
Xin Liu
@sokeyer
Developer, enjoy the life! Machine learning and Large Language Models
You might like









New 3h31m video on YouTube: "Deep Dive into LLMs like ChatGPT" This is a general audience deep dive into the Large Language Model (LLM) AI technology that powers ChatGPT and related products. It is covers the full training stack of how the models are developed, along with mental…

The React, Bun & Hono Tutorial 2024 - Drizzle, Kinde, Tanstack, Tailwind... youtu.be/jXyTIQOfTTk?si… 来自 @YouTube 🥰

youtube.com
YouTube
The React, Bun & Hono Tutorial 2024 - Drizzle, Kinde, Tanstack,...
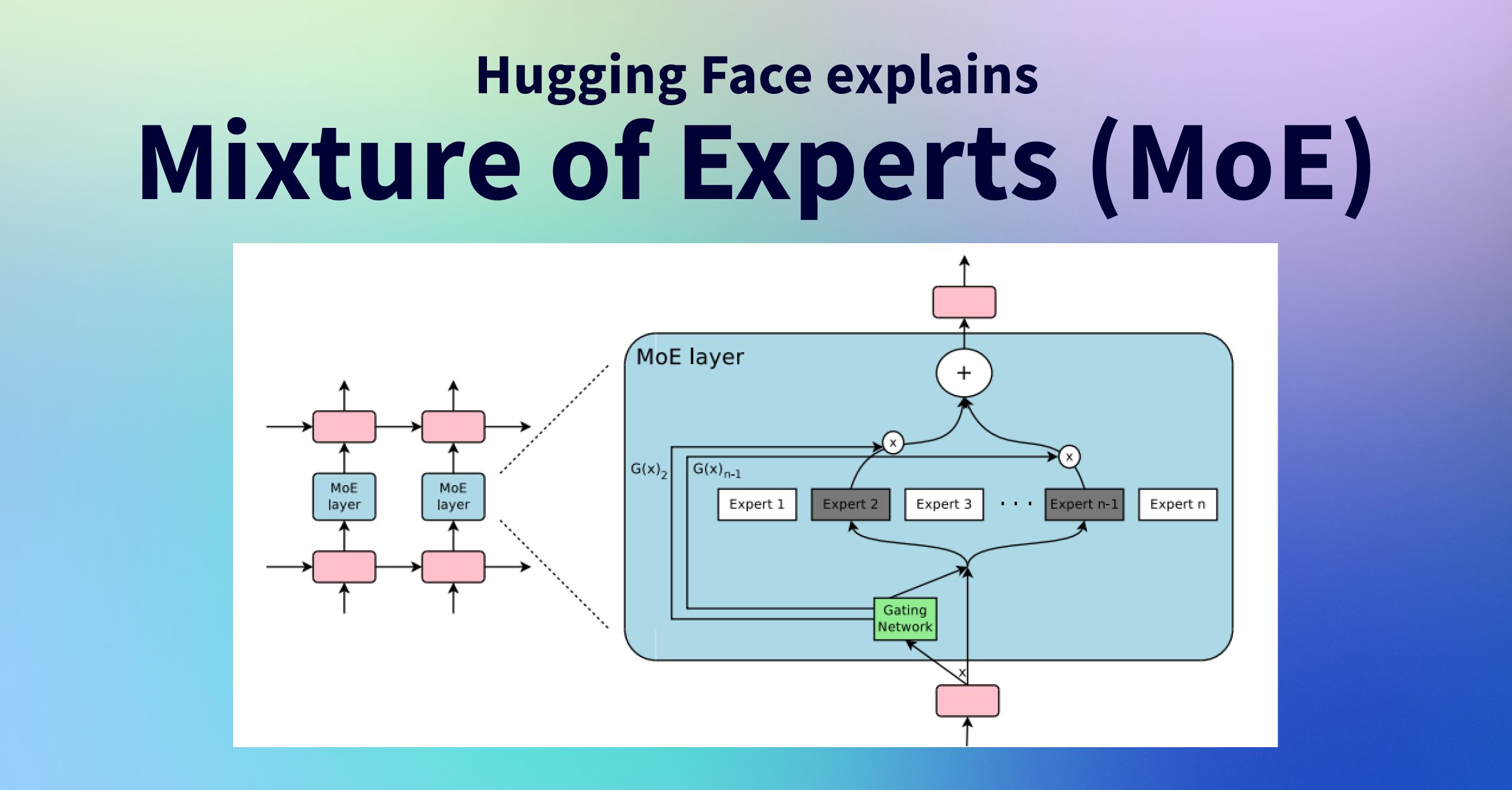
Official post on Mixtral 8x7B: mistral.ai/news/mixtral-o… Official PR into vLLM shows the inference code: github.com/vllm-project/v… New HuggingFace explainer on MoE very nice: huggingface.co/blog/moe In naive decoding, performance of a bit above 70B (Llama 2), at inference speed…

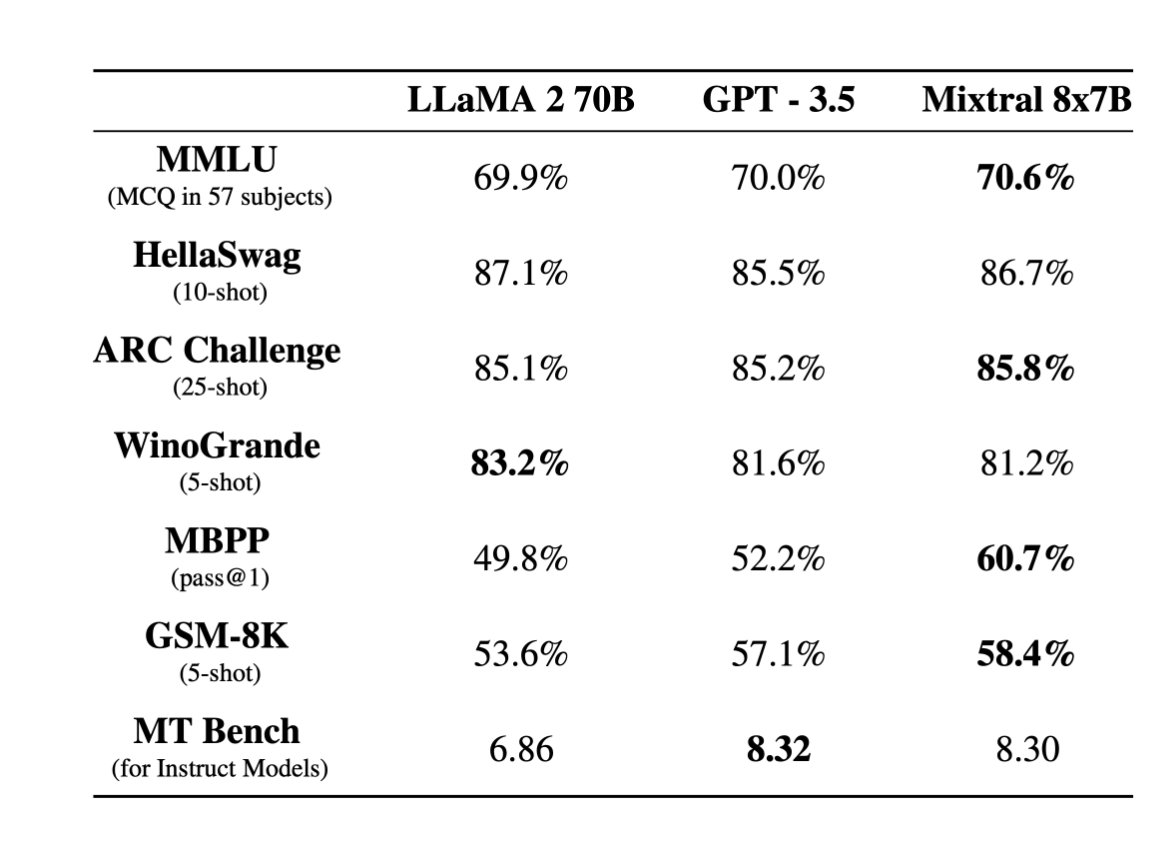
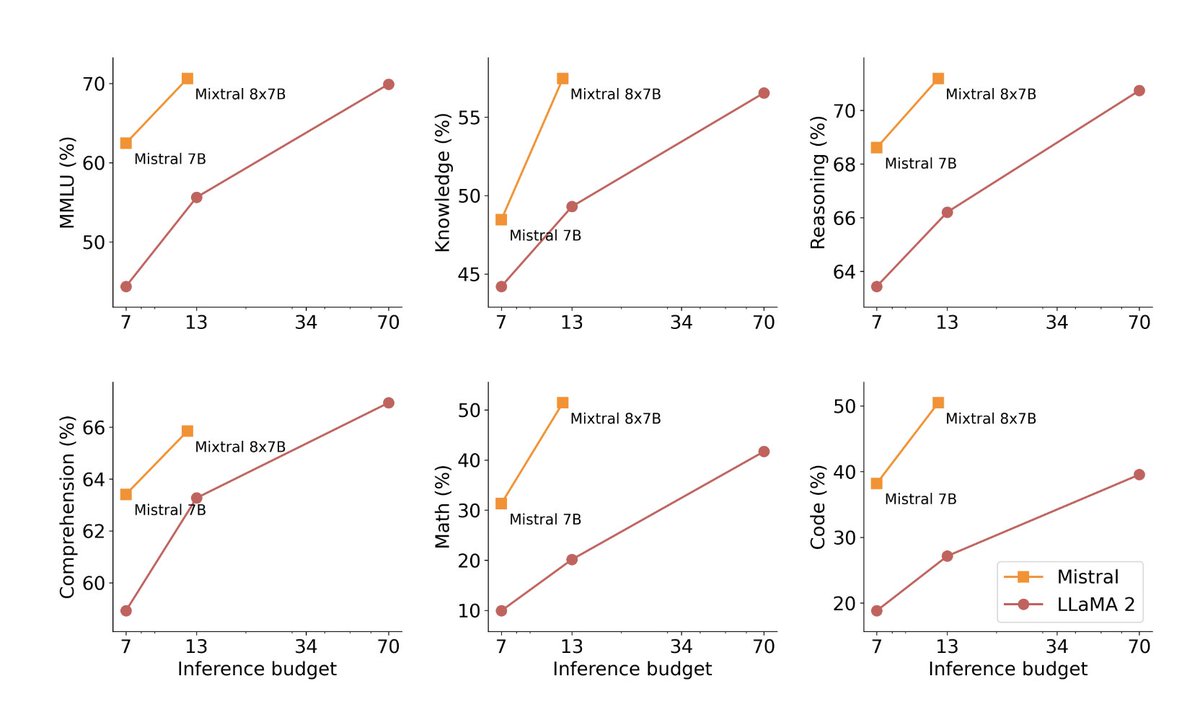
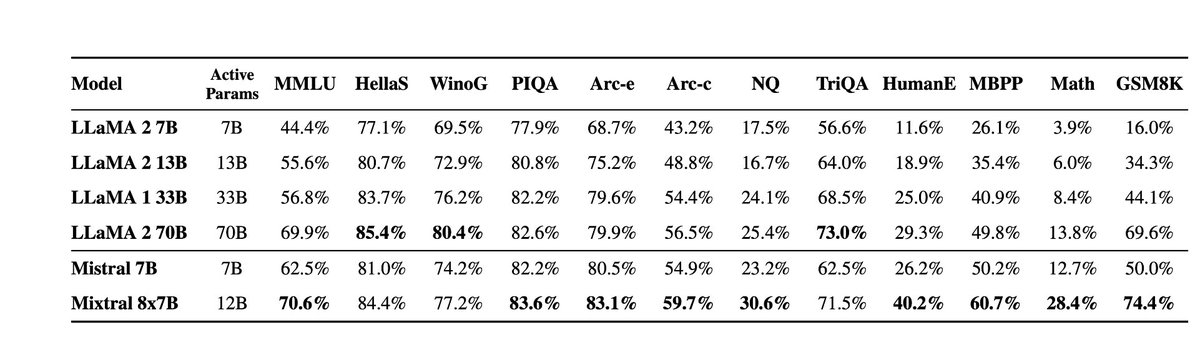
Very excited to release our second model, Mixtral 8x7B, an open weight mixture of experts model. Mixtral matches or outperforms Llama 2 70B and GPT3.5 on most benchmarks, and has the inference speed of a 12B dense model. It supports a context length of 32k tokens. (1/n)
NestJS the Pros and Cons by @bradleybeighton link.medium.com/M9Hrkuv5oGb

Demystifying Domain-Driven Design (DDD) in Modern Software Architecture by @ranjaabhishek blog.bitsrc.io/demystifying-d…


I've found this page on @prisma's #DataGuide useful! prisma.io/dataguide/data…



AI & Machine Learning in Finance: AI Applications in the Financial Indus... youtu.be/AONZoaWC9v4 来自 @YouTube

youtube.com
YouTube
AI & Machine Learning in Finance: AI Applications in the Financial...
『転生したらスライムだった件』OAD gyao.yahoo.co.jp/title/6149a778… #GYAO #GYAOで無料配信中 #リムル #レクリエーション #娯楽

































































































United States Trends
- 1. Good Friday 46.8K posts
- 2. LINGORM DIOR AT MACAU 305K posts
- 3. #ElMundoConVenezuela 1,427 posts
- 4. #TheWorldWithVenezuela 1,485 posts
- 5. #GenshinSpecialProgram 13.8K posts
- 6. #FridayVibes 3,424 posts
- 7. #FridayFeeling 1,812 posts
- 8. Josh Allen 42.5K posts
- 9. RED Friday 1,827 posts
- 10. Happy Friyay N/A
- 11. Texans 61.8K posts
- 12. Parisian 1,448 posts
- 13. Bills 154K posts
- 14. namjoon 64.1K posts
- 15. Niger 57.4K posts
- 16. Sedition 328K posts
- 17. Cole Palmer 15K posts
- 18. Beane 3,092 posts
- 19. Traitor 118K posts
- 20. Commander in Chief 84.7K posts








Something went wrong.
Something went wrong.