#deeplearningneuralnetwork 검색 결과

🚨 This paper might be the bridge between logic and intelligence. It’s called Tensor Logic, and it turns logical reasoning into pure tensor algebra no symbols, no heuristics, just math. Here’s the wild part: Logical propositions become vectors. Inference rules become tensor…


Am I wrong in sensing a paradigm shift in AI? Feels like we’re moving from a world obsessed with generalist LLM APIs to one where more and more companies are training, optimizing, and running their own models built on open source (especially smaller, specialized ones) Some…


You can now train models up to 200B parameters locally on NVIDIA DGX Spark with Unsloth! 🦥 Fine-tune, RL & deploy OpenAI gpt-oss-120b via our free notebook in 68GB unified memory: colab.research.google.com/github/unsloth… Read our step-by-step guide in collab with NVIDIA docs.unsloth.ai/new/fine-tunin…


Say hello to DINOv3 🦖🦖🦖 A major release that raises the bar of self-supervised vision foundation models. With stunning high-resolution dense features, it’s a game-changer for vision tasks! We scaled model size and training data, but here's what makes it special 👇





If you want to learn Deep Learning from the ground up to advanced techniques, this open resource is a gem. Full notebook suite -> Link in comments


The attached picture is the simplest explanation of Machine Learning I've seen. In the regular world of writing code to solve problems, programmers write rules and apply them to data to produce the answers they need. Sometimes, writing those rules is really difficult. For…


three years ago, DiT replaced the legacy unet with a transformer-based denoising backbone. we knew the bulky VAEs would be the next to go -- we just waited until we could do it right. today, we introduce Representation Autoencoders (RAE). >> Retire VAEs. Use RAEs. 👇(1/n)


Introducing DINOv3 🦕🦕🦕 A SotA-enabling vision foundation model, trained with pure self-supervised learning (SSL) at scale. High quality dense features, combining unprecedented semantic and geometric scene understanding. Three reasons why this matters…


I'm excited to announce @inference_net's $11.8M Series Seed funding round, led by @multicoincap & @a16zcrypto CSX, with participation from @topology_vc, @fdotinc, and an incredible group of angels. The next wave of AI adoption will be driven by companies building AI natively…


implemented an LSTM RNN with a Mixture Density Network head on top (MDN-RNN) for future states prediction as a probability for next state (an image) given past hidden states, past latent vector, and an action vector. tomorrow we implement the training script (half done), and…


We’re joining the race. ⚫️ Ever wonder why AI sometimes gives half-baked answers or misses the point? It’s not the model’s fault, it’s running low on good data. Experts say AI is hitting a wall. The internet’s been scraped dry, and without fresh, verified data, progress slows…

The size & complexity of AI models keeps growing at an exponential rate, making it challenging for academic researchers to remain at the forefront. Alexnet -- the famous U Toronto AI model that launched Deep Learning into the mainstream in 2012 -- is tiny by today's standards.


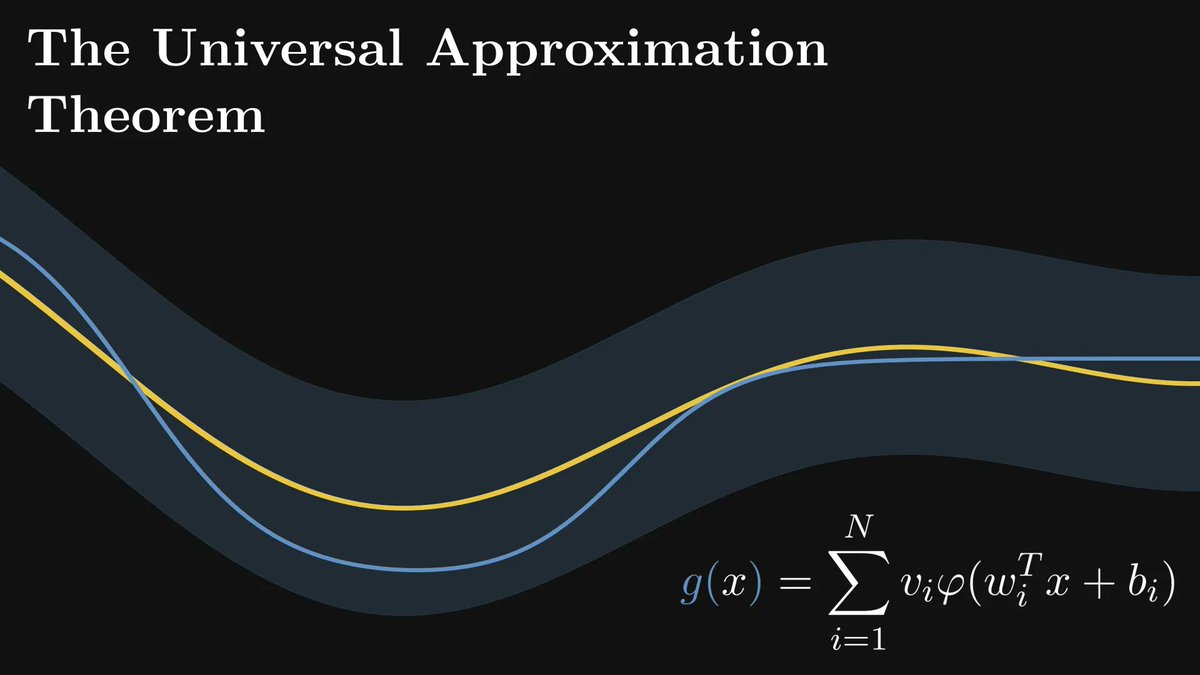
Neural networks are stunningly powerful. This is old news: deep learning is state-of-the-art in many fields, like computer vision and natural language processing. (But not everywhere.) Why are neural networks so effective? I'll explain:

Harnessing #MachineLearning for Advanced A/V Analysis and Detection buff.ly/vIj8X8K v/ @_odsc #AI #DataScience Cc @DeepLearn007 @sandy_carter @KirkDBorne @jblefevre60 @jeancayeux


Experimenting with model fine-tuning today. Every tweak teaches something new. Love this phase where ideas turn into intelligence. ⚡ #AI #DeepLearning

Holy shit...NVIDIA just trained a 12B-parameter LLM on 10 trillion tokens entirely in 4-bit precision. It’s called NVFP4, and it matches FP8 accuracy while slashing compute and memory in half. That’s not an incremental gain that’s a new era of efficient model training. Key…


#highlycitedpaper Deep Learning Automated Segmentation for Muscle and Adipose Tissue from Abdominal Computed Tomography in Polytrauma Patients mdpi.com/1424-8220/21/6… #sarcopenia #deeplearningneuralnetwork #automatedsegmentation #computedtomography

#highlycitedpaper Deep Learning Automated Segmentation for Muscle and Adipose Tissue from Abdominal Computed Tomography in Polytrauma Patients mdpi.com/1424-8220/21/6… #sarcopenia #deeplearningneuralnetwork #automatedsegmentation #computedtomography
Novel Ensemble Approach of #DeepLearningNeuralNetwork (#DLNN) Model and #ParticleSwarmOptimization (#PSO) Algorithm for Prediction of #GullyErosionSusceptibility @UniDuyTan @bauhaus_uni 👉mdpi.com/1424-8220/20/1… #erosion #hazardmap #naturalhazard #spatialmodel #RemoteSensing

Something went wrong.
Something went wrong.
United States Trends
- 1. #TORQSports N/A
- 2. Russ 18.7K posts
- 3. Argentina 471K posts
- 4. Waddle 3,745 posts
- 5. Malcolm Brogdon 1,332 posts
- 6. Rickey 2,368 posts
- 7. Big Balls 24.8K posts
- 8. $HIMS 4,264 posts
- 9. Olave 3,183 posts
- 10. #BeyondTheGates 5,456 posts
- 11. Aphrodite 4,993 posts
- 12. #ClockTower1Year N/A
- 13. Kings 159K posts
- 14. Voting Rights Act 29.6K posts
- 15. Maybe in California N/A
- 16. #TrumpsShutdownDragsOn 7,273 posts
- 17. Capitol Police 28.1K posts
- 18. Jakobi Meyers 1,252 posts
- 19. annabeth 2,630 posts
- 20. Justice Jackson 21.3K posts