#deepseekcoderv2 search results

🤖deepagents: the open source, multi-model agent harness We're releasing 0.2 of deep agents, with a big addition: a "backend" abstraction This lets you swap the filesystem you use from a local filesystem to a remote VM to a database to anything blog: blog.langchain.com/doubling-down-…


DeepSeek V3.2 breakdown 1. Sparse attention via lightning indexer + top_k attention 2. Uses V3.1 Terminus + 1T continued pretraining tokens 3. 5 specialized models (coding, math etc) via RL then distillation for final ckpt 4. GRPO. Reward functions for length penalty, language…


🔥 DeepCode has been trending on GitHub for 2 consecutive days! 🚀 Almost hitting 2k GitHub Stars! 🌟 Fully Open Source: github.com/HKUDS/DeepCode ✨ All-in-One Agentic Coding Framework ✨ • 📄 Paper2Code - Research to Implementation • 🌐 Text2Web - Natural Language to Frontend…


DeepSeek is a crypto money printer 💵 I wrote a Bot, that's made me $35K from $100 last night. This isn’t clickbait—just an AI Trading Bot powered by DeepSeek. I'm sharing the exact bot for FREE 24 hour Want it? 1. RT 2. Like 3. Reply "DS" and Follow me and I'll DM you.


💻 API Update 🎉 Lower costs, same access! 💰 DeepSeek API prices drop 50%+, effective immediately. 🔹 For comparison testing, V3.1-Terminus remains available via a temporary API until Oct 15th, 2025, 15:59 (UTC Time). Details: api-docs.deepseek.com/guides/compari… 🔹 Feedback welcome:…


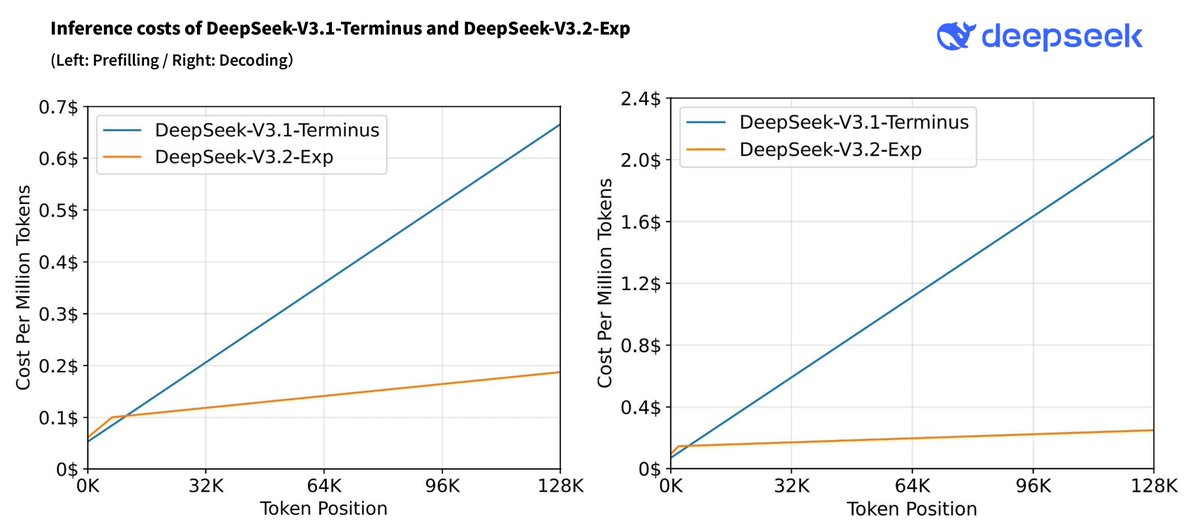
V3.2 with DeepSeek Sparse Attention gets much better efficiency⚡️.

🚀 Introducing DeepSeek-V3.2-Exp — our latest experimental model! ✨ Built on V3.1-Terminus, it debuts DeepSeek Sparse Attention(DSA) for faster, more efficient training & inference on long context. 👉 Now live on App, Web, and API. 💰 API prices cut by 50%+! 1/n

Caesar x402 support is now live. Developers and AI agents can now access the best deep research on demand, using trustless, instant pay-per-query payments powered by the x402 protocol.


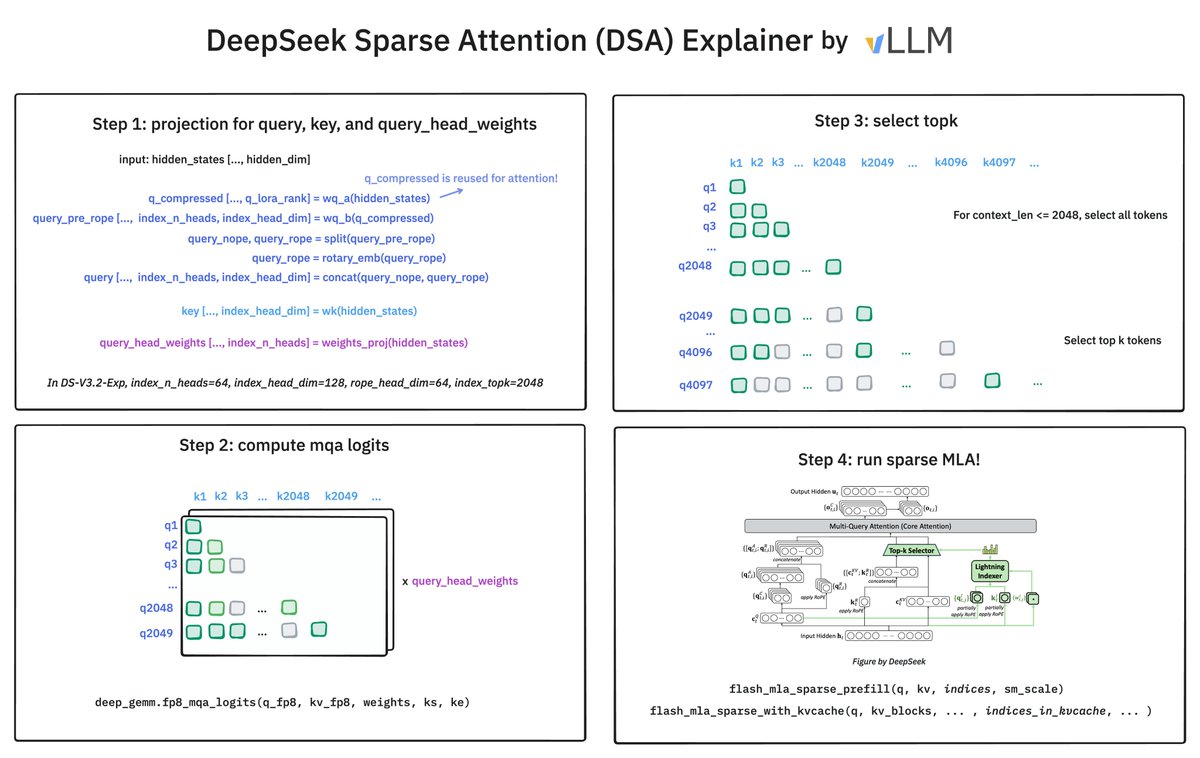
How does @deepseek_ai Sparse Attention (DSA) work? It has 2 components: the Lightning Indexer and Sparse Multi-Latent Attention (MLA). The indexer keeps a small key cache of 128 per token (vs. 512 for MLA). It scores incoming queries. The top-2048 tokens to pass to Sparse MLA.
🚀 Introducing DeepSeek-V3.2-Exp — our latest experimental model! ✨ Built on V3.1-Terminus, it debuts DeepSeek Sparse Attention(DSA) for faster, more efficient training & inference on long context. 👉 Now live on App, Web, and API. 💰 API prices cut by 50%+! 1/n
🌟 Meet #DeepSeekMoE: The Next Gen of Large Language Models! Performance Highlights: 📈 DeepSeekMoE 2B matches its 2B dense counterpart with 17.5% computation. 🚀 DeepSeekMoE 16B rivals LLaMA2 7B with 40% computation. 🛠 DeepSeekMoE 145B significantly outperforms Gshard,…

🚀 DeepCode: Open Agentic Coding is Here! We dropped DeepCode - an AI-powered coding platform that transforms research papers and technical documents into production-ready code! 🔗 Fully Open Source: github.com/HKUDS/DeepCode ✨ Current Features: • Paper2Code: Convert research…


DeepSeek V3 is a popular Large-Language Model that's a good one to know if you're interested in AI. And in this course, you'll learn how it works. It covers DeepSeek's Multi-Head Latent Attention mechanism, Mixture of Experts architecture, and lots more.…


Official release of DeepSeek-V3.2-Exp with DeepSeek Sparse Attention + massive price cuts! DeepSeek Sparse Attention (DSA) makes inference cheaper (especially long-context) by learning which past tokens matter for each new token and running full attention only on those. DSA…



🚀 Introducing DeepSeek-V3.2-Exp — our latest experimental model! ✨ Built on V3.1-Terminus, it debuts DeepSeek Sparse Attention(DSA) for faster, more efficient training & inference on long context. 👉 Now live on App, Web, and API. 💰 API prices cut by 50%+! 1/n

DeepSeek needed better productivity features, so I built a Chrome extension for it. Would love any early feedback to help me launch it! 😊


Fiction.LiveBench for Long Context Deep Comprehension adds: deepseek-v3.2-exp [reasoning: high], deepseek-v3.2-exp, nemotron-nano-9b-v2:free, qwen-max, qwen3-next-80b-a3b-instruct.
![ficlive's tweet image. Fiction.LiveBench for Long Context Deep Comprehension adds: deepseek-v3.2-exp [reasoning: high], deepseek-v3.2-exp, nemotron-nano-9b-v2:free, qwen-max, qwen3-next-80b-a3b-instruct.](https://pbs.twimg.com/media/G2BsE2CWoAIAxI5.jpg)

Command: python -m sglang.launch_server --model deepseek-ai/DeepSeek-V3.2-Exp --tp 8 --ep 8 --dp 8 --enable-dp-attention --speculative-algorithm EAGLE --speculative-num-steps 3 --speculative-eagle-topk 1 --speculative-num-draft-tokens 4 Pull request: github.com/sgl-project/sg… More…

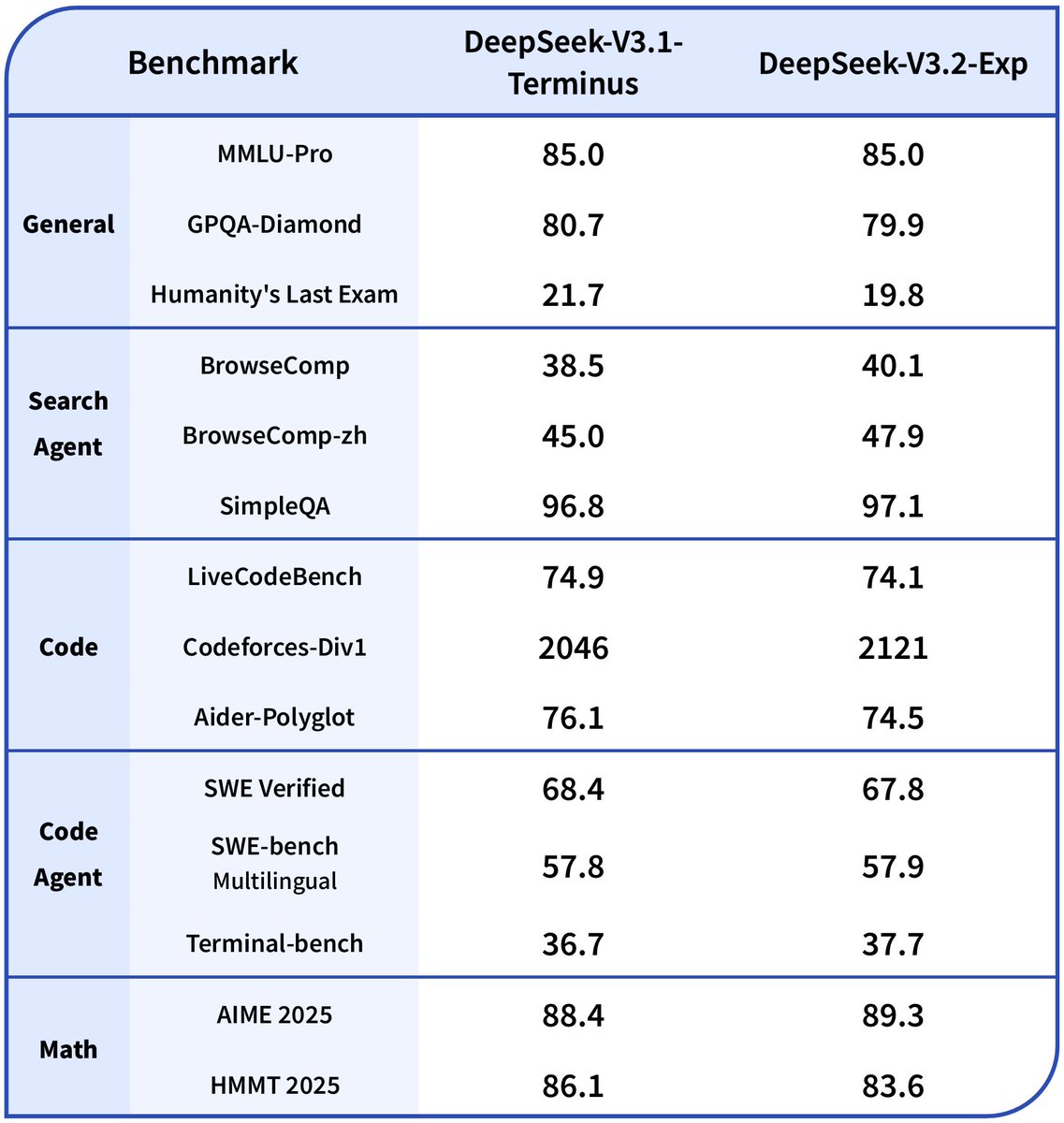
⚡️ Efficiency Gains 🤖 DSA achieves fine-grained sparse attention with minimal impact on output quality — boosting long-context performance & reducing compute cost. 📊 Benchmarks show V3.2-Exp performs on par with V3.1-Terminus. 2/n

DeepSeek-Coder-V2: Open-source model beats GPT-4 and Claude Opus #DeepSeekCoderV2 #LLM #GPT4 the-decoder.com/deepseek-coder…
the-decoder.com
DeepSeek-Coder-V2: Open-source model beats GPT-4 and Claude Opus
The academic research collective DeepSeek-AI has released the open-source language model DeepSeek-Coder-V2. It aims to compete with leading commercial models like GPT-4, Claude, or Gemini in code...

Chinese AI startup DeepSeek launches DeepSeek Coder V2, an open-source marvel supporting 300+ programming languages. It outperforms top closed-source models like GPT-4 Turbo, Claude 3 Opus, and Gemini 2.5 Pro. #AI #OpenSource #DeepSeekCoderV2 #Programming

DeepSeek Coder 2 が GPT4-Turbo オープンソース コーディング モデルに勝利 - Geeky Gadgets #DeepSeekCoderV2 #AIcoding #OpenSourceModel #SoftwareEngineering prompthub.info/18007/

Something went wrong.
Something went wrong.
United States Trends
- 1. #AEWDynamite 13.9K posts
- 2. JUNGWOO 23.5K posts
- 3. #Survivor49 2,685 posts
- 4. Donovan Mitchell 4,613 posts
- 5. doyoung 26.2K posts
- 6. Snell 10.6K posts
- 7. Cavs 7,930 posts
- 8. Kacie N/A
- 9. #SistasOnBET 1,001 posts
- 10. Yesavage 5,882 posts
- 11. #LoveIsBlindReunion N/A
- 12. Mobley 1,862 posts
- 13. Josh Minott N/A
- 14. #AbbottElementary 1,419 posts
- 15. Okada 4,083 posts
- 16. Jaylen Brown 7,096 posts
- 17. Trae Young 2,295 posts
- 18. Blood and Guts N/A
- 19. Davis Schneider 5,372 posts
- 20. Game 5 58K posts