
PyData Munich
@pydatamunich
We are a local group that meets regularly throughout Munich to learn data science, incorporating free and accessible tutorials through an engaging community,
You might like











Launching Core v2 – The Future of Web-Based Video Rendering Today, we're rolling out a major update to our WebCodecs-powered video rendering engine. We've completely removed PixiJS and Pixi Filters, replacing them with a new, custom-built render system designed for speed,…


Our Call for Proposals for Summit NY is closing EOD Sunday (11:59pm PT). Got a talk or workshop you want to get on our radar for Summit? Send it to us in the link in the next post!

Join us for the first dstack user group meetup in Berlin - a unique gathering diving deep into AI infrastructure & open-source AI! 🌟 Expect lightning talks, demos, and networking. RSVP now🔗lu.ma/m8arz807




Why do we treat train and test times so differently? Why is one “training” and the other “in-context learning”? Just take a few gradients during test-time — a simple way to increase test time compute — and get a SoTA in ARC public validation set 61%=avg. human score! @arcprize


Gil free is such a good news. Tho I still be that we will have issues with decency for a decades 🙈

🐍💥Python 3.13.0 has been released! 🎉 This is the first version with 🧵experimental GIL-free mode, an experimental JIT compiler🔧, a slick new REPL 🖌️ and many new cool features! And it's faster, smarter, and more colorful than ever! 🚀 Get it here: python.org/downloads/rele…
quantized.w8a16 has the highest average recovery rate at around 99.8%


📢 4-bit Llama 3.1 405B, 70B, 8B Now Available! 📢 @AIatMeta's Llama 3.1 models are now quantized to 4 bits by @neuralmagic's research team and available with ~100% recovery. These enable 4X cheaper deployments (405B goes from 2 8x80GB nodes to 1 4x80GB). Continued in next...


On June 20th (6pm) we will host the next MUC🥨NLP meetup at Quality Minds GmbH. More Infos: munich-nlp.github.io/events/june-24… RSVP: meetup.com/pydata-munchen… Looking forward to seeing you all there!

GPU poor but have cool ideas? Say less Thread of GPU Grants below 🧵👇 Image by #SD3


It's crazy how over time I have slowly replaced all of my command line tools with Rust equivalents 🦀 - cat → bat - pip → uv - grep → ripgrep - htop → zenith - fswatch → watchexec Any other good ones?
The AI Engineer World's Fair is confirmed for June 25 - 27 in San Francisco! Super Early Bird Tickets now on sale! Lock in the best rate by purchasing your ticket today, and use code TWEETY for an extra $100 off! Link in the next post🐦 Some more details about the event:…




A short thread about changes in the transformer architecture since 2017. Reading articles about LLMs, you can see phrases like “we use a standard transformer architecture.” But what does "standard" mean, and have there been changes since the original article? (1/6)

Interestingly despite the 5 years(!) of hyper-growth of NLP space, Vanilla Transformer is holding to the Lindy Effects which is the idea that the older something is, the longer it's likely to be around in the future.

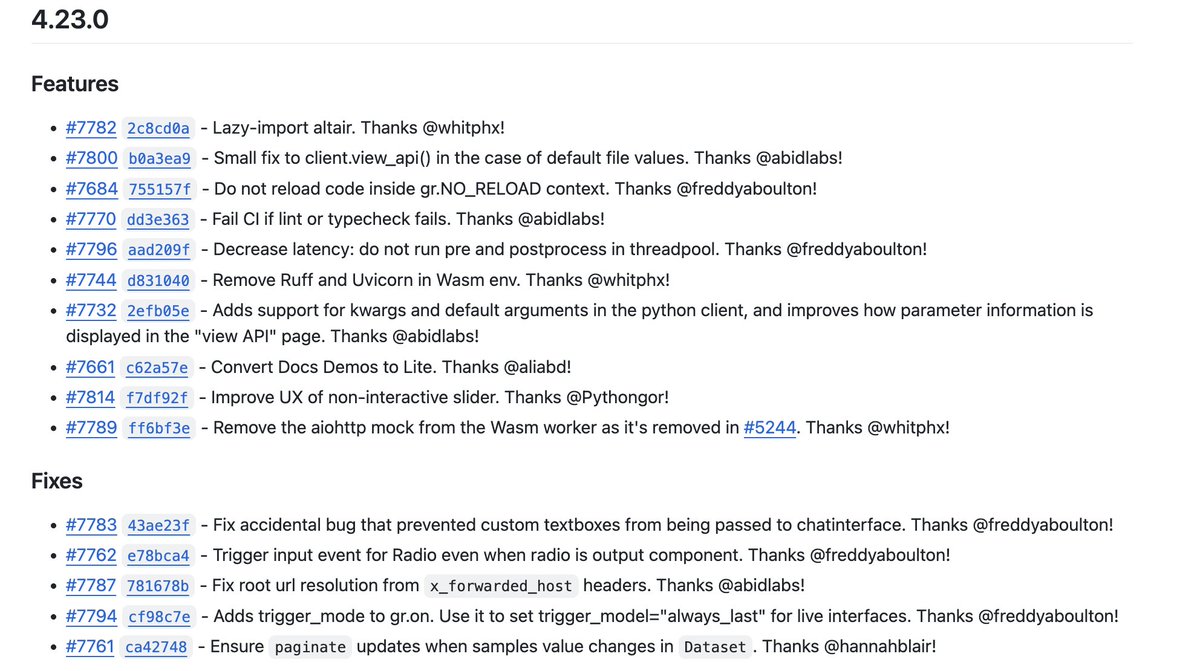
Start off the week by upgrading to Gradio 4.23.0 🔥 ⌨️ Big improvements to Gradio's Reload mode ⚡️ Performance improvements -- speeds up postprocessing/preprocessing for components. 🖼️ Redesigned "view API" page 🪄 Demos on the Gradio website now running on Gradio Lite

Podcast drop: CUDA graph trees pytorch-dev-podcast.simplecast.com/episodes/cuda-…
pytorch-dev-podcast.simplecast.com
PyTorch Developer Podcast

Here's a recipe from @ggerganov for running a GGUF of the new Mistral 7B 0.2 completion model on macOS using llama.cpp and Homebrew



- pip install mlx - git clone github.com/ml-explore/mlx… - Build the docs github.com/ml-explore/mlx… but use `make latexpdf` If there's interest, we could host a pre-built PDF on the static docs page, lmk.
github.com
mlx/docs/README.md at main · ml-explore/mlx
MLX: An array framework for Apple silicon. Contribute to ml-explore/mlx development by creating an account on GitHub.
Except it’s called AI engineering now Come to @aiDotEngineer conf to learn more

2013 — 2023: you were hired to do machine learning but do data engineering 2023 — : you were hired to do machine learning but do web dev
Btw: • All the model code is in *Python* • No compilation needed • Fully dynamic graph creation -> easy to debug • Simple code -> easy to extend
MLX 0.7 → 0.8 Tokens per second on M2 Ultra - 4-bit Starcoder 7B, 64.3 → 74 - 4-bit Mistral 7B, 73.1 → 83.2 Thanks to Nanobind and fast RMS and layer norms. Look at that Mistral go:


































































United States Trends
- 1. #GMMTV2026 3.14M posts
- 2. Good Tuesday 31.6K posts
- 3. MILKLOVE BORN TO SHINE 486K posts
- 4. #tuesdayvibe 2,401 posts
- 5. Taco Tuesday 11.2K posts
- 6. WILLIAMEST MAGIC VIBES 64.2K posts
- 7. Kelly 330K posts
- 8. Alan Dershowitz 3,538 posts
- 9. Barcelona 166K posts
- 10. #DittoSeries 88.7K posts
- 11. TOP CALL 9,424 posts
- 12. Enron 1,681 posts
- 13. MAGIC VIBES WITH JIMMYSEA 84.2K posts
- 14. JOSSGAWIN MAGIC VIBES 28.3K posts
- 15. University of Minnesota N/A
- 16. AI Alert 8,152 posts
- 17. Maddow 16.4K posts
- 18. #ONEPIECE1167 9,082 posts
- 19. #JoongDunk 127K posts
- 20. Hegseth 102K posts










Something went wrong.
Something went wrong.