
Zack Li-Nexa AI
@zacklearner
Co-founder and CTO at Nexa AI, Industrial Veteran from Google & Amazon, and Stanford alumni. Committed to lifelong learning and advancing AI technology.
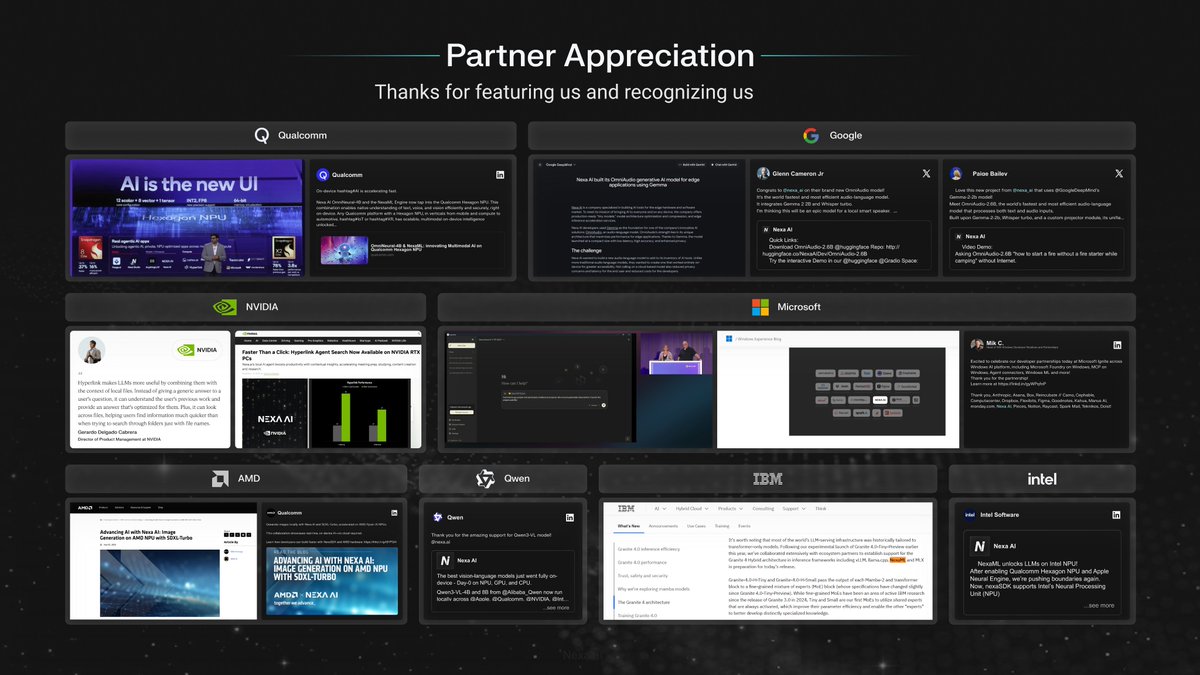
Huge appreciation to our partners from @Microsoft @GoogleDeepMind @Qualcomm @NVIDIA @IBM @AMD @Intel @Qwen and so many others who featured us on stages, blogs, and launches!

Happy Thanksgiving! This year has been wild in the best way — builders across X, Reddit, LinkedIn, Slack, and Discord pushed us, roasted us, inspired us, and ultimately helped shape NexaSDK and Hyperlink into what they are today. We read every comment, every benchmark, every…


gpt-oss-20b running on Hexagon NPU via Nexa SDK 🔥
Finally, the GPT-OSS-20B now runs fully local on the @Qualcomm Hexagon NPU via NexaSDK, powered by the NexaML engine — available today exclusively in Hyperlink Pro as an NPU-only feature. With a single line of code, OEMs can ship ChatGPT-class intelligence at laptop power…
More SOTA models just landed in NexaSDK Android — all running natively on the @Qualcomm Hexagon NPU with one line of code. ⚡️ Granite-350M (@IBM): ultra-light for instant intents, commands, and offline assistants. Granite-4.0-Micro 3B (@IBM): compact reasoning for richer agents…
Nexa AI is a featured partner at @Microsoft Ignite 2025 — highlighted in the official Microsoft blog and live on the floor this week. We’re also demoing at the @Qualcomm booth, showing what’s now possible with on-device AI agents powered by our NexaSDK and Hyperlink Agent.…




Ok… Hyperlink’s launch blew up way beyond what we expected. In the last 24 hours, we crossed 1.6M views, 6.4K likes, received recognition from industry leaders, and saw a ton of love from the community. We built Hyperlink to make your computer truly intelligent — an on-device…

Thanks @nvidia @NVIDIA_AI_PC for promoting our Hyperlink product!

Your local AI agent, upgraded. @Nexa_ai's Hyperlink is accelerated by RTX AI PCs allowing for scans of gigabytes of local files in minutes — fast, private, and all on your device. Get started today #RTXAIGarage 👉 nvda.ws/3LSZDYA

Meet Hyperlink, the first AI super assistant that lives inside your computer. Your computer stores all your files and personal context. Hyperlink deeply understands them and gives cited answers instantly — like Perplexity for your local files. It turns your computer into a true…
Following the launch of the Nexa Android SDK, we ran a 10-minute LLM stress test on the Samsung S25 Ultra with Qualcomm Hexagon NPU: ⚙️ CPU: throttled from ~37 t/s → ~19 t/s at 42 °C ⚙️ NPU (Qualcomm Hexagon): held steady at ~90 t/s and 36–38 °C — 2–4× faster under load 🔋 Both…

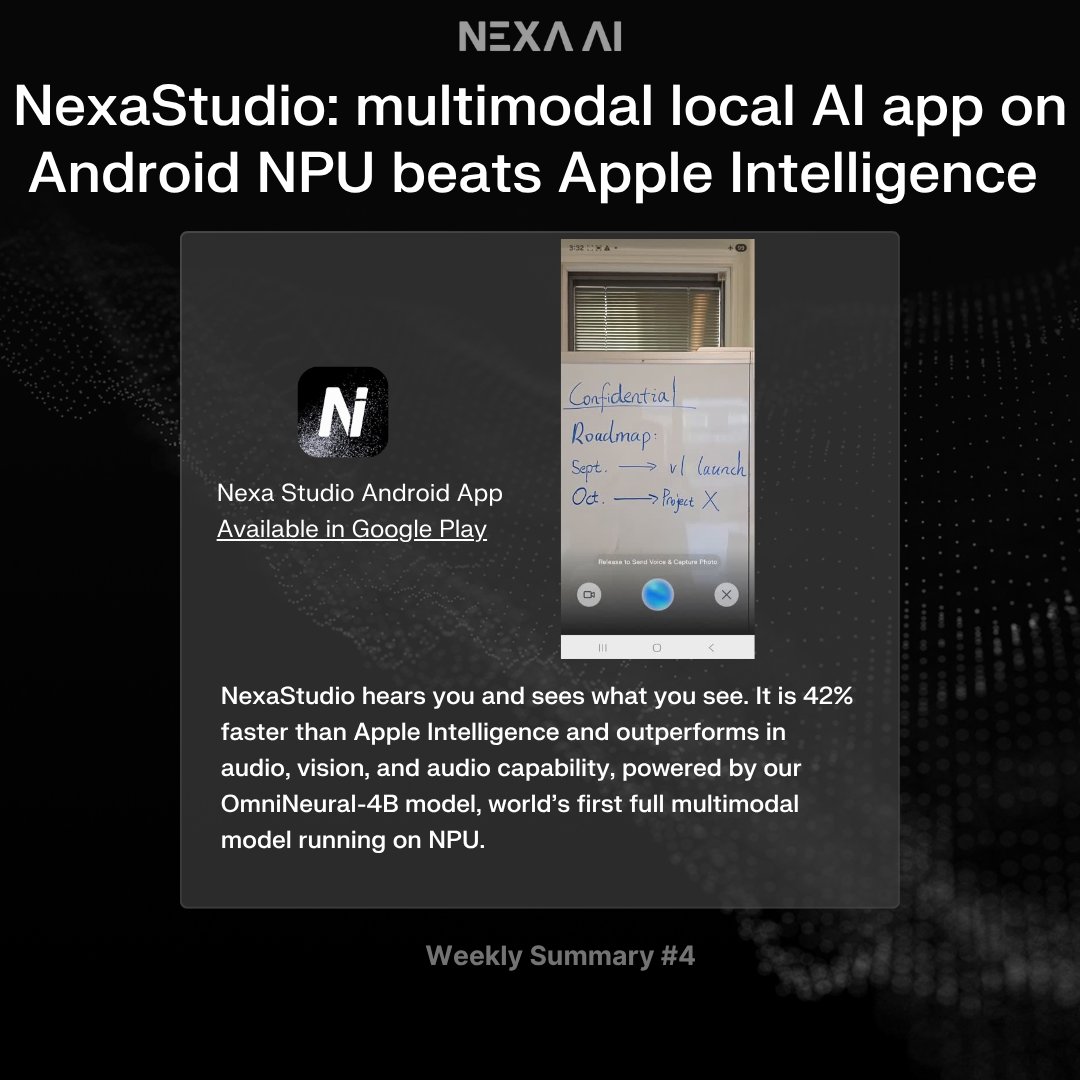
This Week at Nexa 🚀 — VLA model on IoT & Robotics NPU, Nexa Android SDK, and NexaStudio app that beats Apple Intelligence 1) World’s first vision-language-action model running locally on NPU (Robotics + IoT) with NexaML @huggingface’s SmolVLA now runs fully on the @Qualcomm…



Today, we’re launching Android Java & Kotlin support for NexaSDK (Beta) — bringing the full power of on-device AI to billions @Android phones powered by @Qualcomm @Snapdragon chipsets. This is a major leap forward for the world’s largest mobile developer community: ✅ Seamless…
Our work on NPU-accelerated inference for SDXL-Turbo has been featured by AMD on their official blog. We also have been invited to the PyTorch Conference with AMD. Try it out on your AMD laptop: nexa infer NexaAI/sdxl-turbo-amd-npu
LFM2-1.2B models from Liquid AI are now running fully accelerated on Qualcomm NPUs via the NexaML engine — real-time performance with minimal memory use, right on the edge. Four new variants power everything from chat to document parsing: 💬 LFM2-1.2B – general chat & reasoning…

LFM2-1.2B models from @LiquidAI_ are now running on @Qualcomm NPU in NexaSDK, powered by NexaML engine. Four new edge-ready variants: - LFM2-1.2B — general chat and reasoning - LFM2-1.2B-RAG — retrieval-augmented local chat - LFM2-1.2B-Tool — structured tool calling and agent…
NVIDIA sent us a 5090 so we can demo Qwen3-VL 4B & 8B GGUF. You can now run it in our desktop UI, Hyperlink, powered by NexaML Engine — the first and only framework that supports Qwen3-VL GGUF right now. We tried the same demo examples from the Qwen2.5-32B blog — the new…
🚀 we’ve achieved Day-0 full-platform inference support for Qwen3-VL-4B! From NPU to GPU to CPU, across Qualcomm, Apple, AMD, Intel, MediaTek, and NVIDIA, you can now run the latest multimodal model locally, natively, and at full speed — all powered by NexaSDK. This breakthrough…

We have provided day-0 support to run Qwen3-VL on NPU / GPU / CPU, try it here: huggingface.co/collections/Ne…


Introducing the compact, dense versions of Qwen3-VL — now available in 4B and 8B pairs, each with both Instruct and Thinking variants. ✅ Lower VRAM usage ✅ Full Qwen3-VL capabilities retained ✅ Strong performance across the board Despite their size, they outperform models…

Thanks @simonw for mentioning our work! We continue to compress and prune gpt-oss such that it can fit in latest iPhone. More exciting updates to come soon!

TIL you can run GPT-OSS 20B on a phone! This is on Snapdragon phones with 16GB or more of GPU-accessible memory - I didn't realize they had the same unified CPU-GPU memory trick that Apple Silicon has (The largest iPhone 17 still maxes out at 12GB, so not enough RAM to run…
Thrilled to speak and demo at @IBM #TechXchange in Orlando this week! @alanzhuly shared how we’re advancing the frontier of on-device AI — showcasing: ⚡ IBM Granite 4.0 running lightning-fast on @Qualcomm NPU — the first Day-0 model support in NPU history. 💻 Hyperlink, the…

Sam Altman recently said: “GPT-OSS has strong real-world performance comparable to o4-mini—and you can run it locally on your phone.” Many believed running a 20B-parameter model on mobile devices was still years away. At Nexa AI, we’ve built our foundation on deep on-device AI…































































































United States Trends
- 1. Florida 92.6K posts
- 2. Good Saturday 25.8K posts
- 3. Texas 160K posts
- 4. #SmallBusinessSaturday N/A
- 5. #MeAndTheeSeriesEP3 465K posts
- 6. #SaturdayVibes 2,811 posts
- 7. #JimmySeaFanconD1 679K posts
- 8. #BINIFIED 254K posts
- 9. Go Blue 5,659 posts
- 10. Buckeyes 3,104 posts
- 11. UTEP N/A
- 12. Sam Houston N/A
- 13. Go Bucks 1,527 posts
- 14. Black Sea 16.5K posts
- 15. Miss St 2,058 posts
- 16. hanbin 28.6K posts
- 17. Domain For Sale 22.6K posts
- 18. Kentucky and Mississippi State N/A
- 19. Katie Miller 3,980 posts
- 20. Sark 5,816 posts
Something went wrong.
Something went wrong.