

The 2025 blog post series has begun and we're kicking things off with the "official" Kafka Streams upgrade-guide -- check it out for best practices when setting up a new app, rules for safe vs unsafe upgrades, and tips for making the process go smoothly: responsive.dev/blog/topology-…
responsive.dev
Responsive | Kafka Streams Vault
We're no longer actively developing or maintaining our Kafka Streams content. Visit our GitHub repository for archived blog content.
We are happy to announce that we have completed another SOC2 Type 2 audit along with completing another successful penetration test against our cloud services. You can find the latest reports on our trust center: trust.responsive.dev

(3/3) Application upgrades were by far the #1 requested topic when we asked what the community would like to learn about earlier this year. We hope you find this helpful! responsive.dev/blog/topology-…
responsive.dev
Responsive | Kafka Streams Vault
We're no longer actively developing or maintaining our Kafka Streams content. Visit our GitHub repository for archived blog content.
This will be the foundation for being able to branch @kafkastreams apps to support seamless blue/green deploys. You can also branch a previous version of the state to debug an issue from the past. Powerful stuff coming to the world of stream processing!

SlateDB now has clones 🤯 Clone an existing DB's data to a new location. Clones reference the data from the old bucket rather than copying. Writes to the clone update the new location. Compaction merges old data into new directory./ht @responsive_apps github.com/slatedb/slated…

@kafkastreams had an amazing 2024! Check out @BleeGoldman's year in review, where she recaps the 25 major improvements the community made to Kafka Streams in 2024! responsive.dev/blog/kafka-str…
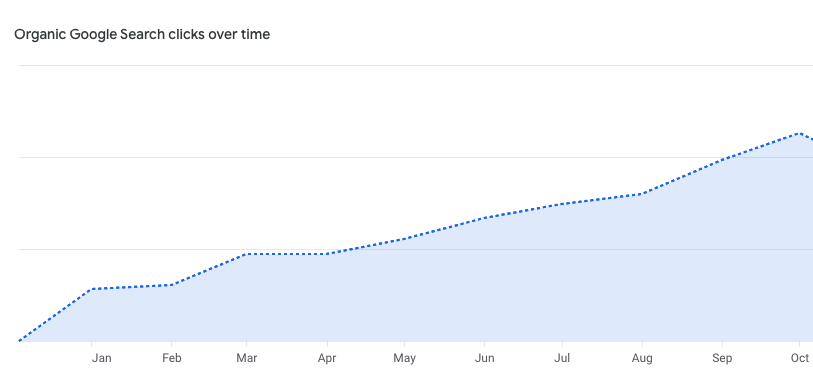
It's remarkable how popular Kafka Streams is. Here's data for people searching for solutions to their Kafka Streams problems and landing on @responsive_apps. That's an up-and-to-the-right chart I love! On that note, what's the best book or blog you've read for optimizing…
Is stream processing interesting because of the new apps it enables, or because it promises better data processing? I'm in the first camp and am proud of the major contributions Responsive has made to the application space. My reflections on what's next responsive.dev/blog/responsiv…
It's said that Silicon Valley is special because the density of smart people leads to chance encounters that don't happen elsewhere. I can attest to that. Here's how a coffee resulted in @responsive_apps building a DB optimized for stream processing in 8 months. (1/n)
Some problems are impossible to solve without stream processing: for instance, did you know that @getmetronome leverages Kafka and @kafkastreams to deliver real time billing features like spend limits at scale? (1/3)
Small feature drop, row-level TTL for Kafka Streams: "The ttl function can use either the key or value, or both, to compute the ttl for that row and override the default ttl. It's also possible to .. only expire specific records." docs.responsive.dev/reference/stor…
Is it end of the road for RocksDB in stream processing? Disaggregated state is the clearly superior architecture, with @responsive_apps investing heavily in SlateDB while Flink 2.0 has forked RocksDB.
Embedding RocksDB in stream processors like Kafka Streams causes a world of operational pain. But that’s not the only reason to drop RocksDB: it was built for local disks and, as Warpstream has shown us, local disks are really expensive in the cloud! 👇🏽 Check out the costs of…
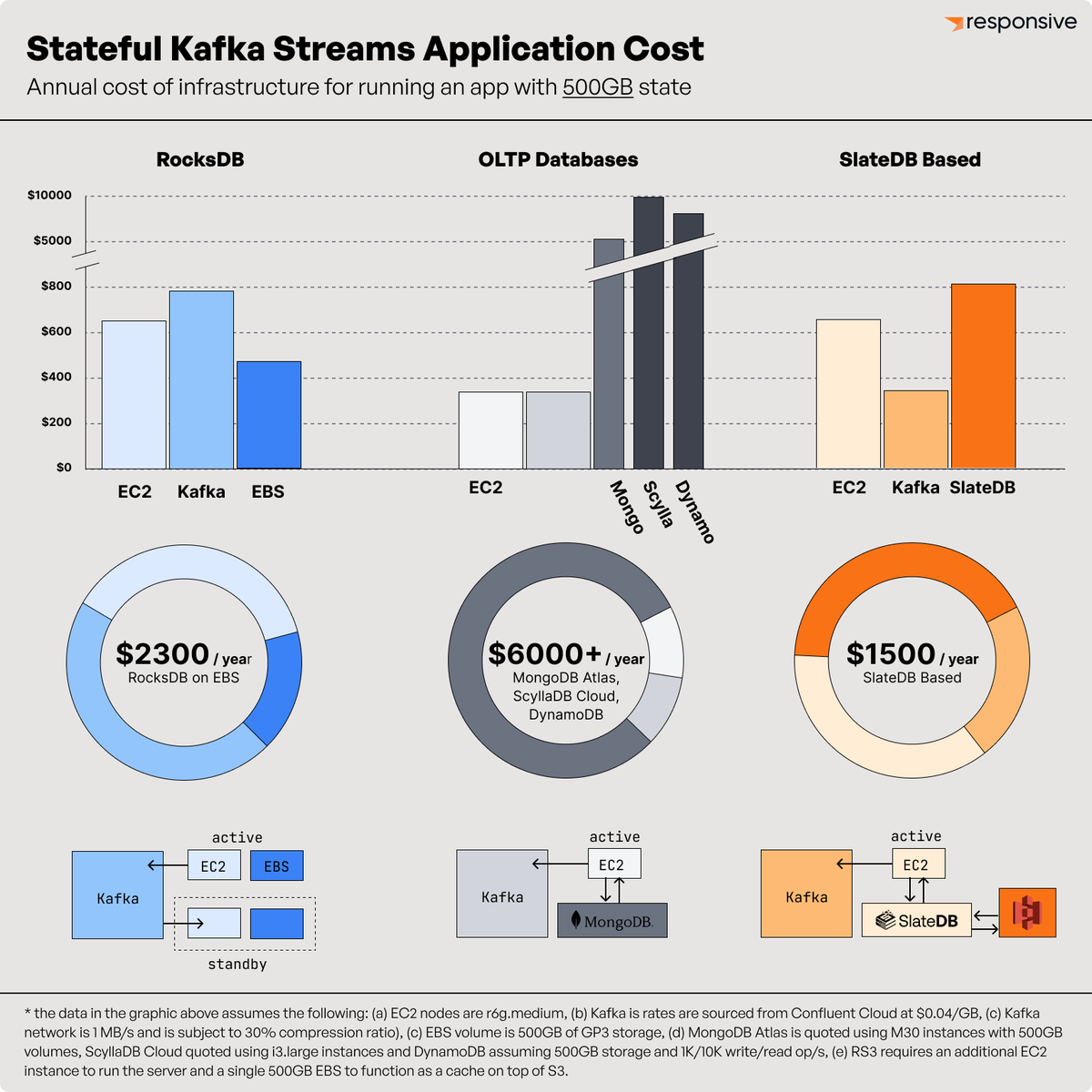
Here’s an interesting fact: around 1/3 of the infrastructure cost of running a stateful Kafka Streams app with RocksDB is writing and reading the changelog topic.
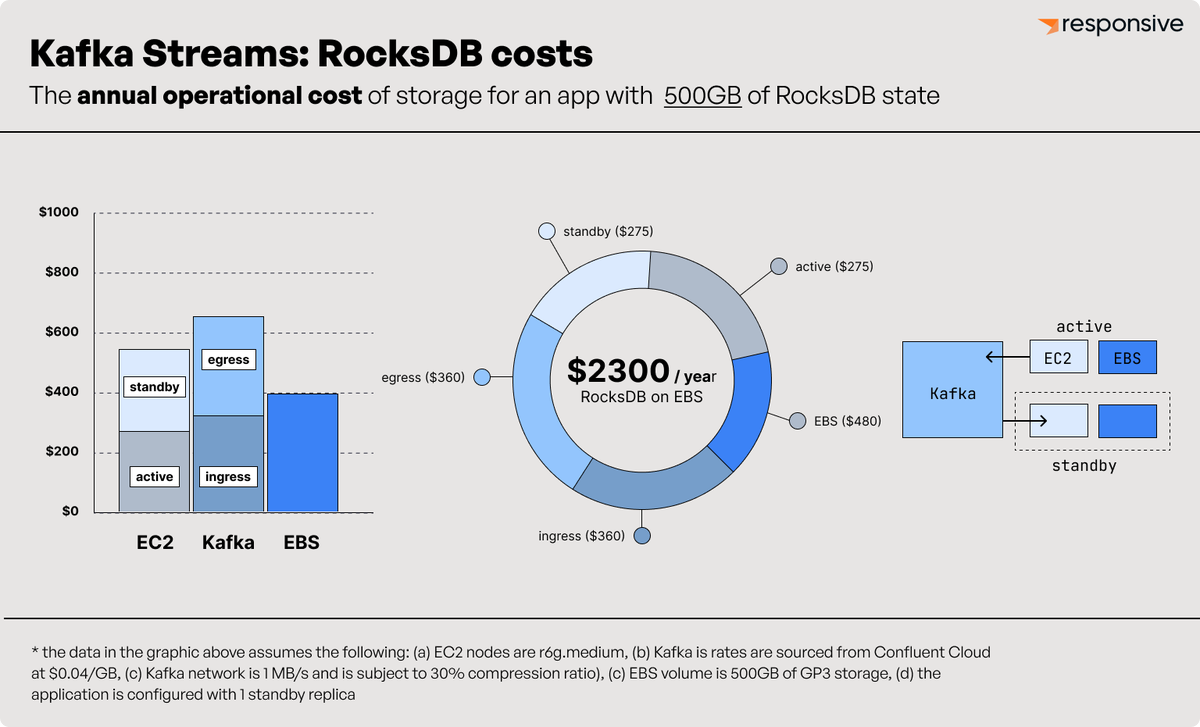
The separation of compute and storage is the hallmark of modern systems, and yet both Kafka Streams and Flink embed RocksDB in their compute nodes. This coupling results in severe operational pain, which I believe has held back the adoption of stream processing in general.
How @responsive_apps async processor redefines the scalability limits of @kafkastreams in 20 seconds

The September edition of #CheckpointChronicle is here! It's packed full of content with links to articles from @responsive_apps, @bbejeck, @vanlightly, @UberEng, Expedia, @github, @AirbnbEng, and more! 👉 dcbl.link/cc-sep241

The recording of my #current2024 talk about redefining the limits of @kafkastreams is available to view. The talk shares a blueprint for achieving 99.99%+ uptime with 100k events/s and terabytes of state for your Kafka Streams applications. 👉current.confluent.io/2024-sessions/…

We are all ready for Current starting tomorrow! Find me and the team at the @responsive_apps booth and learn about all the ways we make your Kafka Streams apps invincible. #current2024






























































































United States 趨勢
- 1. Flacco 64.3K posts
- 2. Bengals 68K posts
- 3. Bengals 68K posts
- 4. Tomlin 16.9K posts
- 5. Ramsey 16.7K posts
- 6. Chase 101K posts
- 7. Chase 101K posts
- 8. #TNFonPrime 4,762 posts
- 9. #WhoDey 5,348 posts
- 10. Teryl Austin 1,919 posts
- 11. #HereWeGo 9,796 posts
- 12. #PITvsCIN 6,210 posts
- 13. Max Scherzer 11.1K posts
- 14. Andrew Berry 2,308 posts
- 15. DK Metcalf 3,654 posts
- 16. Zac Taylor 2,217 posts
- 17. Cuomo 69.5K posts
- 18. Ace Frehley 83.6K posts
- 19. Darnell Washington 2,383 posts
- 20. Joe Burrow 4,255 posts
Something went wrong.
Something went wrong.