
قد يعجبك















これは面白い展開かもしれない

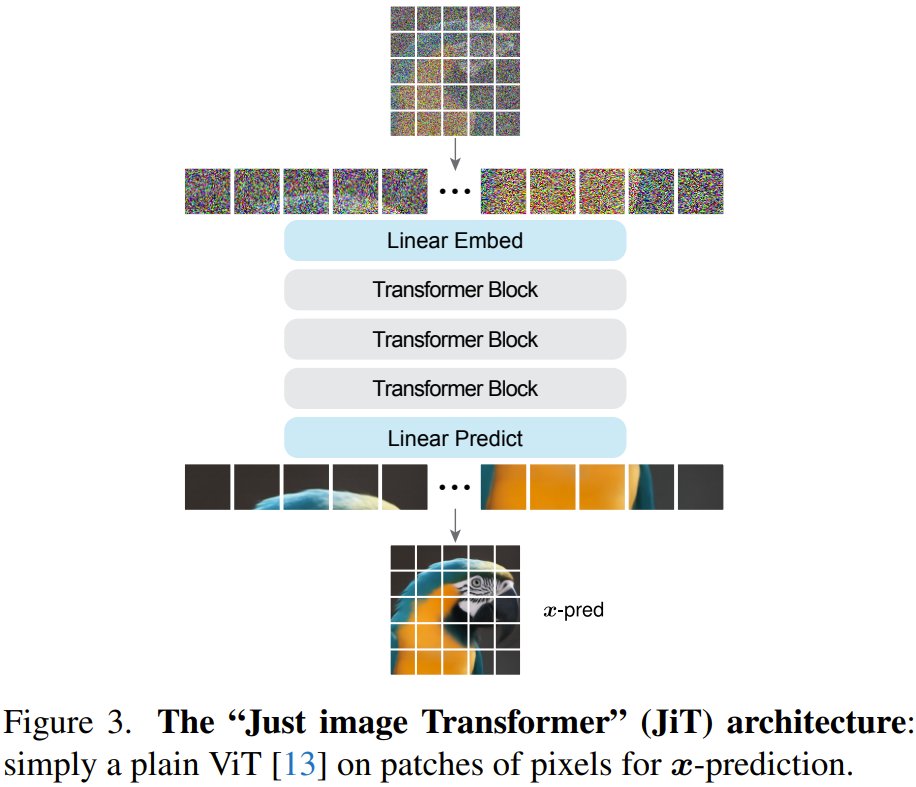
Huge! @TianhongLi6 & Kaiming He (inventor of ResNet) just Introduced JiT (Just image Transformers)! JiTs are simple large-patch Transformers that operate on raw pixels, no tokenizer, pre-training, or extra losses needed. By predicting clean data on the natural-data manifold,…
久々に技術記事を書きました。今年は Consistency Models について勉強しています。 zenn.dev/umeko/articles…

Open-Sora-Planの論文なのね

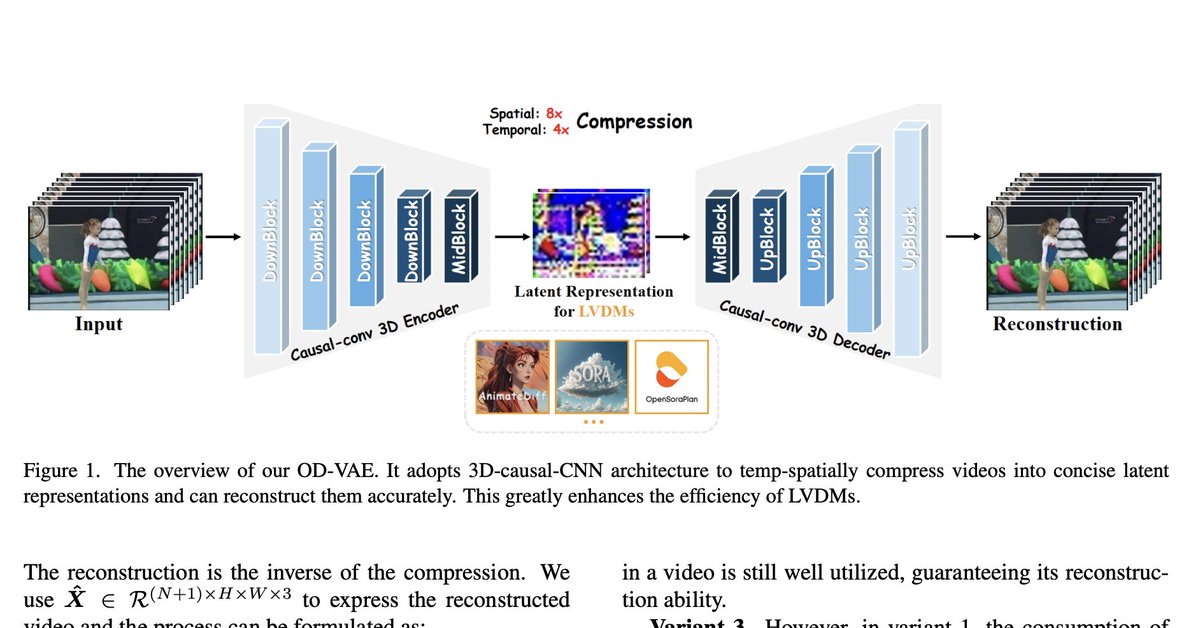
OD-VAE An Omni-dimensional Video Compressor for Improving Latent Video Diffusion Model paper page: huggingface.co/papers/2409.01… Variational Autoencoder (VAE), compressing videos into latent representations, is a crucial preceding component of Latent Video Diffusion Models (LVDMs).…
画像でやられてることは結構なスピードで他ドメインに展開されていきますね dai-wenxun.github.io/MotionLCM-page/
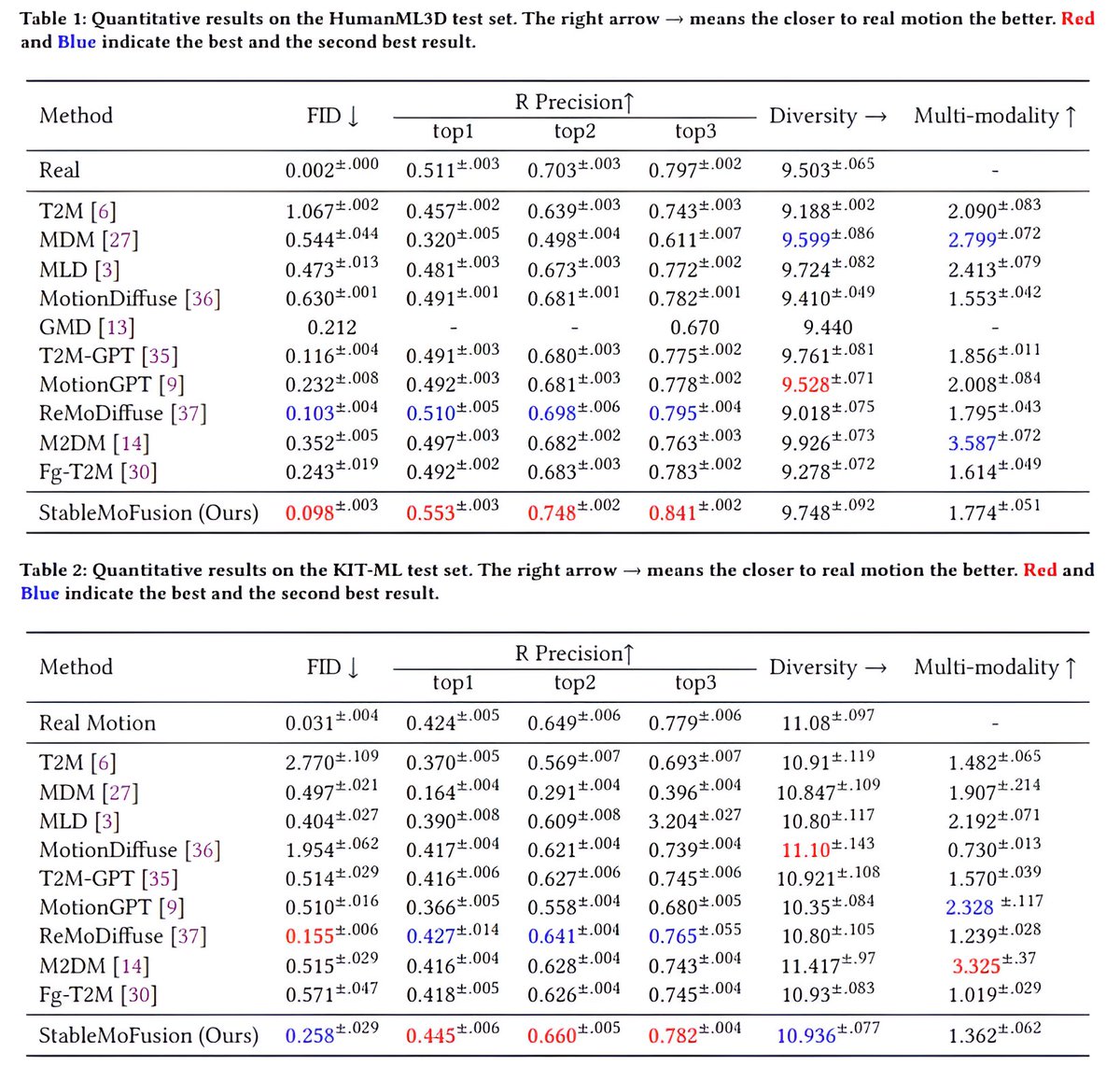
モーション生成界隈だとHumanmML3D とKITの2つのデータセットでベンチマークをとることが多いんですが、論文手法の R-Precision がリアルデータのスコアを超え始めててベンチマークとしてあんまり健全じゃない気がする h-y1heng.github.io/StableMoFusion…




















































































United States الاتجاهات
- 1. Broncos 43.1K posts
- 2. Mariota 12.3K posts
- 3. Bo Nix 9,409 posts
- 4. Commanders 31.8K posts
- 5. Ertz 3,035 posts
- 6. Riley Moss 2,225 posts
- 7. #RaiseHail 5,552 posts
- 8. Treylon Burks 11.6K posts
- 9. #BaddiesUSA 22.2K posts
- 10. Terry 19.9K posts
- 11. Bobby Wagner 1,028 posts
- 12. Deebo 3,011 posts
- 13. #RHOP 11.1K posts
- 14. Collinsworth 2,859 posts
- 15. Jake Moody N/A
- 16. #SNFonNBC N/A
- 17. Sean Payton 1,535 posts
- 18. #DENvsWAS 3,137 posts
- 19. Chicharito 28.8K posts
- 20. Bonitto 5,247 posts











Something went wrong.
Something went wrong.