
Wenjie Zheng
@wjzheng_nlp
PhD student | Interested in Multimodal Learning | Feel free to connect me. 🧸
You might like









🚨New paper!🚨 Still worried about the low quality of your rule-cleaned pre-training corpora? Try 🫐 ProX! 1. Dramatically boosts pre-training corpus quality with a language model that generates executable programs. 2. A 1.7B model, trained on corpus refined by 🫐 ProX with…


🚀 Still relying on human-crafted rules to improve pretraining data? Time to try Programming Every Example(ProX)! Our latest efforts use LMs to refine data with unprecedented accuracy, and brings up to 20x faster training in general and math domain! 👇 Curious about the details?

[CV] CinePile: A Long Video Question Answering Dataset and Benchmark arxiv.org/abs/2405.08813 - The paper introduces CinePile, a large-scale video question answering dataset with ~305k questions covering temporal comprehension, human-object interactions, reasoning about…
![fly51fly's tweet image. [CV] CinePile: A Long Video Question Answering Dataset and Benchmark
arxiv.org/abs/2405.08813
- The paper introduces CinePile, a large-scale video question answering dataset with ~305k questions covering temporal comprehension, human-object interactions, reasoning about…](https://pbs.twimg.com/media/GNpxKofaQAEjNsK.jpg)
![fly51fly's tweet image. [CV] CinePile: A Long Video Question Answering Dataset and Benchmark
arxiv.org/abs/2405.08813
- The paper introduces CinePile, a large-scale video question answering dataset with ~305k questions covering temporal comprehension, human-object interactions, reasoning about…](https://pbs.twimg.com/media/GNpxKoda0AEGzzn.jpg)
![fly51fly's tweet image. [CV] CinePile: A Long Video Question Answering Dataset and Benchmark
arxiv.org/abs/2405.08813
- The paper introduces CinePile, a large-scale video question answering dataset with ~305k questions covering temporal comprehension, human-object interactions, reasoning about…](https://pbs.twimg.com/media/GNpxK-QaQAAqEYq.jpg)
work full of sincerity, welcome everyone to follow. 🥳🥳🥳

🎉🎉🎉So happy to announce that our paper "Ask Again, Then Fail: Large Language Models' Vacillations in Judgement"(w/@SinclairWang1) arxiv.org/abs/2310.02174 was accepted to #ACL2024 main! Here's a quick overview: 👇🧵

Excited to share our #ACL2024 Findings paper "EmpathicStories++: A Multimodal Dataset for Empathy towards Personal Experiences" 🧵(1/7) Dataset request: mitmedialab.github.io/empathic-stori…


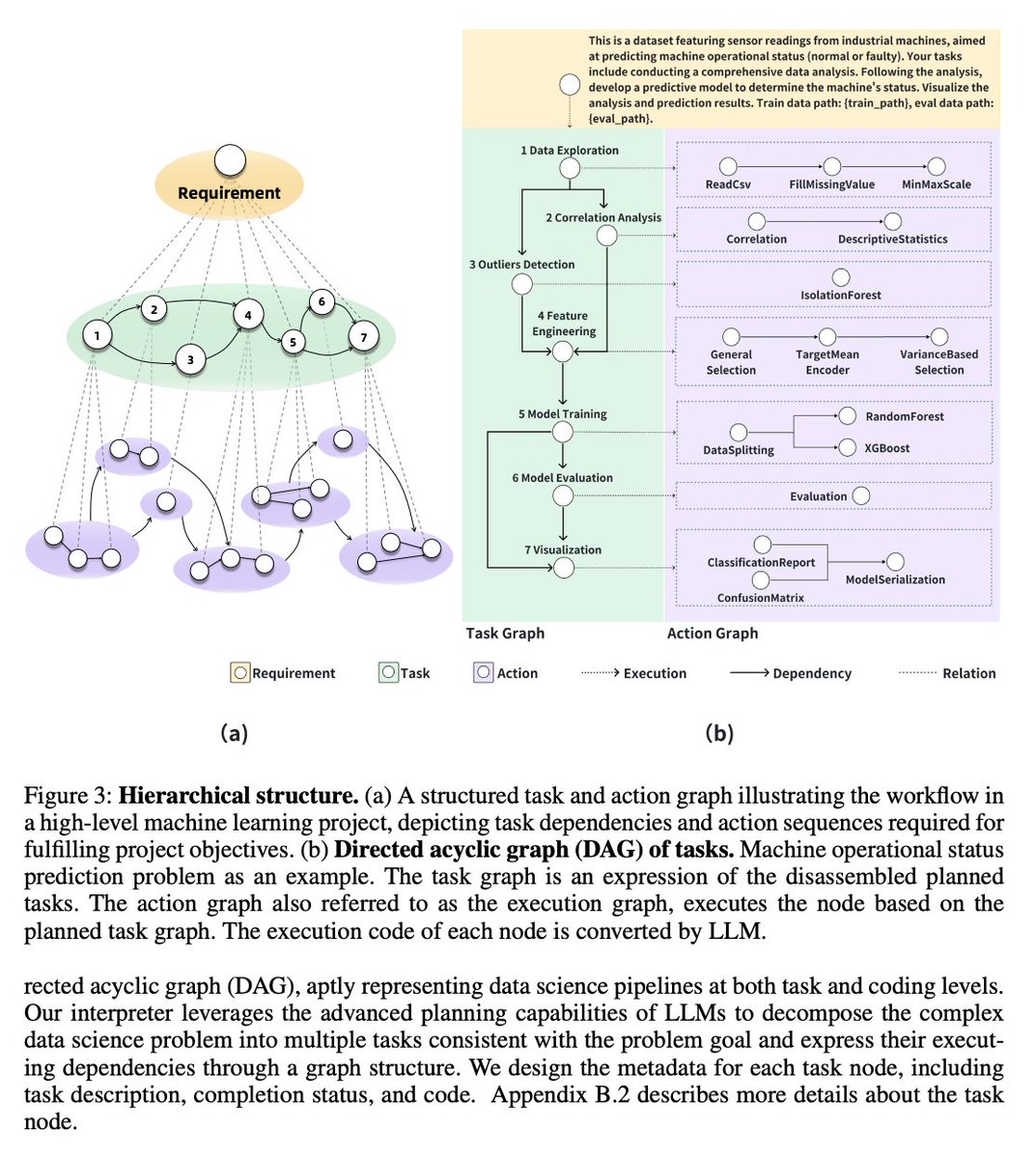
Introducing MetaGPT's Data Interpreter: Open Source and Better "Devin". Data Interpreter has achieved state-of-the-art scores in machine learning, mathematical reasoning, and open-ended tasks, and can analyze stocks, imitate websites, and train models. Data Interpreter is an…




A Survey on Data Selection for Language Models Presents a comprehensive review of existing literature on data selection methods and related research areas, providing a taxonomy of existing approaches arxiv.org/abs/2402.16827


🔴 stream: YOLO-World Q&A + coding in less than 15 minutes, I start my first YT stream; I'll be talking about YOLO-World and answering your questions that you left under my last YT video stop by to say hello link: youtube.com/live/lF1BtQL16… ↓ some of the topics we will cover
Thrilled to release our new version (v0.2) of MathPile, a cleaner version through our efforts to fix some issues!🥳 More importantly, we also released commercial-use version, namely MathPile_Commercial(huggingface.co/datasets/GAIR/…)🥳🥳🥳

Generative AI for Math: MathPile Presents a diverse and high-quality math-centric corpus comprising about 9.5B tokens proj: gair-nlp.github.io/MathPile/ repo: github.com/GAIR-NLP/MathP… abs: arxiv.org/abs/2312.17120


Quadratic attention has been indispensable for information-dense modalities such as language... until now. Announcing Mamba: a new SSM arch. that has linear-time scaling, ultra long context, and most importantly--outperforms Transformers everywhere we've tried. With @tri_dao 1/


A team just made OpenAI Whisper 6x faster, 49% smaller, while keeping 99% of the accuracy. The model is already available on the HuggingFace Transformers library: model_id = "distil-whisper/distil-large-v2" You can also use their web UI to transcribe from URLs, files, or…

How to #RLHF for LLMs: #PPO or #DPO? Introducing #BPO (black-box prompt optimization) to align LLMs without model training. 1) ChatGPT + BPO > ChatGPT 2) GPT-4 + BPO > GPT-4 3) Vicuna + BPO > Vicuna + PPO/DPO 4) Vicuna + DPO + BPO > Vicuna + DPO arxiv.org/pdf/2311.04155…


mPLUG-Owl2: Revolutionizing Multi-modal Large Language Model with Modality Collaboration paper page: huggingface.co/papers/2311.04… Multi-modal Large Language Models (MLLMs) have demonstrated impressive instruction abilities across various open-ended tasks. However, previous methods…

TEAL: Tokenize and Embed ALL for Multi-modal Large Language Models paper page: huggingface.co/papers/2311.04… Despite Multi-modal Large Language Models (MM-LLMs) have made exciting strides recently, they are still struggling to efficiently model the interactions among multi-modal…


🚨 Unveiling GPT-4V(ision)'s mind! We're breaking down how even the brightest Visual Language Models get it wrong! With our new 'Bingo' benchmark, we shed light on the two common types of hallucinations in GPT-4V(ision): bias and interference. Led by @cuichenhang @AiYiyangZ

CogVLM: Visual Expert for Pretrained Language Models paper page: huggingface.co/papers/2311.03… introduce CogVLM, a powerful open-source visual language foundation model. Different from the popular shallow alignment method which maps image features into the input space of language…

OtterHD: A High-Resolution Multi-modality Model paper page: huggingface.co/papers/2311.04… present OtterHD-8B, an innovative multimodal model evolved from Fuyu-8B, specifically engineered to interpret high-resolution visual inputs with granular precision. Unlike conventional models…


We're rolling out new features and improvements that developers have been asking for: 1. Our new model GPT-4 Turbo supports 128K context and has fresher knowledge than GPT-4. Its input and output tokens are respectively 3× and 2× less expensive than GPT-4. It’s available now to…
FlashDecoding++: Faster Large Language Model Inference on GPUs paper page: huggingface.co/papers/2311.01… As the Large Language Model (LLM) becomes increasingly important in various domains. However, the following challenges still remain unsolved in accelerating LLM inference: (1)…

LLaVA-Interactive: An All-in-One Demo for Image Chat, Segmentation, Generation and Editing paper page: huggingface.co/papers/2311.00… LLaVA-Interactive is a research prototype for multimodal human-AI interaction. The system can have multi-turn dialogues with human users by taking…

MM-VID: Advancing Video Understanding with GPT-4V(ision) paper page: huggingface.co/papers/2310.19… present MM-VID, an integrated system that harnesses the capabilities of GPT-4V, combined with specialized tools in vision, audio, and speech, to facilitate advanced video understanding.…































































United States Trends
- 1. Bills 125K posts
- 2. Giants 54.4K posts
- 3. Josh Allen 12.1K posts
- 4. Dolphins 27.5K posts
- 5. Henderson 12.7K posts
- 6. Browns 30.8K posts
- 7. Caleb Williams 5,419 posts
- 8. Bears 48.3K posts
- 9. Dart 20.6K posts
- 10. Patriots 87.7K posts
- 11. Drake Maye 11.7K posts
- 12. Ravens 29.9K posts
- 13. Bryce 13.6K posts
- 14. Russell Wilson 2,064 posts
- 15. Saints 31K posts
- 16. Daboll 3,993 posts
- 17. Vikings 25.4K posts
- 18. Pats 11.3K posts
- 19. JJ McCarthy 3,300 posts
- 20. Beane 4,673 posts








Something went wrong.
Something went wrong.