
I'm building my own PyTorch from scratch, Implementing multiple core features like tensors, autograd, NN layers, optimizers, and more. The core engine will be written in C++/CUDA for performance, with a Pythonic, PyTorch-like API. starting C++ from today.

exams are finally over. back to posting daily, need to work alot on GenAI, python performance, gpu, papers, models, inference, and alot more. starting devlogs and multiple updates from tomorrow.


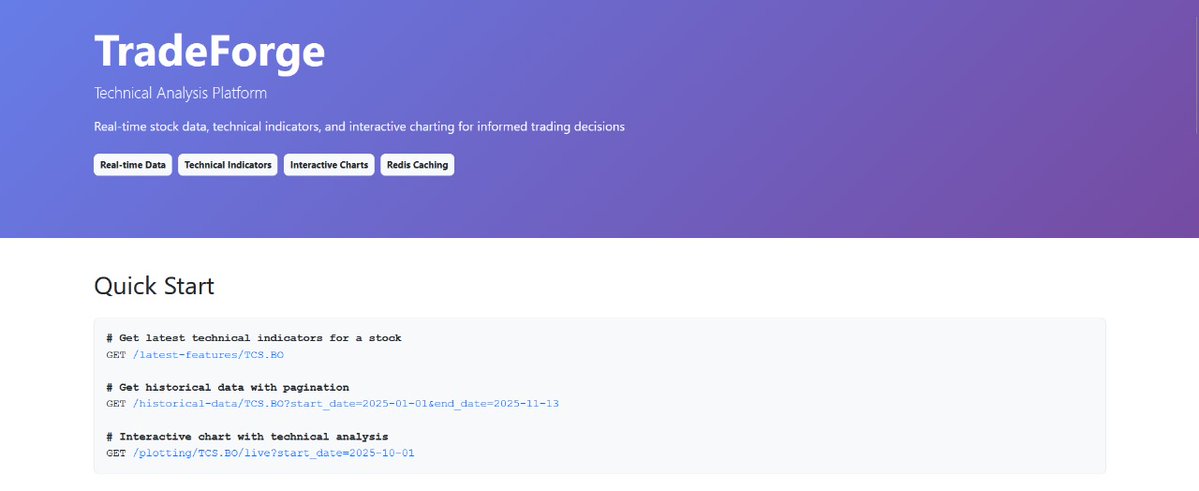
Yo . Just shipped TradeForge , a technical analysis platform that I've built with FastAPI. It pulls real-time stock data , calculates moving averages ( 5 days to even 200days) and gives you interactive charts . Check it out at : …adeforgeweb-production.up.railway.app More info below
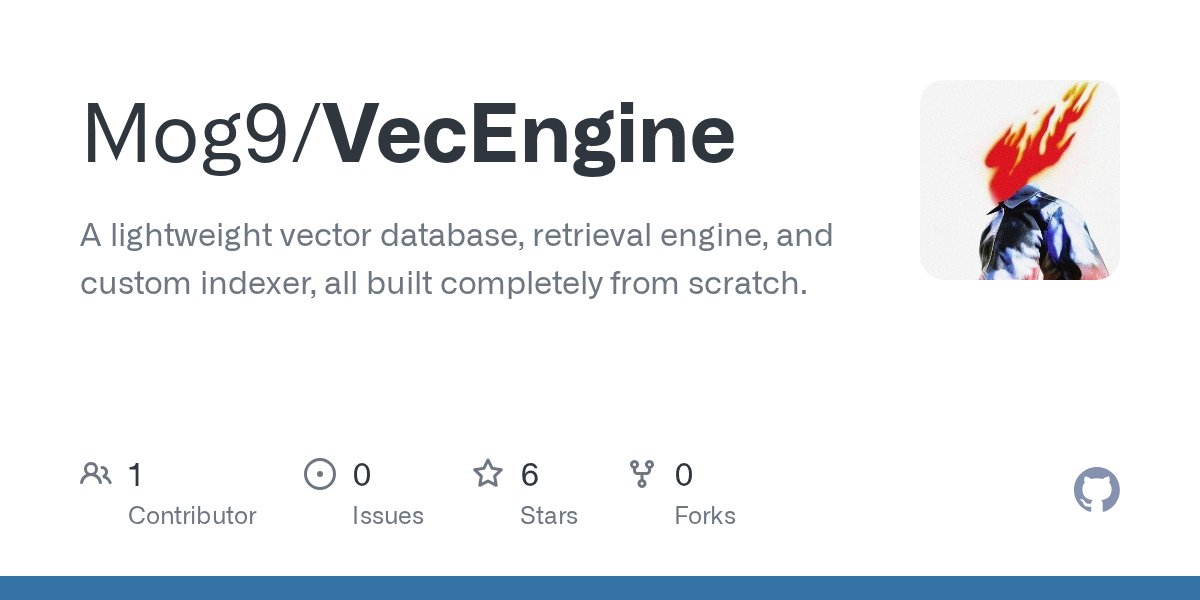
built a lightweight vector database + retrieval engine from scratch, handles embedding, similarity search, and relevance filtering without any external tools. also built a custom indexer from scratch, vector clustering + search, no FAISS, pure python. github.com/Mog9/VecEngine
lol
internals starting from tomorrow, practicals and external soon, will be less active for a while
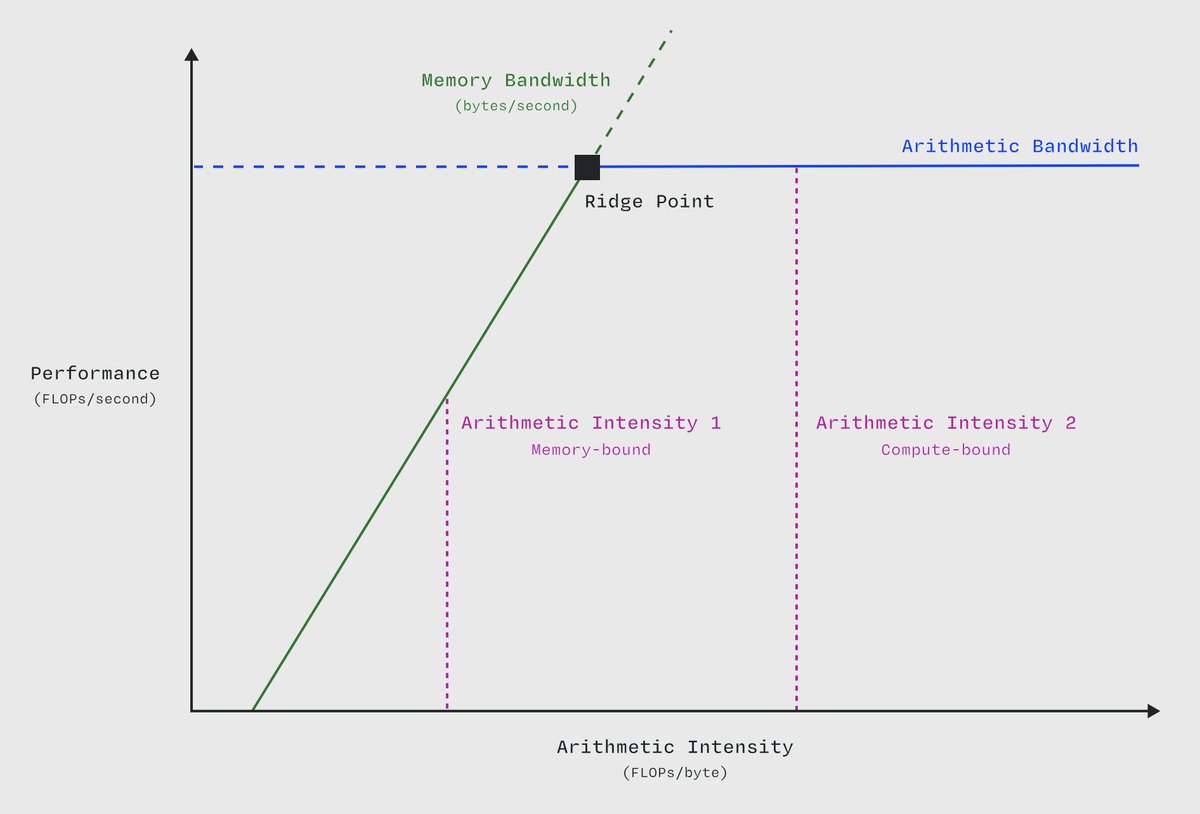
GPU Bottlenecks Explained: every GPU has one mission, to process massive amounts of data as fast as possible. but no matter how powerful the hardware, something always ends up limiting that speed. that limiting factor is the bottleneck, the point where performance gets stuck.…

tried @getalchemyst and its p good in context and retrieval, It remembers what I say in chat plus whatever I upload, had to try cuz im working on stuff related to this. it just picks up the conversation using all that context, good shit.
Simple Explanation on How RAG Works: Retrieval Augmented Generation is one of the most powerful techniques in gen-ai today. instead of relying only on what a LLM was trained on, RAG allows the model to retrieve relevant information from external data sources (like documents,…
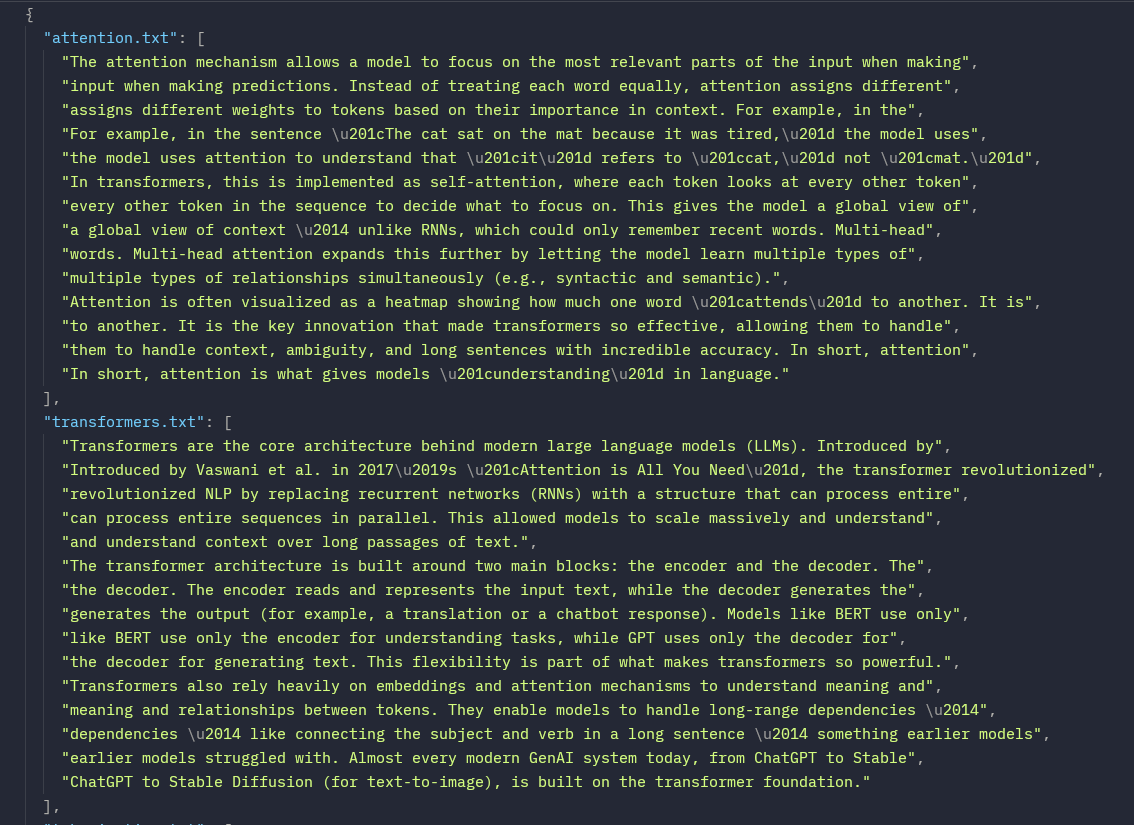



Introducing customGPT-RAG: Built a custom RAG (Retrieval-Augmented Generation) chatbot that combines local document retrieval with generative AI to deliver context-aware, knowledge-grounded answers. It can answer questions from your private information: just add your own text…
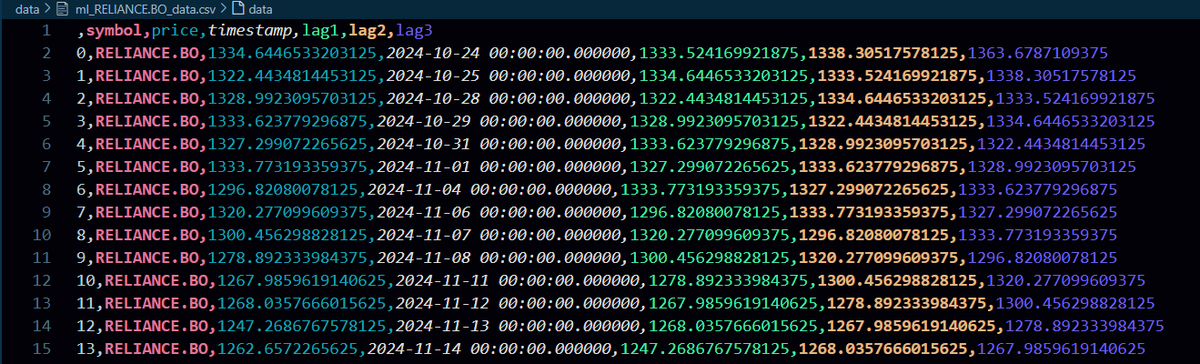
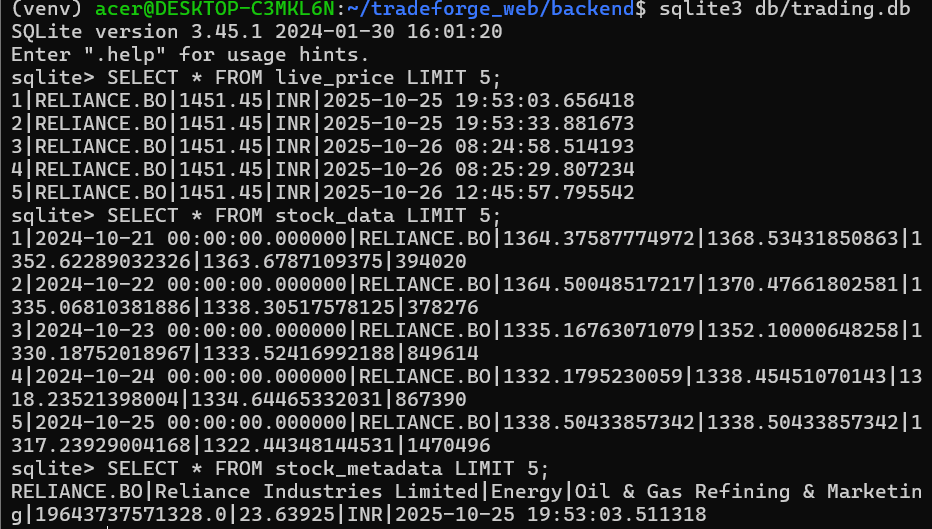
(1/3) Currently building a live trading simulation web app. as of now : created scripts to fetch OHLC price data for a particular stock from any respective exchange ( depends on the specified suffix for example .BO for BSE and .NS for NSE). read more below

I'm blessed to have idiots like this making amazing things on my TL, I swear man. Check out @mohitwt_ y'all!
Introducing customGPT-RAG: Built a custom RAG (Retrieval-Augmented Generation) chatbot that combines local document retrieval with generative AI to deliver context-aware, knowledge-grounded answers. It can answer questions from your private information: just add your own text…
Introducing customGPT-RAG: Built a custom RAG (Retrieval-Augmented Generation) chatbot that combines local document retrieval with generative AI to deliver context-aware, knowledge-grounded answers. It can answer questions from your private information: just add your own text…
ml, dl, genai and maths in 4 months

Juniors pls stay away from such clickbait videos. Learning ML is a marathon, not a sprint (4 months)

> built a tiny tool to visualize tokenization in LLMs, using gpt-2 here

I've started my GenAI journey: > understood alot of theory > built a mini chatbot locally with context & prompt experimentation: - takes user input - generates model responses - keeps very small conversation history - lets u experiment with different prompts and generation…
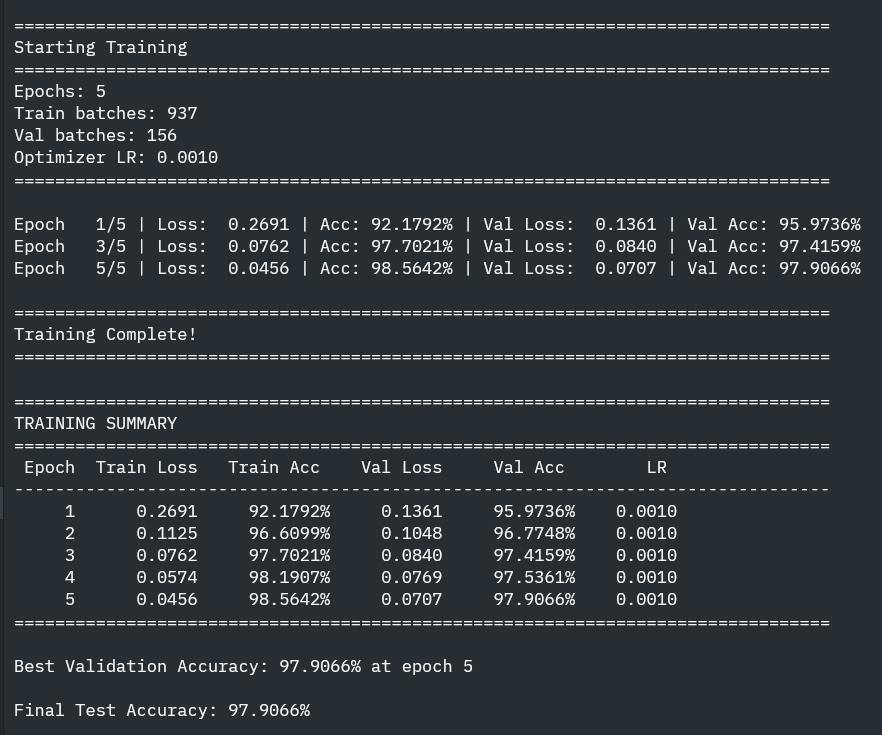
> TRAINED MNIST ON MY FRAMEWORK > 98% accuracy > 784 -> 128 -> 64 -> 10 nn architecture on MNIST ~ 60,000 images / 64 = 937 batches per epoch ~ 4,690 iterations total. 5 epochs took like ~3 hours to train on CPU, I dont have GPU support yet or any optimization done on…
already better than onana imo

Humanoid robots learn to be the goalkeeper. Ball flying at a robot. Half a second to react. The robot LAUNCHES itself sideways, full-body dive, catches it mid-air. One AI policy that controls everything. It wild to watch.























































































United States Trends
- 1. #AEWDynamite 19.7K posts
- 2. #TusksUp N/A
- 3. Giannis 77.6K posts
- 4. #Survivor49 2,616 posts
- 5. #TheChallenge41 2,009 posts
- 6. Ryan Leonard N/A
- 7. Skyy Clark N/A
- 8. Claudio 28.8K posts
- 9. Jamal Murray 5,827 posts
- 10. #ALLCAPS 1,199 posts
- 11. Steve Cropper 5,036 posts
- 12. Kevin Overton N/A
- 13. Will Wade N/A
- 14. Ryan Nembhard 3,428 posts
- 15. Diddy 72.9K posts
- 16. Hannes Steinbach N/A
- 17. Yeremi N/A
- 18. Achilles 5,350 posts
- 19. Klingberg N/A
- 20. Dark Order 1,774 posts
Something went wrong.
Something went wrong.