
Varun Kumar
@uberkumar
Independent Engineer. When LLMs start to feel things, I’ll know about it
You might like


Manus just blessed me AGAIN They saw how quickly we ran through the first 100 community codes… so they gave me 500 more…. If you missed out on the first round, here’s your chance: 1. Retweet this post 2. Follow 3. DM me “MANUS” If you got the access code in the first…


We might wonder why releasing open-weights for DeepSeek R1 was not a problem, but the data used for training remains closed. Could it be we would see massive amount of both o1-mini and Claude 3.5 Sonnet traces in there? With the data closed, we can only guess.

Born too late for hand-coding Railroad Tycoon in assembly, born too early for not coding at all. Born just in time for writing "You are a helpful AI assistant who only returns RFC-compliant JSON"

Last yr, I personally paid more in taxes than what I made (!!). I was completely shocked - I didn't think it was possible to *owe more* than you make. But it is. To be clear, this post isn't meant to ask for pity, but I think it can help a lot of ppl out. More >>

a single ounce of being honest with ones true motivations can save low self awareness mfs so much heartache

I thought Dune 2 was the best movie of 2024 until I watched this masterpiece (sound on).

Every promotion system has a downside. An example of one not incentivizing this is the founder personally approving/rejecting all promotions, and as the org grows, directors. The downside of this approach is it's full of biases and you need to be on the good side of the founder.
Idea: “startup prison” for those who want to REALLY focus on building. You get a room with a bed, toilet, and desk. Internet is fast. Food is organic, no seed oils. Once a day you get courtyard time to lift and talk shop. Once a week there’s a lame party. Costs 1% equity.

uncle bob has played us for absolute fools

An explosion of complexity often completely unnecessary and unjustified, but the truth is that things are what they are. And in such a context, an idiot who knows everything is a precious ally. -antirez
That it do


I have been testing mistral-medium & GPT-4’s code generation abilities for non-trivial problems. These are problems even experience engineers will take time to work it out. I am summarizing some examples and overall impression in this thread: 🧶

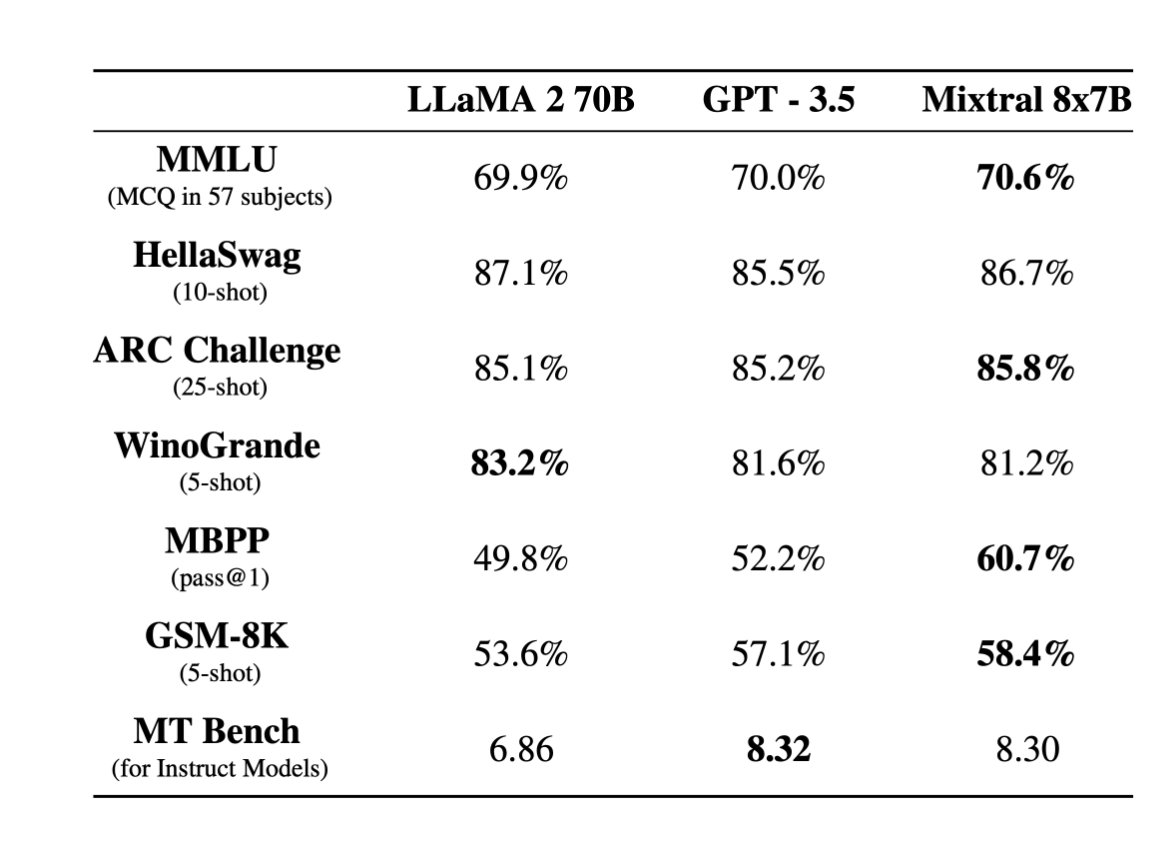
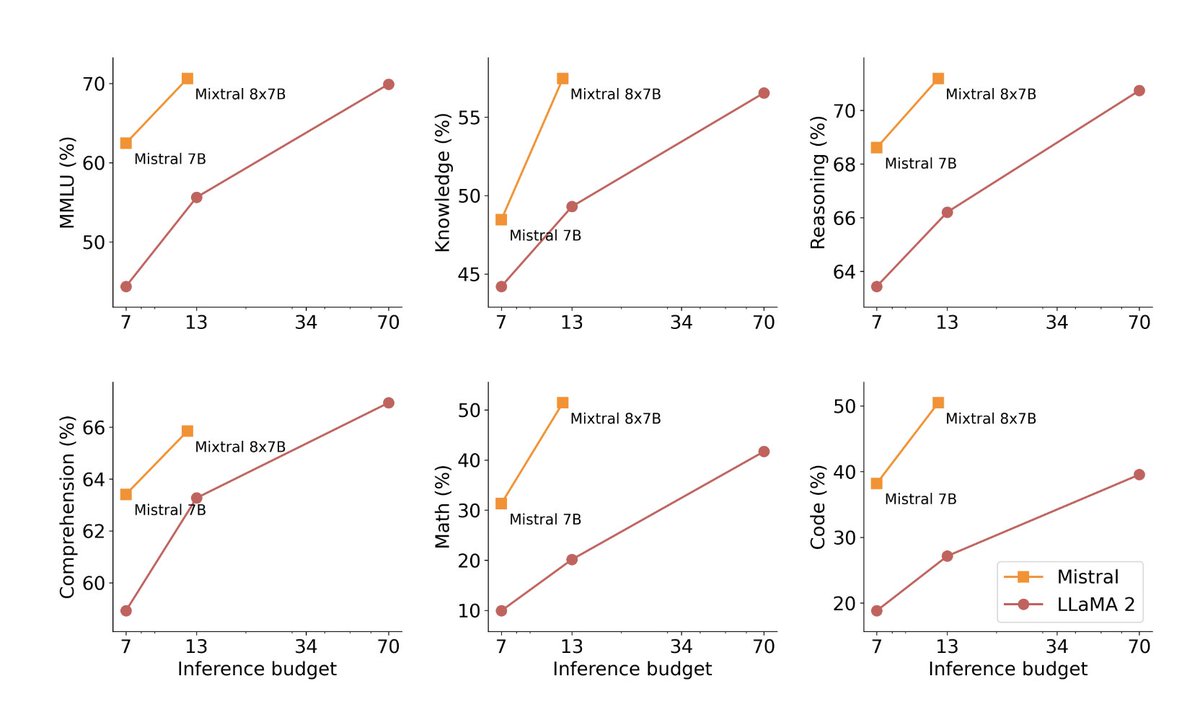
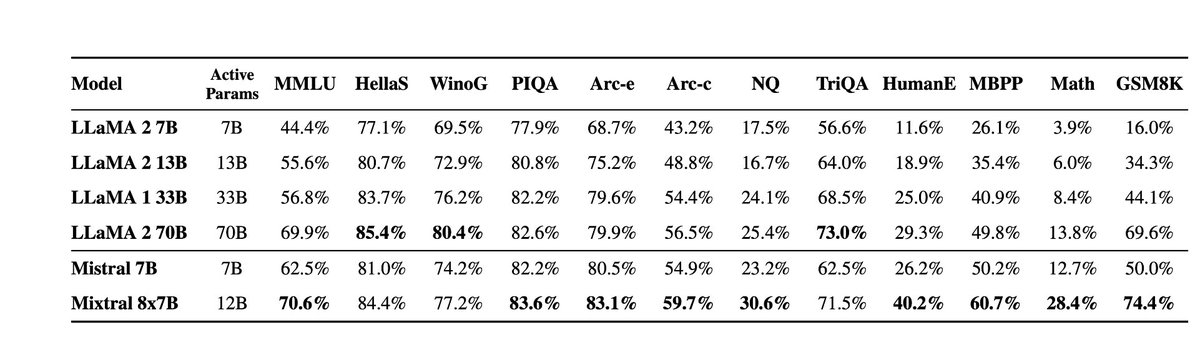
Official post on Mixtral 8x7B: mistral.ai/news/mixtral-o… Official PR into vLLM shows the inference code: github.com/vllm-project/v… New HuggingFace explainer on MoE very nice: huggingface.co/blog/moe In naive decoding, performance of a bit above 70B (Llama 2), at inference speed…


Very excited to release our second model, Mixtral 8x7B, an open weight mixture of experts model. Mixtral matches or outperforms Llama 2 70B and GPT3.5 on most benchmarks, and has the inference speed of a 12B dense model. It supports a context length of 32k tokens. (1/n)
In response to all the recent developments from OpenAI dev day, what is your go to Ui template for prototyping AI chat experiences? I've heard good things from @huggingface's chat-ui. Anyone recommend anything else?

This actually happened to Evernote. They took the advice of “keep talking to your customers and ship whatever they want” as the only guiding principle for product development. And what ended up happening was paying users liked it, but the product become unintuitive and feature…

former gifted kids are now being paid $130k/year to make react components





















































United States Trends
- 1. Giants N/A
- 2. Good Thursday N/A
- 3. #thursdaymotivation N/A
- 4. Insurrection Act in Minnesota N/A
- 5. Monken N/A
- 6. Happy Friday Eve N/A
- 7. #DareYouToDeathEP4 N/A
- 8. #ThursdayThoughts N/A
- 9. Invoke the Insurrection Act N/A
- 10. #thursdayvibes N/A
- 11. National Bagel Day N/A
- 12. Jaxson Dart N/A
- 13. Hobbs N/A
- 14. #NationalHatDay N/A
- 15. NFC East N/A
- 16. Happy Founders N/A
- 17. Todd Bridges N/A
- 18. Big Blue N/A
- 19. Nabers N/A
- 20. Insurrection Act NOW N/A
You might like

Something went wrong.
Something went wrong.