
Jianwei Yang
@jw2yang4ai
RS @Meta SuperIntelligence Lab; ex-MSR; Core contributor of Project Florence, Phi-3V, Omniparser; (Co-)Inventor of FocalNet, SEEM, SoM, DeepStack and Magma.
قد يعجبك















Life Update: Now that I have finished the presentation of last @MSFTResearch project Magma at @CVPR, I am excited to share that I have joined @AIatMeta as a research scientist to further push forward the boundary of multimodal foundation models! I have always been passionate…


To thrive in the industry, you must let go of your past work and quickly adapt to the latest trends that companies are investing in. This mindset stands in stark contrast to academia, where originality and perseverance are deeply valued...
🚀Excited to see Qwen3-VL released as the new SOTA open-source vision-language model! What makes it extra special is that it’s powered by DeepStack, a technique I co-developed with Lingchen, who is now a core contributor of Qwen3-VL. When Lingchen and I developed this technique…

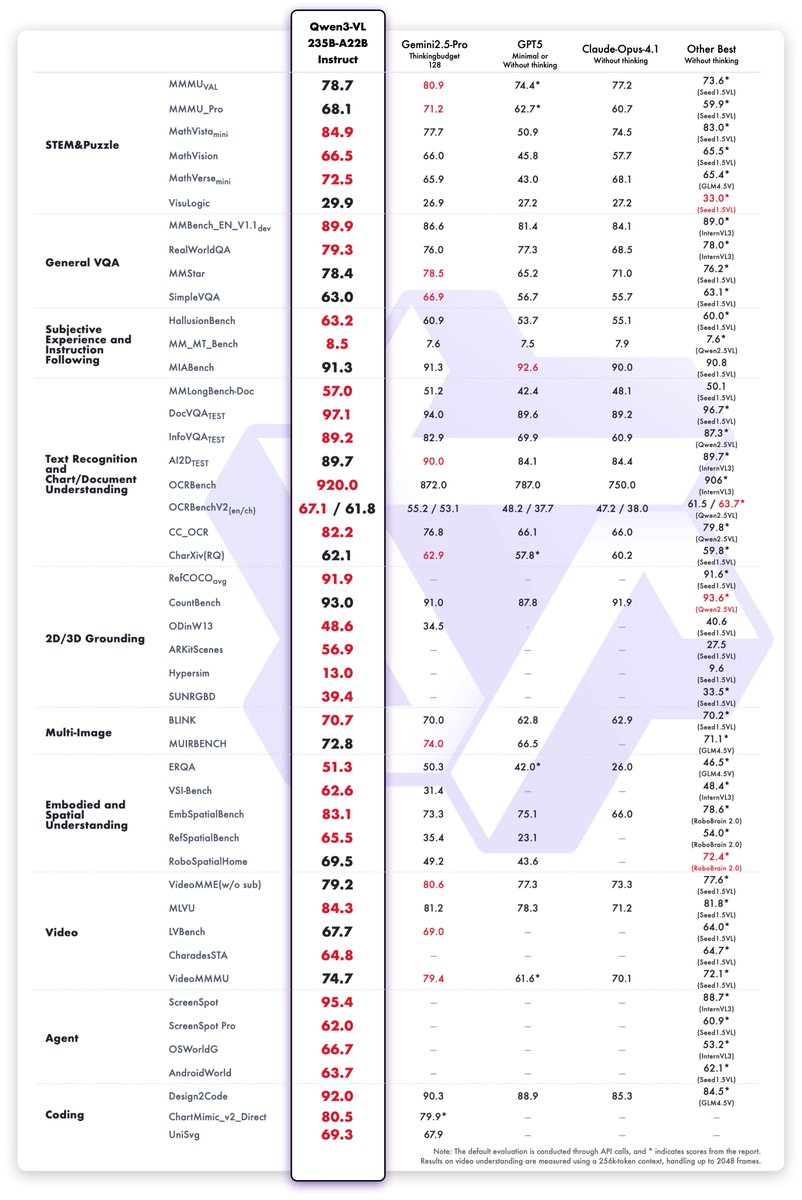
🚀 We're thrilled to unveil Qwen3-VL — the most powerful vision-language model in the Qwen series yet! 🔥 The flagship model Qwen3-VL-235B-A22B is now open-sourced and available in both Instruct and Thinking versions: ✅ Instruct outperforms Gemini 2.5 Pro on key vision…
Great work! Building a coherent representation for the complicated world - visual and semantic, 2D and 3D, spatial and temporal, is challenging but critical. Having a single tokenizer for all is definitely a great step stone to next generation of multimodal models!

Vision tokenizers are stuck in 2020🤔while language models revolutionized AI🚀 Language: One tokenizer for everything Vision: Fragmented across modalities & tasks Introducing AToken: The first unified visual tokenizer for images, videos & 3D that does BOTH reconstruction AND…

🎉 Excited to share RecA: Reconstruction Alignment Improves Unified Multimodal Models 🔥 Post-train w/ RecA: 8k images & 4 hours (8 GPUs) → SOTA UMMs: GenEval 0.73→0.90 | DPGBench 80.93→88.15 | ImgEdit 3.38→3.75 Code: github.com/HorizonWind200… 1/n

VLM struggles badly to interpret 3D from 2D observations, but what if it has a good mental model about the world? Checkout our MindJourney - A test-time scaling for spatial reasoning in 3D world. Without any specific training, MindJourney imagines (acts mentally) step-by-step…

Test-time scaling nailed code & math—next stop: the real 3D world. 🌍 MindJourney pairs any VLM with a video-diffusion World Model, letting it explore an imagined scene before answering. One frame becomes a tour—and the tour leads to new SOTA in spatial reasoning. 🚀 🧵1/

VLMs often struggle with physical reasoning tasks such as spatial reasoning. Excited to share how we can use world models + test-time search to zero-shot improve spatial reasoning in VLMs!

Wow, this is so cool! Have been dreaming of building agents that can interact with humans via language communications, and the world via physical interaction (locomotion, manipulation, etc). Definitely a great step-stone and playground!
World Simulator, reimagined — now alive with humans, robots, and their vibrant society unfolding in 3D real-world geospatial scenes across the globe! 🚀 One day soon, humans and robots will co-exist in the same world. To prepare, we must address: 1️⃣ How can robots cooperate or…
check our poster at 240 on exhibition hall D at 10:30 today!
(1/10) 🔥Thrilled to introduce OneDiffusion—our latest work in unified diffusion modeling! 🚀 This model bridges the gap between image synthesis and understanding, excelling in a wide range of tasks: T2I, conditional generation, image understanding, identity preservation,…
Our afternoon session is about to start very soon with Prof. @RanjayKrishna at Room 101B!
🔥@CVPR2025 CVinW 2025 is about to take place very soon!! We have a plenty of great talks and spotlight talks upcoming (@BoqingGo, @RanjayKrishna @furongh @YunzhuLiYZ @sainingxie @CordeliaSchmid, Shizhe Chen). Look forward to seeing you all at 101B from 9am-5pm, June 11th!…


🔥@CVPR2025 CVinW 2025 is about to take place very soon!! We have a plenty of great talks and spotlight talks upcoming (@BoqingGo, @RanjayKrishna @furongh @YunzhuLiYZ @sainingxie @CordeliaSchmid, Shizhe Chen). Look forward to seeing you all at 101B from 9am-5pm, June 11th!…
🚀 Excited to announce our 4th Workshop on Computer Vision in the Wild (CVinW) at @CVPR 2025! 🔗 computer-vision-in-the-wild.github.io/cvpr-2025/ ⭐We have invinted a great lineup of speakers: Prof. Kaiming He, Prof. @BoqingGo, Prof. @CordeliaSchmid, Prof. @RanjayKrishna, Prof. @sainingxie, Prof.…


Excited to speak at the Workshop on Computer Vision in the Wild @CVPR 2025! 🎥🌍 🗓️ June 11 | 📍 Room 101 B, Music City Center, Nashville, TN 🎸 🧠 Talk: From Perception to Action: Building World Models for Generalist Agents Let’s connect if you're around! #CVPR2025 #robotics…





Our community-led Computer Vision group is thrilled to host @jw2yang4ai, Principal Researcher at Microsoft Research for a session on "Magma: A Foundation Model for Multimodal AI Agents" Thanks to @cataluna84 and @Arkhymadhe for organizing this speaker session 👏

Hope you all had a great #NeurIPS2025 submissions and have a good rest! We are still open to submissions to our CVinW workshop at @CVPR! Welcome to share your work on our workshop with a few clicks! 👉Submit Portal: openreview.net/group?id=thecv…
🚀 Excited to announce our 4th Workshop on Computer Vision in the Wild (CVinW) at @CVPR 2025! 🔗 computer-vision-in-the-wild.github.io/cvpr-2025/ ⭐We have invinted a great lineup of speakers: Prof. Kaiming He, Prof. @BoqingGo, Prof. @CordeliaSchmid, Prof. @RanjayKrishna, Prof. @sainingxie, Prof.…

The latest episode of the Derby Mill Podcast is just out and focused on the "Era of Experience" paper by David Silver and myself. Substack: insights.intrepidgp.com/p/welcome-to-t… Spotify: open.spotify.com/episode/254sxl… Apple: podcasts.apple.com/us/podcast/wel… YouTube: youtube.com/watch?v=dhfJfQ…

youtube.com
YouTube
#10 - Welcome to the Era of Experience

Introducing Phi-4-reasoning, adding reasoning models to the Phi family of SLMs. The model is trained with both supervised finetuning (using a carefully curated dataset of reasoning demonstration) and Reinforcement Learning. 📌Competitive results on reasoning benchmarks with…


We only need ONE example for RLVR on LLMs to achieve significant improvement on math tasks! 📍RLVR with one training example can boost: - Qwen2.5-Math-1.5B: 36.0% → 73.6% - Qwen2.5-Math-7B: 51.0% → 79.2% on MATH500. 📄 Paper: arxiv.org/abs/2504.20571…


























































































































United States الاتجاهات
- 1. Baker 35.7K posts
- 2. Packers 32.3K posts
- 3. 49ers 33.8K posts
- 4. #BNBdip N/A
- 5. Bucs 11.4K posts
- 6. Flacco 12.3K posts
- 7. Cowboys 74.2K posts
- 8. Fred Warner 11.3K posts
- 9. Niners 5,539 posts
- 10. Cam Ward 2,966 posts
- 11. Zac Taylor 3,196 posts
- 12. Panthers 75.6K posts
- 13. #FTTB 4,382 posts
- 14. #GoPackGo 4,114 posts
- 15. Titans 24.2K posts
- 16. Mac Jones 5,937 posts
- 17. Tez Johnson 3,322 posts
- 18. #Bengals 3,274 posts
- 19. Browns 66.6K posts
- 20. #TNABoundForGlory 7,511 posts
قد يعجبك
-
 Yin Cui
Yin Cui
@YinCuiCV -
 Wenhu Chen
Wenhu Chen
@WenhuChen -
 Linjie (Lindsey) Li
Linjie (Lindsey) Li
@LINJIEFUN -
 Yuandong Tian
Yuandong Tian
@tydsh -
 Judy Hoffman
Judy Hoffman
@judyfhoffman -
 Yining Hong
Yining Hong
@yining_hong -
 Zhenjun Zhao
Zhenjun Zhao
@zhenjun_zhao -
 Yuke Zhu
Yuke Zhu
@yukez -
 Jingkang (Jake) Yang
Jingkang (Jake) Yang
@JingkangY -
 Kate Saenko
Kate Saenko
@kate_saenko_ -
 Elliott / Shangzhe Wu
Elliott / Shangzhe Wu
@elliottszwu -
 Ziwei Liu
Ziwei Liu
@liuziwei7 -
 Xiaolong Wang
Xiaolong Wang
@xiaolonw -
 Bolei Zhou
Bolei Zhou
@zhoubolei -
 Chunyuan Li
Chunyuan Li
@ChunyuanLi
Something went wrong.
Something went wrong.