
你可能會喜歡















Building a foundation model is an art! it involves many complex dimensions and stages, from architecture, data, pre-training, post-training to inference. getting it all right requires masterful and tasteful execution. there are very few teams around the world that can make…
LFMs fly on iphone! you can try a large series of LFMs on Apollo: apps.apple.com/us/app/apollo-…


Apple wasn’t kidding, the iPhone 17 Pro is really built for running LLMs Here’s LFM2 8B A1B by @LiquidAI_ running on-device with MLX in @LocallyAIApp, the iPhone runs the 8B model with zero struggle Thanks @Prince_Canuma for the port to MLX, it made the MLX Swift port possible

Day 1 of the @LiquidAI_ fine-tuning hackathon in Tokyo this weekend. Jointly organized with @weights_biases and @LambdaAPI

Liquid AI Releases LFM2-8B-A1B: An On-Device Mixture-of-Experts with 8.3B Params and a 1.5B Active Params per Token How much capability can a sparse 8.3B-parameter MoE with a ~1.5B active path deliver on your phone without blowing latency or memory? Liquid AI has released…

Btw, it should get faster on the next version of MLX Swift. We made some improvements to 1D grouped convs that will speed up this model nicely.
Apple wasn’t kidding, the iPhone 17 Pro is really built for running LLMs Here’s LFM2 8B A1B by @LiquidAI_ running on-device with MLX in @LocallyAIApp, the iPhone runs the 8B model with zero struggle Thanks @Prince_Canuma for the port to MLX, it made the MLX Swift port possible

Hello everyone! Let me (re)introduce myself!

People should give a try on @LiquidAI_ models with Spectrum. You can SFT/RLFT your models with VERY LOW memory footprint, without having to do LoRA or qLoRA... This beautiful thing prevents a lot of the catastrophic forgetting. LFM models work out of the box.

I added LFM 2 8B A1B in @LocallyAIApp for iPhone 17 Pro and iPhone Air The first mixture of experts model by @LiquidAI_, 8B total parameters (1B active), performance similar to 3-4B models but speed of a 1B model Runs great on the 17 Pro with Apple MLX


We just released LFM2-8B-A1B, a small MoE optimized for latency-sensitive applications on-device. Larger model quality with the speed of a 1.5B class model. Huggingface: huggingface.co/LiquidAI/LFM2-… Blog: liquid.ai/blog/lfm2-8b-a…


Meet LFM2-8B-A1B, our first on-device Mixture-of-Experts (MoE)! 🐘 > LFM2-8B-A1B is the best on-device MoE in terms of both quality and speed. > Performance of a 3B-4B model class, with up to 5x faster inference profile on CPUs and GPUs. > Quantized variants fit comfortably on…


LFM2-8B-A1B just dropped on @huggingface! 8.3B params with only 1.5B active/token 🚀 > Quality ≈ 3–4B dense, yet faster than Qwen3-1.7B > MoE designed to run on phones/laptops (llama.cpp / vLLM) > Pre-trained on 12T tokens → strong math/code/IF



Small MoEs are on the rise. @LiquidAI_ drops LFM2-8B-A1B.
LFM2-8B-A1B just dropped on @huggingface! 8.3B params with only 1.5B active/token 🚀 > Quality ≈ 3–4B dense, yet faster than Qwen3-1.7B > MoE designed to run on phones/laptops (llama.cpp / vLLM) > Pre-trained on 12T tokens → strong math/code/IF
Enjoy our even better on-device model! 🐘 Running on @amd AI PCs with the fastest inference profile!
Meet LFM2-8B-A1B, our first on-device Mixture-of-Experts (MoE)! 🐘 > LFM2-8B-A1B is the best on-device MoE in terms of both quality and speed. > Performance of a 3B-4B model class, with up to 5x faster inference profile on CPUs and GPUs. > Quantized variants fit comfortably on…

Meet LFM2-8B-A1B by @LiquidAI_ - 8B total and 1B active params 🐘 - 5x faster on CPUs and GPUs ⚡️ - Perfect for fast, private, edge 📱/💻/🚗/🤖


Meet LFM2-8B-A1B, our first on-device Mixture-of-Experts (MoE)! 🐘 > LFM2-8B-A1B is the best on-device MoE in terms of both quality and speed. > Performance of a 3B-4B model class, with up to 5x faster inference profile on CPUs and GPUs. > Quantized variants fit comfortably on…

LFM2-8B-A1B Liquid AI’s first on-device MoE, with 8.3B total parameters and 1.5B active per token. It matches 3–4B dense model quality while running faster than Qwen3-1.7B. Architecture - 18 gated short-conv blocks, 6 GQA blocks (LFM2 backbone) - Sparse MoE feed-forward layers…

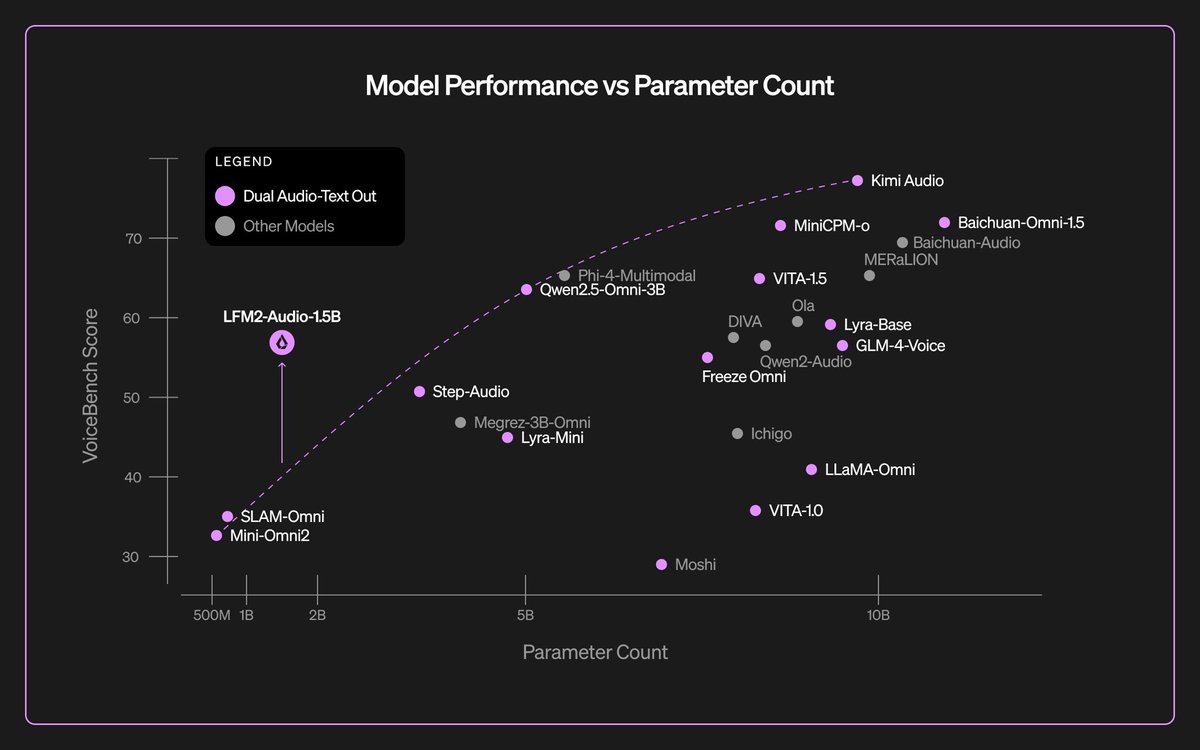

Meet LFM2-8B-A1B, our first on-device Mixture-of-Experts (MoE)! 🐘 > LFM2-8B-A1B is the best on-device MoE in terms of both quality and speed. > Performance of a 3B-4B model class, with up to 5x faster inference profile on CPUs and GPUs. > Quantized variants fit comfortably on…

It's a good model sir. Very proud of the team, we worked very hard to be on the Pareto frontier of quality and efficiency. Even had the chance to write a CPU-optimized kernel for MoE to squeeze everything from the hardware, and that gave us those sweet throughput results.
Meet LFM2-8B-A1B, our first on-device Mixture-of-Experts (MoE)! 🐘 > LFM2-8B-A1B is the best on-device MoE in terms of both quality and speed. > Performance of a 3B-4B model class, with up to 5x faster inference profile on CPUs and GPUs. > Quantized variants fit comfortably on…
Awesome TTS model built on LFM2-350M

Just dropped on HF: kani-tts-370m A lightweight open-source text-to-speech model that sounds great and runs fast! > 370M parameters — efficient and deployable on consumer GPUs > NanoCodec + LFM2-350M > Natural & expressive voice trained with modern neural TTS techniques > Fast…


















































































































United States 趨勢
- 1. Chiefs 106K posts
- 2. Branch 32.4K posts
- 3. Mahomes 32.6K posts
- 4. #TNABoundForGlory 53.8K posts
- 5. #LoveCabin 1,087 posts
- 6. LaPorta 10.5K posts
- 7. #LaGranjaVIP 64.3K posts
- 8. Bryce Miller 4,393 posts
- 9. Red Cross 33.5K posts
- 10. Goff 13.6K posts
- 11. Rod Wave 1,161 posts
- 12. Dan Campbell 3,771 posts
- 13. Kelce 16.3K posts
- 14. #OnePride 6,368 posts
- 15. Binance DEX 5,021 posts
- 16. Butker 8,456 posts
- 17. Mariners 49.1K posts
- 18. #DETvsKC 4,952 posts
- 19. Eitan Mor 5,520 posts
- 20. JuJu Smith 4,240 posts
你可能會喜歡
-
 Symmetry and Geometry in Neural Representations
Symmetry and Geometry in Neural Representations
@neur_reps -
 Danijar Hafner
Danijar Hafner
@danijarh -
 Jascha Sohl-Dickstein
Jascha Sohl-Dickstein
@jaschasd -
 Yi Ma
Yi Ma
@YiMaTweets -
 Ofir Nachum
Ofir Nachum
@ofirnachum -
 ICLR 2026
ICLR 2026
@iclr_conf -
 Jonathan Frankle
Jonathan Frankle
@jefrankle -
 Taco Cohen
Taco Cohen
@TacoCohen -
 Cohere Labs
Cohere Labs
@Cohere_Labs -
 Karol Hausman
Karol Hausman
@hausman_k -
 Miles Cranmer
Miles Cranmer
@MilesCranmer -
 Nathan Lambert
Nathan Lambert
@natolambert -
 Paul Liang
Paul Liang
@pliang279 -
 Johannes Brandstetter
Johannes Brandstetter
@jo_brandstetter -
 Behnam Neyshabur
Behnam Neyshabur
@bneyshabur
Something went wrong.
Something went wrong.