#deeplearningresearchers 搜尋結果

We are looking for several #DeepLearningResearchers capable of taking the lead on researching and delivering new wide-ranging methods in #MachineLearning . For more information: buff.ly/2YgQGuO #MachineLearningResearch #DeepLearning #AI #ArtificialIntelligence


RT @AndyAtLogikk: RT @WeAreLogikk: We are looking for several #DeepLearningResearchers capable of taking the lead on researching and delivering new wide-ranging methods in #MachineLearning . For more information: buff.ly/2YgQGuO #MachineLearni…

Organized Resources for Deep Learning Researchers and Developers github.com/astorfi/Deep-L… #OrganizedResources #DeepLearningResearchers #Developers
RT @AndyAtLogikk: RT @WeAreLogikk: We are looking for several #DeepLearningResearchers capable of taking the lead on researching and delivering new wide-ranging methods in #MachineLearning . For more information: buff.ly/2YgQGuO #MachineLearni…
We are looking for several #DeepLearningResearchers capable of taking the lead on researching and delivering new wide-ranging methods in #MachineLearning . For more information: buff.ly/2YgQGuO #MachineLearningResearch #DeepLearning #AI #ArtificialIntelligence
Organized Resources for Deep Learning Researchers and Developers github.com/astorfi/Deep-L… #OrganizedResources #DeepLearningResearchers #Developers

Practical #MachineLearning for #ComputerVision — End-to-End ML for Images: amzn.to/4ajfVSf ———— #BigData #DataScience #AI #DeepLearning #NeuralNetworks




2026 no servirá Buscar en Google. Investigadores usan IA y Prompts para Investigación Profunda. Reuní los 4 mejores: –Educación –Psicología digital –Política pública -Ciencia aplicada No Resúmenes, llegarás a las Fuentes. Sígueme, Comparte (RT) y Guarda: Todos la necesitarán⬇️


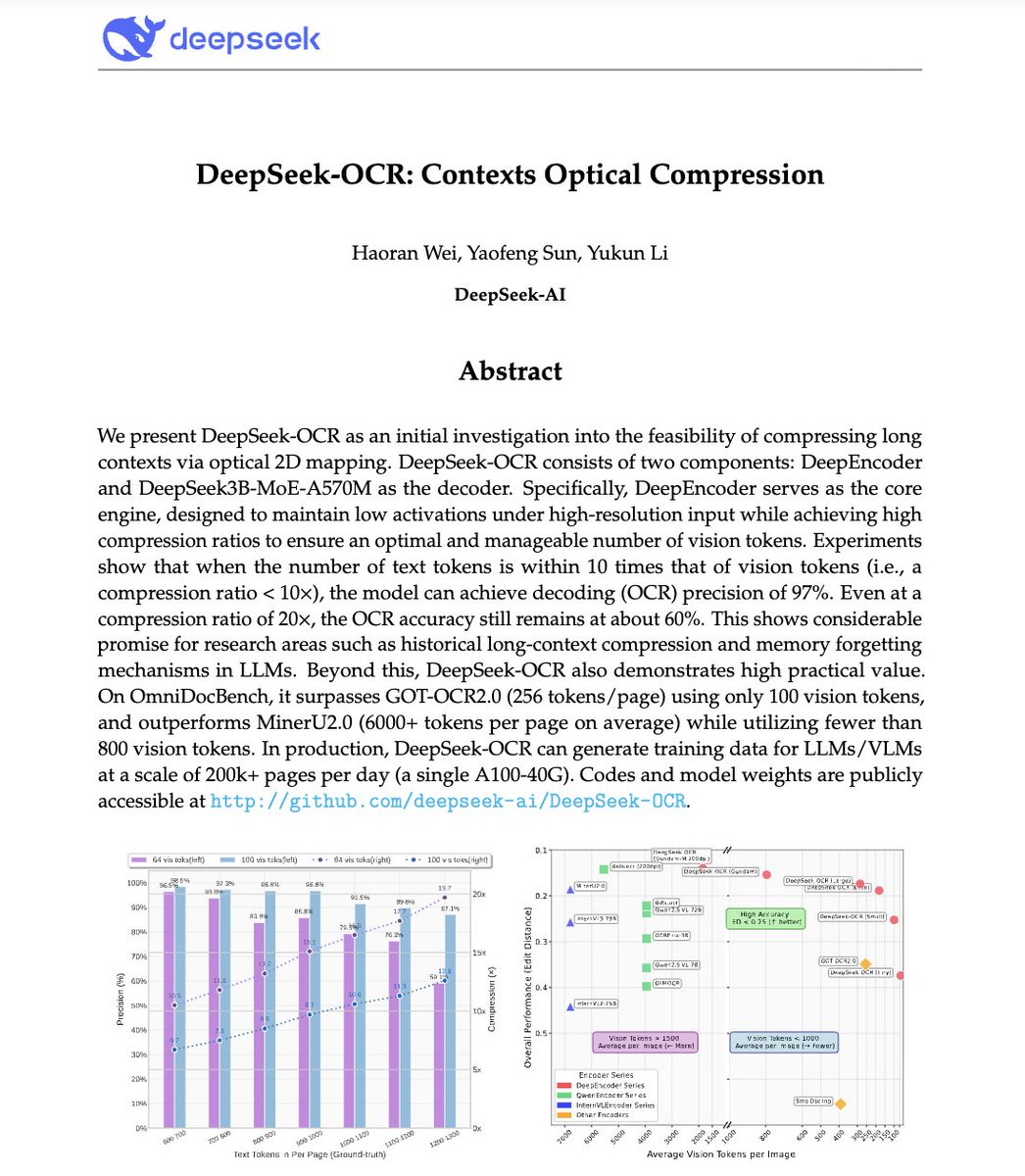
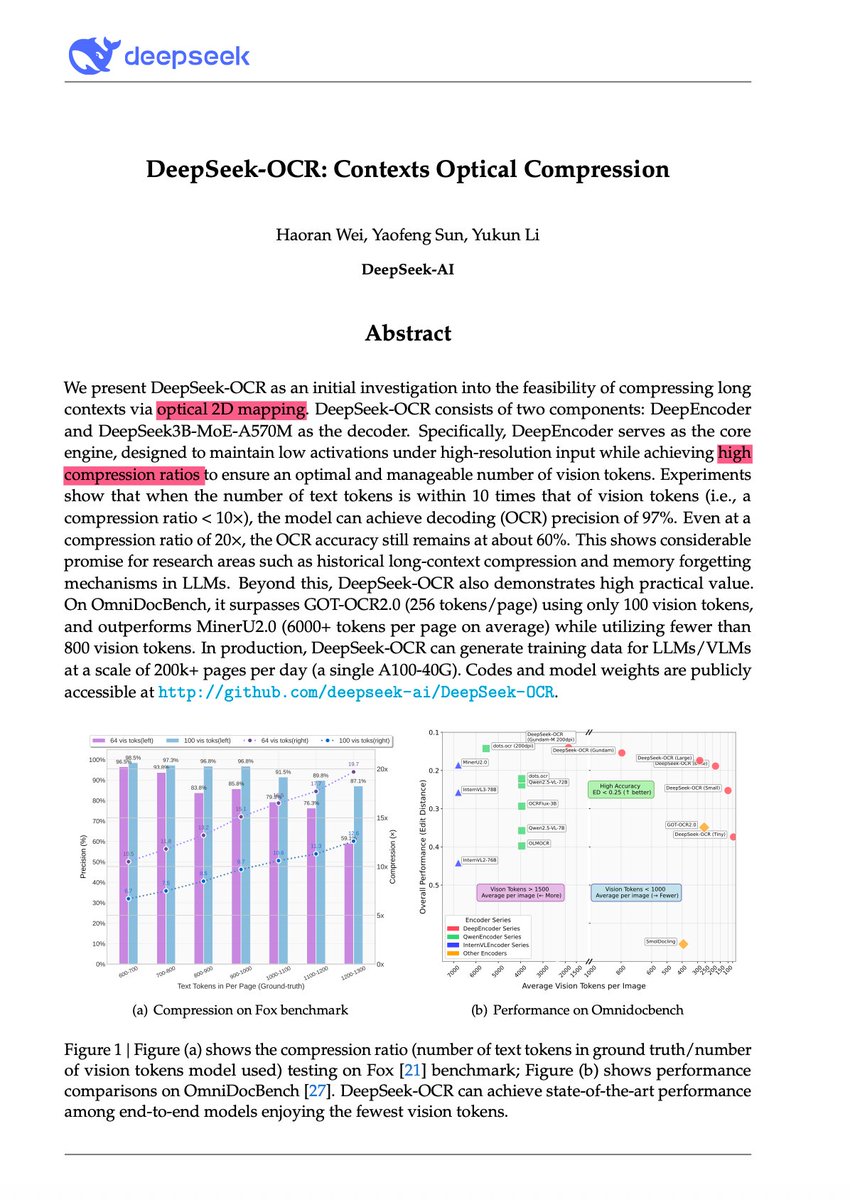
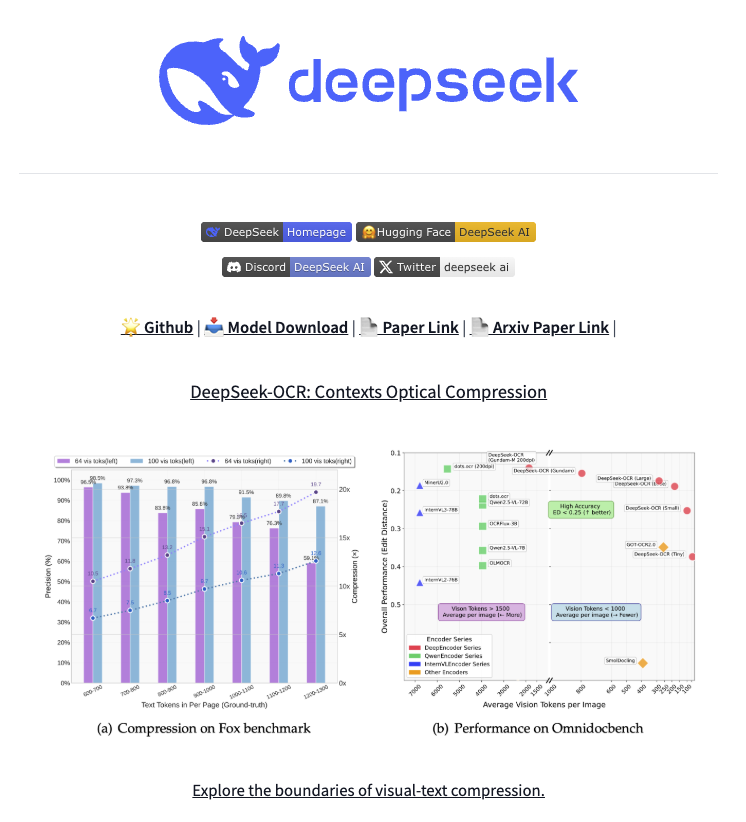
🚀 DeepSeek-OCR — the new frontier of OCR from @deepseek_ai , exploring optical context compression for LLMs, is running blazingly fast on vLLM ⚡ (~2500 tokens/s on A100-40G) — powered by vllm==0.8.5 for day-0 model support. 🧠 Compresses visual contexts up to 20× while keeping…




This is the JPEG moment for AI. Optical compression doesn't just make context cheaper. It makes AI memory architectures viable. Training data bottlenecks? Solved. - 200k pages/day on ONE GPU - 33M pages/day on 20 nodes - Every multimodal model is data-constrained. Not anymore.…


🚨 DeepSeek just did something wild. They built an OCR system that compresses long text into vision tokens literally turning paragraphs into pixels. Their model, DeepSeek-OCR, achieves 97% decoding precision at 10× compression and still manages 60% accuracy even at 20×. That…

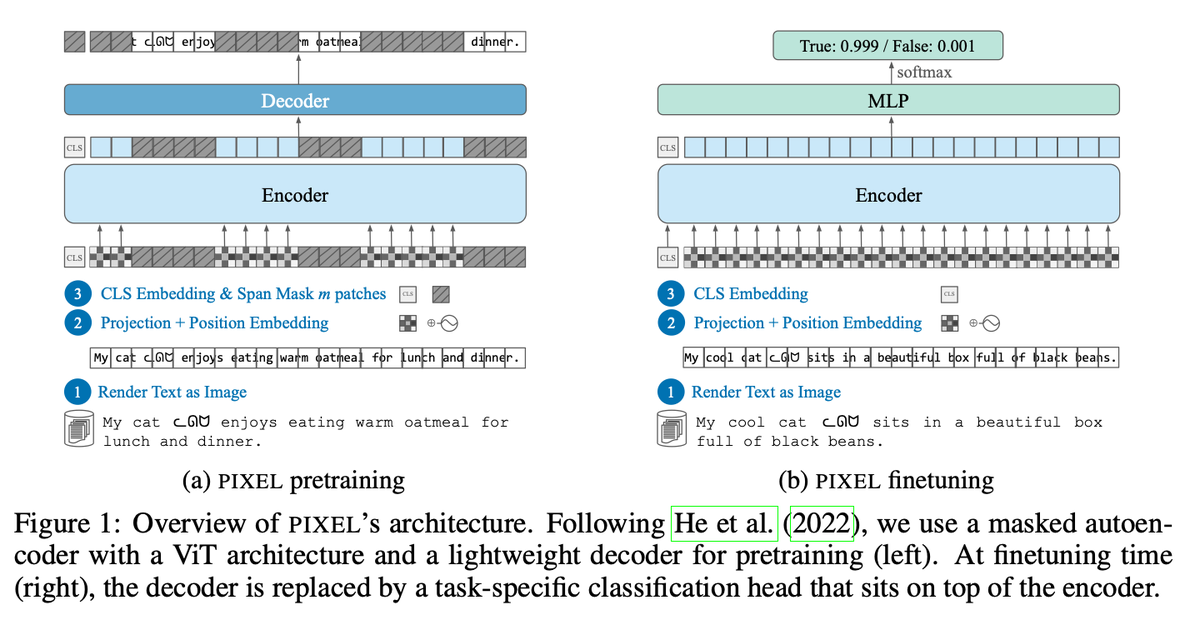
DeepSeek-OCR looks impressive, but its core idea is not new. Input “Text” as “Image” — already explored by: LANGUAGE MODELING WITH PIXELS (Phillip et al., ICLR 2023) CLIPPO: Image-and-Language Understanding from Pixels Only (Michael et al. CVPR 2023) Pix2Struct: Screenshot…
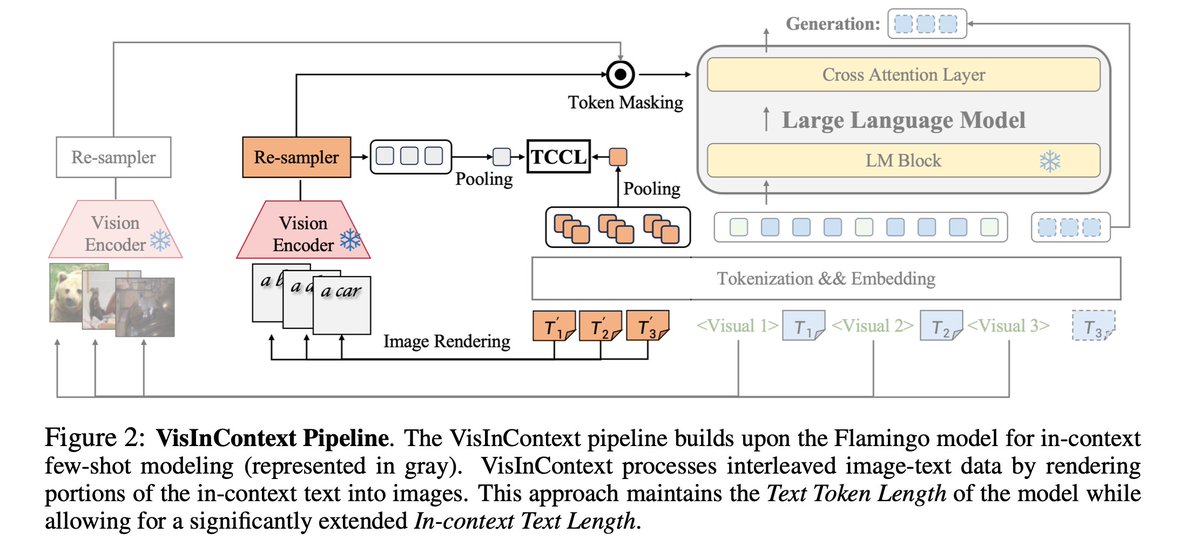
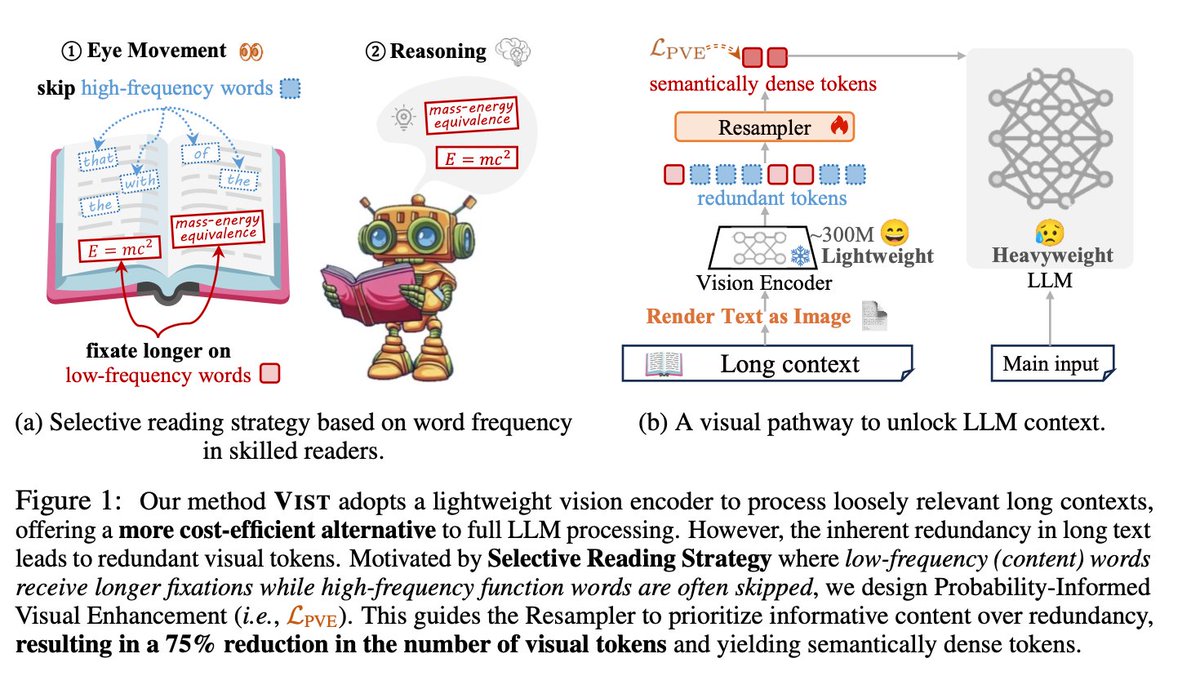



DeepSeek finally released a new model and paper. And because this DeepSeek-OCR release is a bit different from what everyone expected, and DeepSeek releases are generally a big deal, I wanted to do a brief explainer of what it is all about. In short, they explore how vision…


@gregisenberg @rauchg I made the Deepest Research Agent and presented it at Shopify. Someone took the deepestresearh domain so I used deepestagent.vercel.app :)


DeepSeek-OCR just dropped. 🔥 Sets a new standard for open-source OCR A 3B-parameter vision-language model designed for high-performance optical character recognition and structured document conversion. - Can parse and re-render charts in HTML - Optical Context Compression:…

IT FREAKING WORKED! At 4am today I just proved DeepSeek-OCR AI can scan an entire microfiche sheet and not just cells and retain 100% of the data in seconds… AND Have a full understanding of the text/complex drawings and their context. I just changed offline data curation!

BOOOOOOOM! CHINA DEEPSEEK DOES IT AGAIN! An entire encyclopedia compressed into a single, high-resolution image! — A mind-blowing breakthrough. DeepSeek-OCR, unleashed an electrifying 3-billion-parameter vision-language model that obliterates the boundaries between text and…
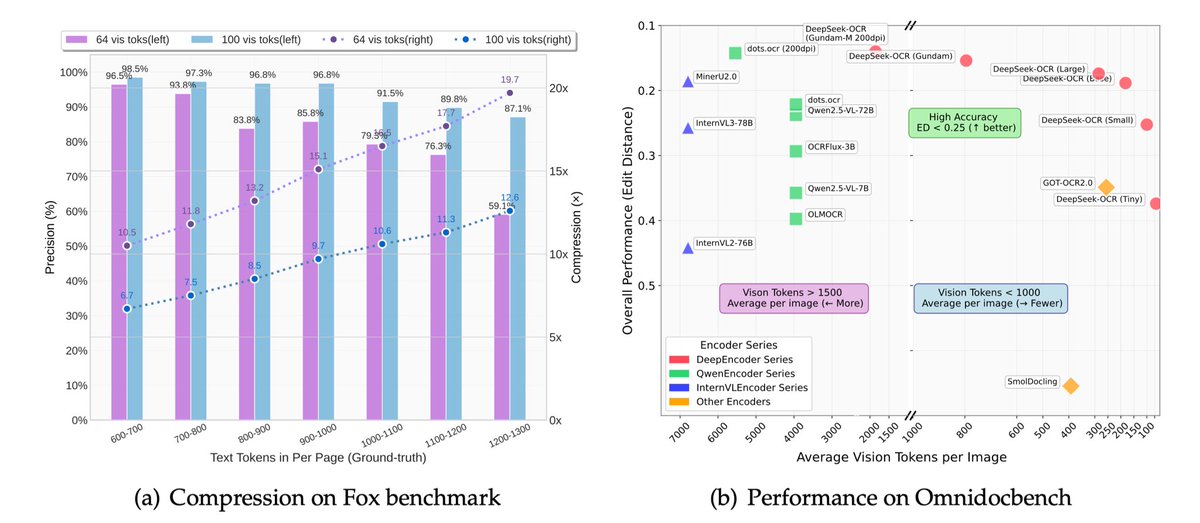

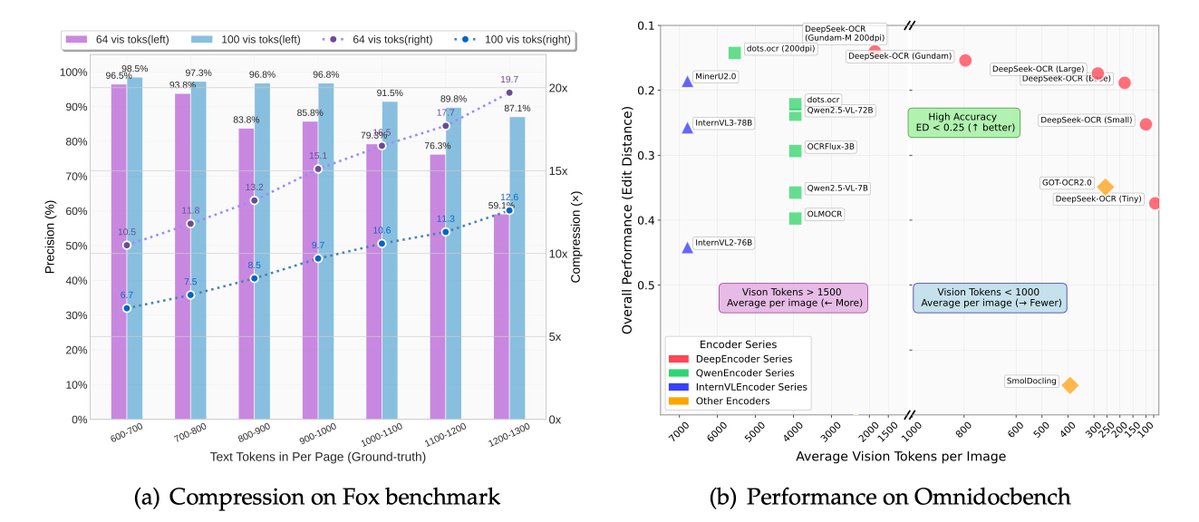
A more serious thread on the DeepSeek-OCR hype / serious misinterpretation going on. 1. On token reduction via representing text in images, researchers from Cambridge have previously shown that 500x prompt token compression is possible (ACL'25, Li, Su, and Collier). Without…

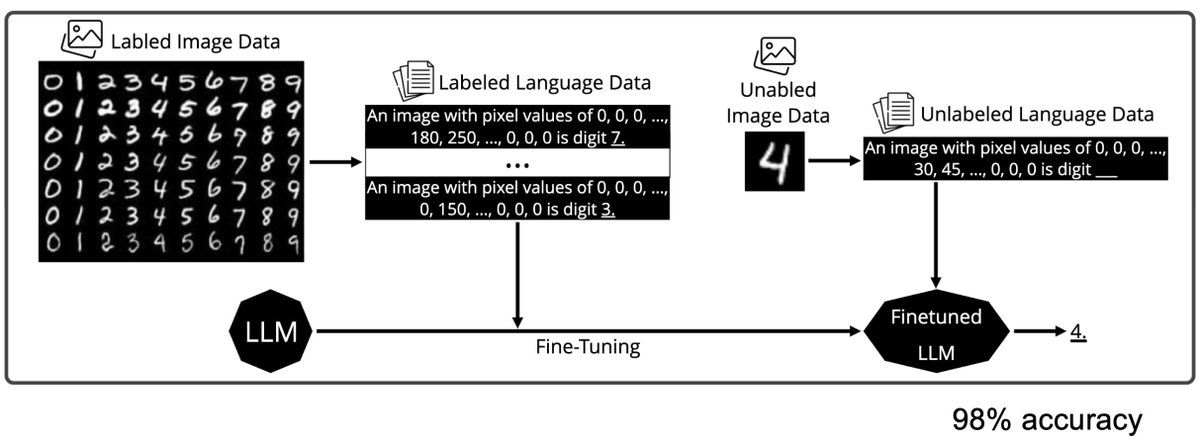
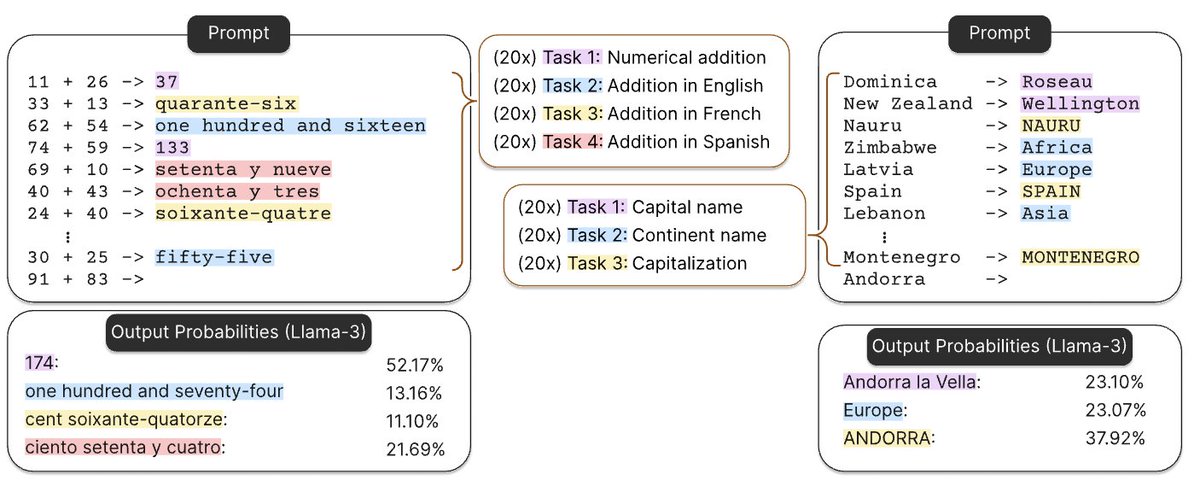




Why is DeepSeek-OCR such a BIG DEAL? Existing LLMs struggle with long inputs because they can only handle a fixed number of tokens, known as the context window, and attention cost grows quickly as inputs get longer. DeepSeek-OCR takes a new approach. Instead of sending long…
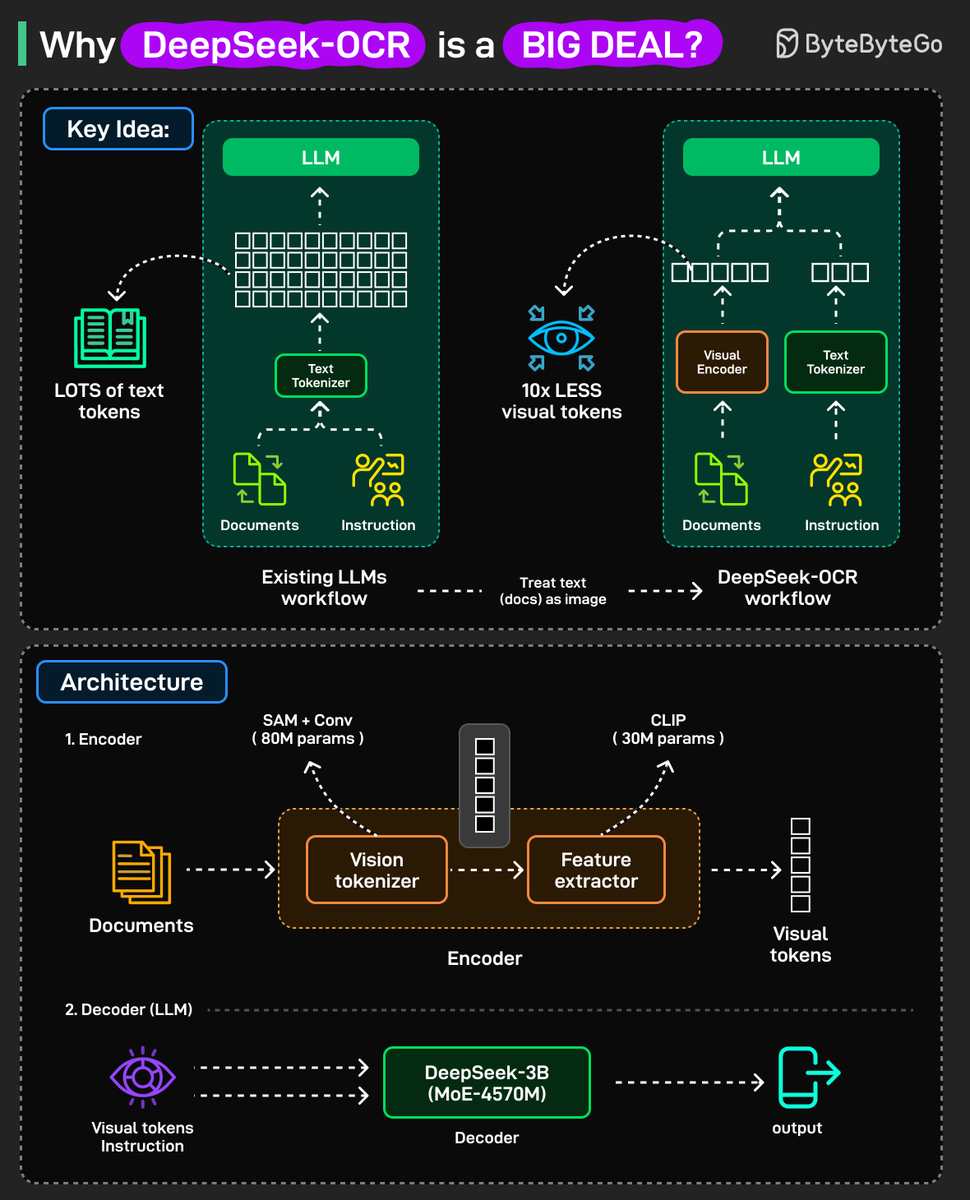
BOOOOOOOM! CHINA DEEPSEEK DOES IT AGAIN! An entire encyclopedia compressed into a single, high-resolution image! — A mind-blowing breakthrough. DeepSeek-OCR, unleashed an electrifying 3-billion-parameter vision-language model that obliterates the boundaries between text and…


The Evolving Roles for #DataScientists in the Age of Intelligent Automation: codata.org/blog/2025/10/3… #AI #DataScience #ML #MachineLearning



Something went wrong.
Something went wrong.
United States Trends
- 1. Chiefs 63K posts
- 2. Bills 133K posts
- 3. Denny 14.4K posts
- 4. Larson 14.1K posts
- 5. Mahomes 21.7K posts
- 6. Bengals 73.4K posts
- 7. Raiders 36.7K posts
- 8. Geno 8,185 posts
- 9. Brock Bowers 4,693 posts
- 10. Jags 5,800 posts
- 11. Josh Allen 12.2K posts
- 12. #NASCAR 11.4K posts
- 13. Bears 83.3K posts
- 14. Packers 67.9K posts
- 15. Panthers 56.2K posts
- 16. Cam Little 14.3K posts
- 17. Cole Bishop 2,285 posts
- 18. McDermott 2,274 posts
- 19. Byron 12K posts
- 20. #RaiderNation 2,227 posts