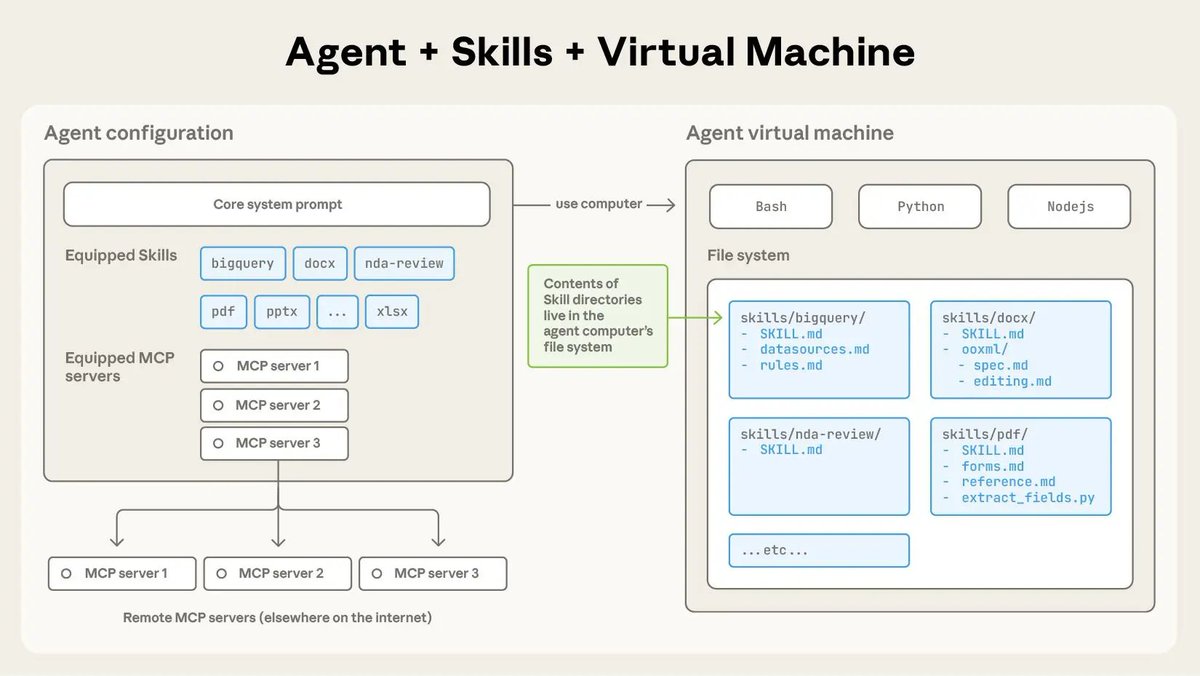
Today we're introducing Skills in claude dot ai, Claude Code, and the API. Skills let you package specialized knowledge into reusable capabilities that Claude loads on demand as agents tackle more complex tasks. Here's how they work and why they matter for the future of agents:

Google Maps v2.0? 🌍 Here's @PlayCanvas streaming a scene with 2 BILLION Gaussians! 💪 Coming sooooon!

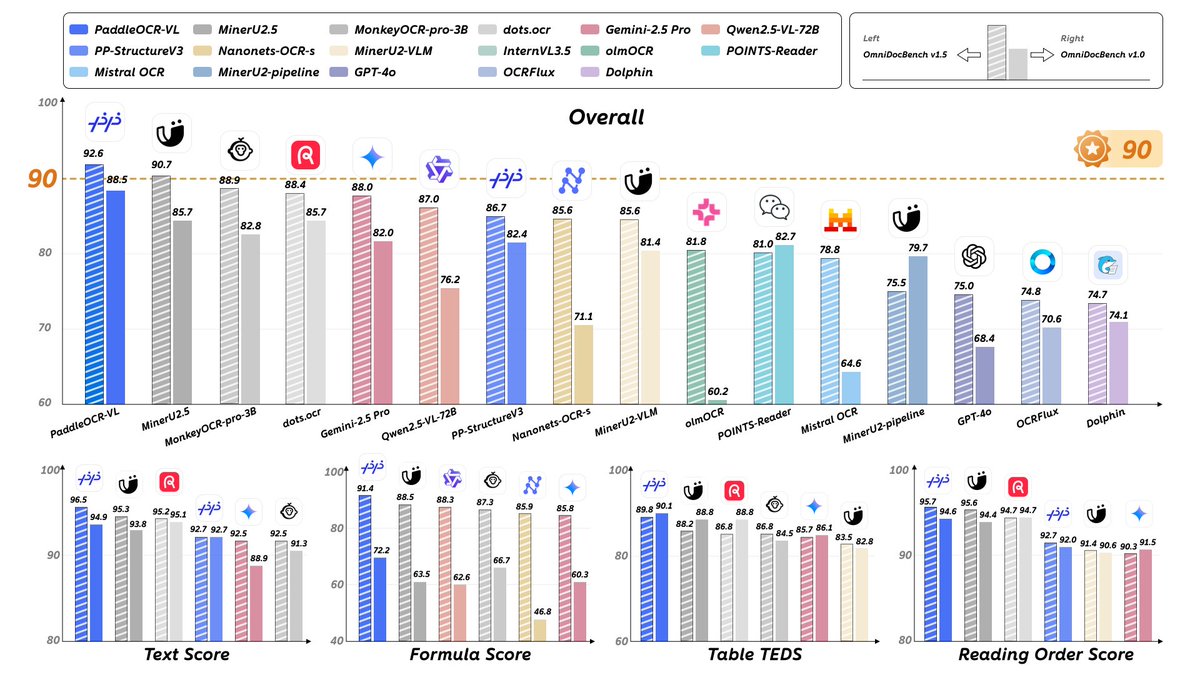
🚀 PaddleOCR-VL is here! Introducing PaddleOCR-VL (0.9B) — the ultra-compact Vision-Language model that reaches SOTA accuracy across text, tables, formulas, charts & handwriting. Breaking the limits of document parsing!🌍 Powered by: • NaViT dynamic vision encoder • ERNIE…

⚡️Generating 3DGS scenes in 5 seconds on a single GPU⚡️ #FlashWorld enables ⚡️*fast*⚡️ (10~100x faster than previous methods) and 🔥*high-quality*🔥 3D world generation, from a single image or text prompt. Code: github.com/imlixinyang/Fl… Page: imlixinyang.github.io/FlashWorld-Pro…

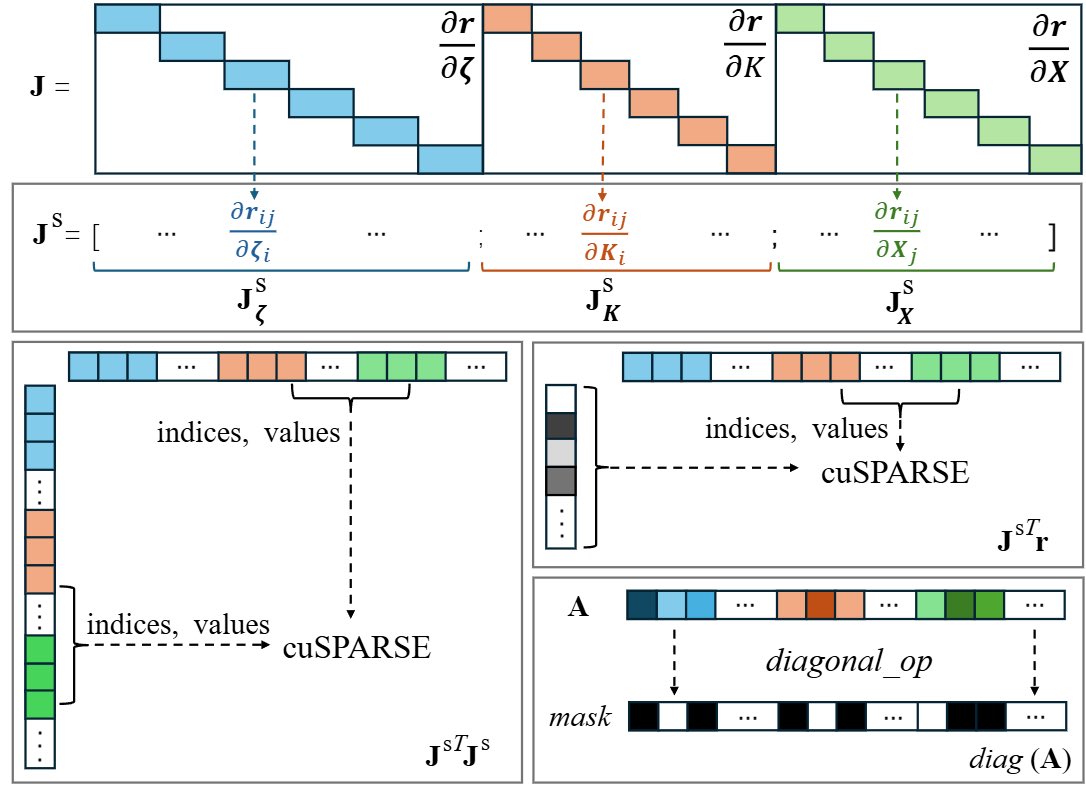
InstantSfM: Fully Sparse and Parallel Structure-from-Motion TLDR: InstantSfM is a fully sparse and parallel Structure-from-Motion pipeline. It leverages GPU acceleration to achieve up to 40× speedup over traditional methods like COLMAP, while maintaining or improving…

make nanochat multimodal for < $10! this evening, i trained nanochatVL: via a projection model (llava-style) between SigLIP ViT and @karpathy nanochat to extend its understanding to images it's a huge wip rn, but have a few promising results! now i can finally sleep

Excited to release new repo: nanochat! (it's among the most unhinged I've written). Unlike my earlier similar repo nanoGPT which only covered pretraining, nanochat is a minimal, from scratch, full-stack training/inference pipeline of a simple ChatGPT clone in a single,…


The model + resources are now on HuggingFace and GitHub so researchers can keep building and experimenting. More details here: blog.google/technology/ai/…

FlashWorld: High-quality 3D Scene Generation within Seconds Contributions: • We introduce a dual-mode pretraining strategy built on a video diffusion model to train a multi-view diffusion model. This model is capable of operating in both MV-oriented and 3D-oriented modes. •…

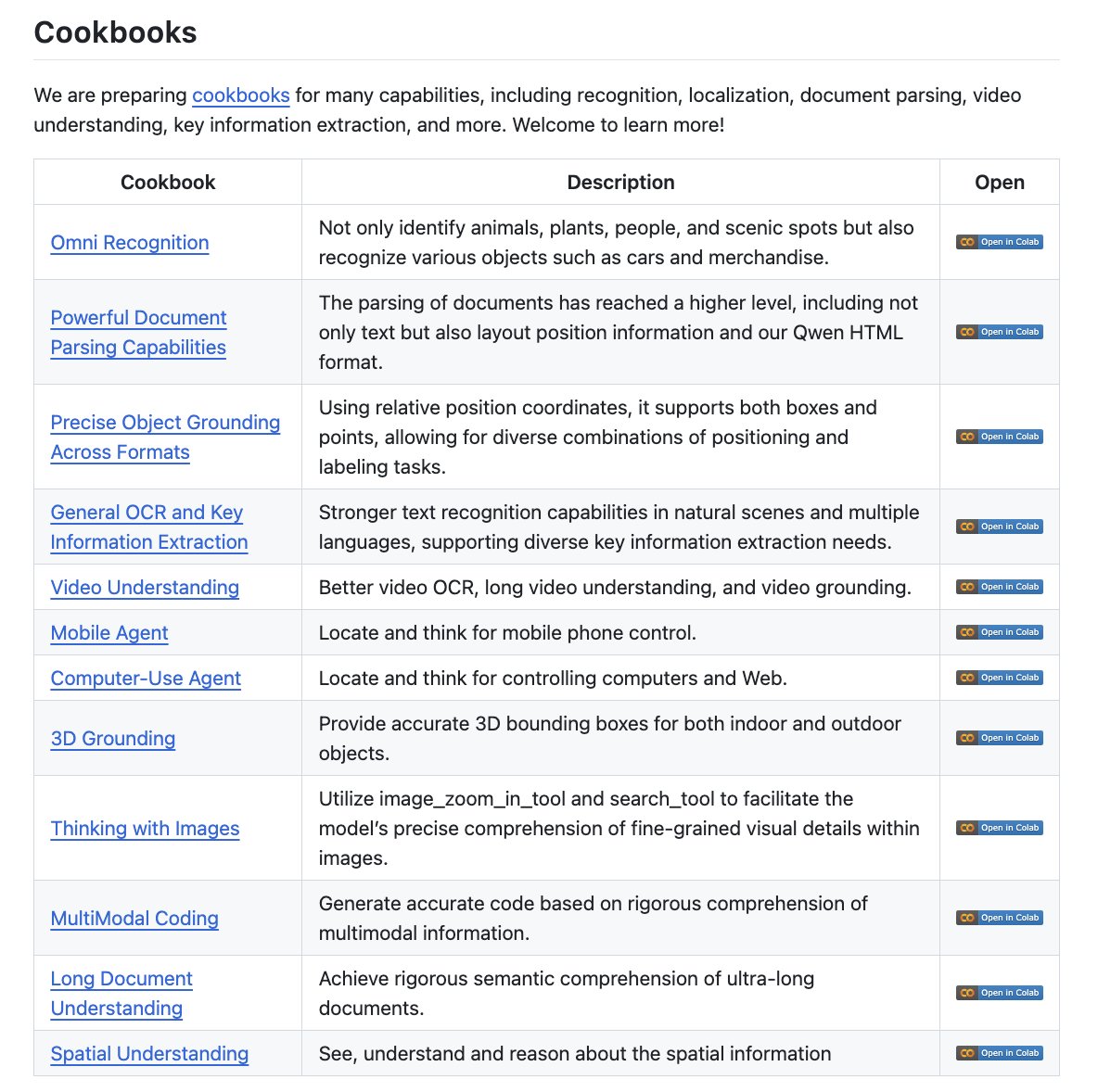
the team at @Alibaba_Qwen literally cooks 🤠 they released a VLM cookbook that shows you how to do various tasks from OCR to object grounding using Qwen3-VL 👏

Spatial representations are central to world models🌍 SuperDec is an extremely compact 3D scene representation (replacing millions of Gaussians with just a few hundred primitives) ideal for abstract reasoning and planning in 3D ➡️super-dec.github.io ✨Oral @ICCVConference

Are photorealistic representations all we need? In SuperDec, we turn millions of points into compact and modular abstractions made of just a few superquadrics!🧩 Try our code and get a compact representation of your favorite scene!🚀 👾: github.com/elisabettafede…

Excited about this one. Direct result of customer feedback. We saw hundreds of chat apps being created, and now you can actually hook it up to OpenAI. x.com/magicpatterns/…

You can now connect your Magic Patterns design to Open AI in our new integrations tab. Building a chatbot or chat app is one of the most popular use cases, so we made it real.



This paper shows a 2-brain design so a voice model can think and speak with near 0 delay. It scores 92.8% on a math speech test at 0 latency, and 82.5 on a dialogue test. Waiting for a full chain of thought slows replies, and mixing thinking and speaking in one model causes…

🇨🇳 There Are More Robots Working in China Than the Rest of the World Combined They recorded a world record of 2mn+ industrial robots working in factories.

🤖🇨🇳 China’s added 295,000 industrial robots in 2024 and a stock above 2mn. While US added about 34,000, Germany 27,000, and the UK 2,500. “If we lose this, we do not have a future at Ford,” says Jim Farley, CEO at Ford Robot intensity is also way higher in China, with 567…


New LFM2 release 🥳 It's a Japanese PII extractor with only 350M parameters. It's extremely fast and on par with GPT-5 (!) in terms of quality. Check it out, it's available today on @huggingface!
Excited to release new repo: nanochat! (it's among the most unhinged I've written). Unlike my earlier similar repo nanoGPT which only covered pretraining, nanochat is a minimal, from scratch, full-stack training/inference pipeline of a simple ChatGPT clone in a single,…
Search every version of your Revenue DAX definitions across all PBIX files in sub-second time with DuckDB and the new pbix2vpax() scalar function

I made a RL policy that guesses where a picture was taken without GPS data It continuously learns, updating its weights with every use in realtime -- over the weekend it improved 13.9% with <100 images Best of all, it does this without ever storing any image data, link below
made an app that guesses where you are in the world with just a picture using image embeddings trained on street view data first time using swiftui, consumer apps in general, TestFlight below































































































United States Trends
- 1. Bengals 35.1K posts
- 2. Rodgers 22.2K posts
- 3. Ace Frehley 61.5K posts
- 4. Flacco 15K posts
- 5. #911onABC 13.7K posts
- 6. Chase Brown 3,218 posts
- 7. Cuomo 47.6K posts
- 8. #HereWeGo 6,510 posts
- 9. Ramsey 7,432 posts
- 10. Mookie 8,341 posts
- 11. Bolton 167K posts
- 12. #TNFonPrime 2,379 posts
- 13. Asheville 11.3K posts
- 14. Ja'Marr Chase 2,561 posts
- 15. RIP Spaceman 2,073 posts
- 16. #PITvsCIN 1,999 posts
- 17. Sliwa 20.3K posts
- 18. Yoshi 20.2K posts
- 19. athena 12K posts
- 20. #NYCMayoralDebate 1,352 posts







Something went wrong.
Something went wrong.