
おすすめツイート















I was curious about the voice agent, particularly its ability for tool-use and reasoning, while listening to a user. So we train voice agents by building a sandbox (based on tau-bench) that uses GPT-4.1 for user simulation and SEED-TTS for speech synthesis. #Agents #ToolUse


I contributed to SeamlessM4T and Seamless Interaction at Meta. I’ve worked on ASR, speech translation, TTS, full-duplex speech LLM, audiovisual, and human motion. Especially, I have expertise in realtime streaming modeling. scholar.google.com/citations?user…

Exploration is fundamental to RL. Yet policy gradient methods often collapse: during training they fail to explore broadly, and converge into narrow, easily exploitable behaviors. The result is poor generalization, limited gains from test-time scaling, and brittleness on tasks…


Most RL for LLMs today is single-step optimization on a given state (e.g., an instruction), which is essentially a bandit setup. But to learn a meta-policy that can solve various bandit problems via in-context trial and error, you need true multi-turn RL over a long horizon. So,…


Making LLMs run efficiently can feel scary, but scaling isn’t magic, it’s math! We wanted to demystify the “systems view” of LLMs and wrote a little textbook called “How To Scale Your Model” which we’re releasing today. 1/n


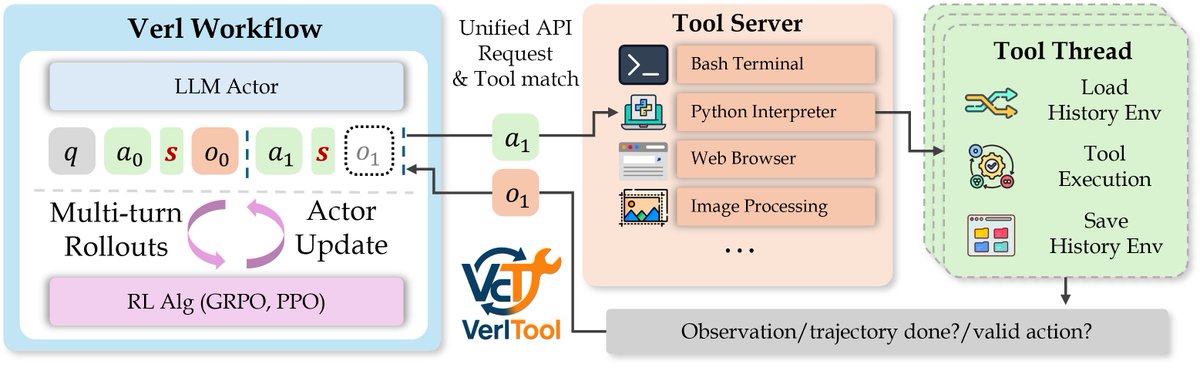
🚀 Excited to finally share our paper on VerlTool, released today after months of work since the initial release in late May! VerlTool is a high-efficiency, easy-to-use framework for Agentic RL with Tool use (ARLT), built on top of VeRL. It currently supports a wide range of…

Introducing VerlTool - a unified and easy-to-extend tool agent training framework based on verl. Recently, there's been a growing trend toward training tool agents with reinforcement learning algorithms like GRPO and PPO. Representative works include SearchR1, ToRL, ReTool, and…

🌀Diversity Aware RL (DARLING)🌀 📝: arxiv.org/abs/2509.02534 - Jointly optimizes for quality & diversity using a learned partition function - Outperforms standard RL in quality AND diversity metrics, e.g. higher pass@1/p@k - Works for both non-verifiable & verifiable tasks 🧵1/5


Our latest on compressed representations: Key-Value Distillation (KVD). Query-independen transformer compression, with offline supervised distillation.


🛠️ DeepSeek-R1: Technical Highlights 📈 Large-scale RL in post-training 🏆 Significant performance boost with minimal labeled data 🔢 Math, code, and reasoning tasks on par with OpenAI-o1 📄 More details: github.com/deepseek-ai/De… 🐋 4/n


Congratulations to Prof. Philipp Koehn on being named a Fellow of the @aclmeeting! cs.jhu.edu/news/philipp-k…

I had a great time helping host MASC-SLL at Hopkins last year. MASC-SLL is a great opportunity to connect with fellow AI/NLP/Speech researchers. If your organization is in the Mid-Atlantic region and is interested in hosting the event, please reach out!

📢 Want to host MASC 2025? The 12th Mid-Atlantic Student Colloquium is a one day event bringing together students, faculty and researchers from universities/industry in the Mid-Atlantic. Please submit this very short form if you are interested in hosting! Deadline January 6th

I have written a blogpost offering an explanation of why both the chosen and the rejected log-probability decreases during DPO, and more interestingly, why it is a desired phenomenon to some extent. Link: tianjianl.github.io/blog/2024/dpo/

Very happy to hear that GANs are getting the test of time award at NeurIPS 2024. The NeurIPS test of time awards are given to papers which have stood the test of the time for a decade. I took some time to reminisce how GANs came about and how AI has evolve in the last decade.
Excited to see that SpiritLM is fully open-sourced now. It supports speech and text as both input and output. Please consider trying it at: github.com/facebookresear…


Open science is how we continue to push technology forward and today at Meta FAIR we’re sharing eight new AI research artifacts including new models, datasets and code to inspire innovation in the community. More in the video from @jpineau1. This work is another important step…





















































































United States トレンド
- 1. Cuomo 115K posts
- 2. Koa Peat N/A
- 3. #OlandriaxCFDAAwards 5,820 posts
- 4. Cowboys 29.3K posts
- 5. Caleb Wilson N/A
- 6. Walt Weiss 2,674 posts
- 7. Harvey Weinstein 7,973 posts
- 8. Cardinals 15.6K posts
- 9. Monday Night Football 7,774 posts
- 10. Braves 12K posts
- 11. Teen Vogue 4,434 posts
- 12. Arizona 30.9K posts
- 13. Schwab 5,693 posts
- 14. Hamburger Helper 2,811 posts
- 15. Diane Ladd 6,407 posts
- 16. Snit N/A
- 17. Myles Turner 1,597 posts
- 18. Ben Shapiro 39.1K posts
- 19. $PLTR 20.6K posts
- 20. McBride 4,503 posts
おすすめツイート
-
 Neha Verma
Neha Verma
@n_verma1 -
 Kate Sanders
Kate Sanders
@kesnet50 -
 Aaron Mueller
Aaron Mueller
@amuuueller -
 Boyuan Zheng@ICML
Boyuan Zheng@ICML
@boyuan__zheng -
 Stella Li
Stella Li
@StellaLisy -
 Shramay Palta
Shramay Palta
@PaltaShramay -
 CLS
CLS
@ChengleiSi -
 Alexandra DeLucia
Alexandra DeLucia
@Alexir563 -
 Suzanna Sia
Suzanna Sia
@suzyahyah -
 Marc Marone
Marc Marone
@ruyimarone -
 maieutic
maieutic
@maieuticlab -
 Elias Stengel-Eskin
Elias Stengel-Eskin
@EliasEskin -
 Ziyang Wang
Ziyang Wang
@ZiyangW00 -
 Vijay Murari Tiyyala
Vijay Murari Tiyyala
@VijayTiyyala -
 Abe Hou
Abe Hou
@abe_hou
Something went wrong.
Something went wrong.